

Wprowadzenie do Map Join in Hive
Łączenie map to funkcja używana w zapytaniach Hive w celu zwiększenia wydajności pod względem szybkości. Łączenie jest warunkiem stosowanym do łączenia danych z 2 tabel. Kiedy wykonujemy normalne połączenie, zadanie jest wysyłane do zadania Zmniejsz mapę, które dzieli główne zadanie na 2 etapy - „Etap mapy” i „Etap zmniejszenia”. Etap mapy interpretuje dane wejściowe i zwraca dane wyjściowe do etapu redukcji w postaci par klucz-wartość. Następnie przechodzi etap losowania, w którym są one sortowane i łączone. Reduktor przyjmuje tę posortowaną wartość i kończy zadanie łączenia.
Tabelę można załadować do pamięci całkowicie w programie mapującym i bez konieczności korzystania z procesu Map / Reducer. Odczytuje dane z mniejszej tabeli i zapisuje je w tablicy mieszającej w pamięci, a następnie serializuje do pliku pamięci mieszającej, co znacznie skraca czas. Jest również znany jako Map Side Join in Hive. Zasadniczo polega na wykonywaniu połączeń między 2 tabelami przy użyciu tylko fazy mapy i pomijania fazy zmniejszania. Zmniejszenie czasu obliczania zapytań można zaobserwować, jeśli regularnie używają one małych połączeń tabel.
Składnia dla Map Join in Hive
Jeśli chcemy wykonać zapytanie o przyłączenie przy użyciu map-join, musimy określić słowo kluczowe „/ * + MAPJOIN (b) * /” w poniższej instrukcji:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
W tym przykładzie musimy utworzyć 2 tabele o nazwach tablename1 i tablename2 posiadających 2 kolumny: emp_id i emp_name. Jeden plik powinien być większy, a drugi mniejszy.
Przed uruchomieniem zapytania musimy ustawić poniższą właściwość na true:
hive.auto.convert.join=true
Zapytanie o połączenie dla mapowania jest napisane jak wyżej, a otrzymujemy wynik:
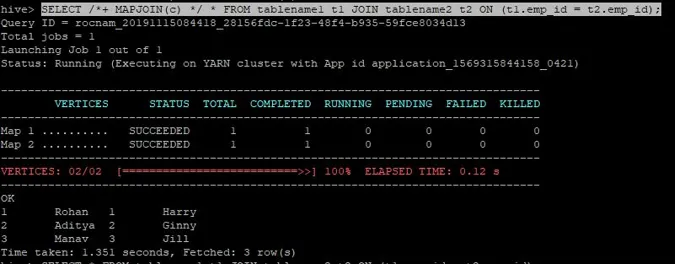
Zapytanie zostało ukończone w 1.351 sekund.
Przykłady przyłączenia mapy w ulu
Oto następujące przykłady wymienione poniżej
1. Przykład przyłączenia do mapy
W tym przykładzie stwórzmy 2 tabele o nazwach table1 i table2 odpowiednio z 100 i 200 rekordami. Możesz odwołać się do poniższego polecenia i zrzutów ekranu w celu wykonania tego samego:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Teraz ładujemy rekordy do obu tabel za pomocą poniższych poleceń:
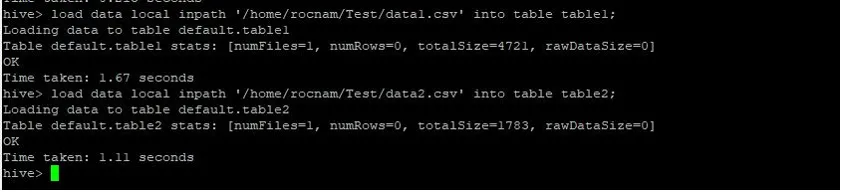
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Wykonajmy normalne zapytanie dotyczące połączenia map na ich identyfikatorach, jak pokazano poniżej i sprawdź czas potrzebny na to samo:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
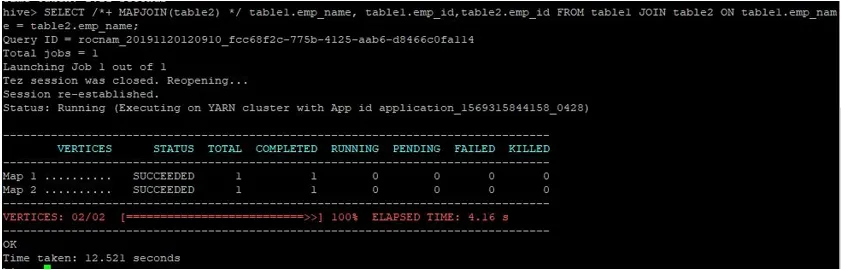
Jak widzimy, normalne zapytanie o przyłączenie do mapy zajęło 12.521 sekund.
2. Przykład łączenia mapy kubełkowej
Użyjmy teraz połączenia Bucket-map, aby uruchomić to samo. Istnieje kilka ograniczeń, których należy przestrzegać przy segregowaniu:
- Wiadra można łączyć ze sobą tylko wtedy, gdy łączna liczba wiader w jednym stole jest wielokrotnością liczby wiader w drugim stole.
- Musi mieć tabele z zestawem, aby wykonać segmentowanie. Stąd stwórzmy to samo.
Poniżej przedstawiono polecenia używane do tworzenia tabel z tabelami w tabeli 1 i 2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Do tych tabel zbiorczych wstawimy te same rekordy z tabeli 1:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
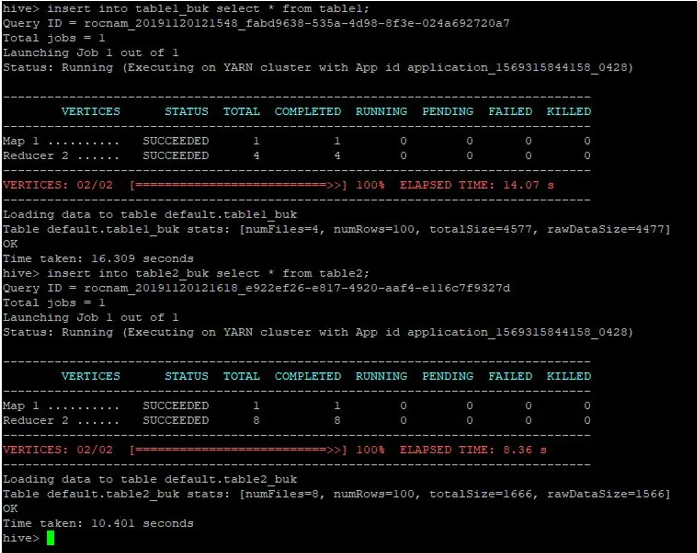
Teraz, gdy mamy już dwa tabele z zestawem, wykonajmy na nich połączenie mapowania. Pierwszy stół ma 4 wiadra, podczas gdy drugi stół ma 8 wiader utworzonych w tej samej kolumnie.
Aby zapytanie łączenia mapowania działało, w gałęzi powinniśmy ustawić następującą właściwość na true:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
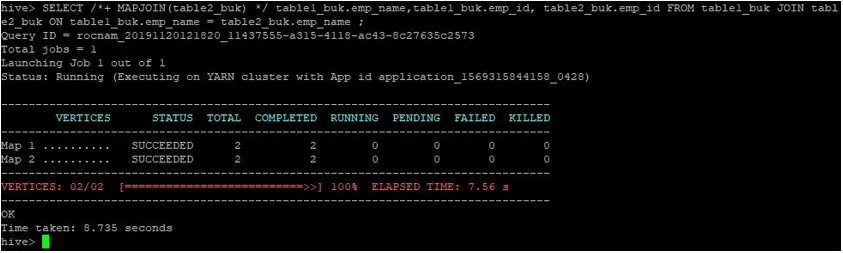
Jak widać, zapytanie zostało ukończone w 8, 735 sekund, co jest szybsze niż normalne dołączenie mapy.
3. Przykład sortowania mapy łączenia segmentu łączenia (SMB)
SMB można wykonać na tabelach z segmentami o tej samej liczbie segmentów i jeśli tabele należy sortować i segmentować na kolumnach łączenia. Poziom programu mapującego odpowiednio łączy te segmenty.
Tak samo, jak w przypadku łączenia mapy z wiadrem, istnieją 4 segmenty dla tabeli 1 i 8 segmentów dla tabeli 2. W tym przykładzie utworzymy inny stół z 4 segmentami.
Aby uruchomić zapytanie SMB, musimy ustawić następujące właściwości gałęzi, jak pokazano poniżej:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Aby wykonać połączenie SMB, należy posortować dane zgodnie z kolumnami łączenia. Dlatego nadpisujemy dane w tabeli 1 zbiorczo, jak poniżej:
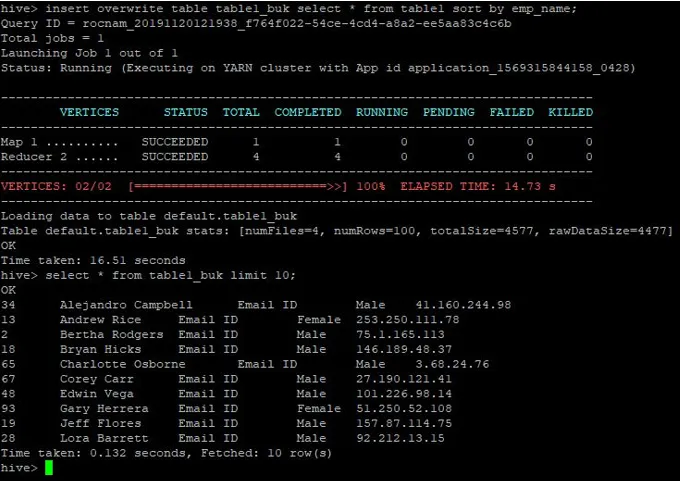
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Dane są teraz sortowane, co widać na poniższym zrzucie ekranu:
Zastąpimy również dane w tabeli zbiorczej2, jak poniżej:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Wykonajmy łączenie dla powyższych 2 tabel w następujący sposób:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
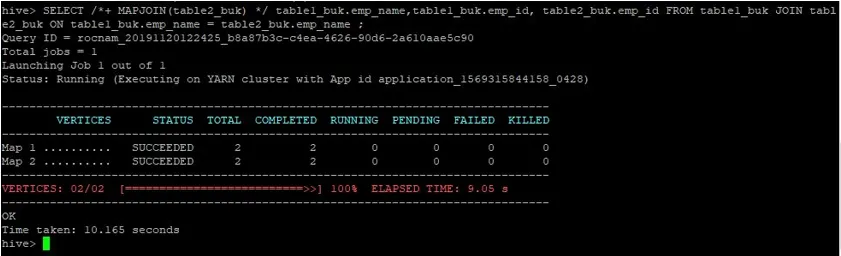
Widzimy, że zapytanie zajęło 10.165 sekund, co jest znowu lepsze niż normalne dołączenie mapy.
Utwórzmy teraz inną tabelę dla table2 z 4 segmentami i tymi samymi danymi posortowanymi według emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
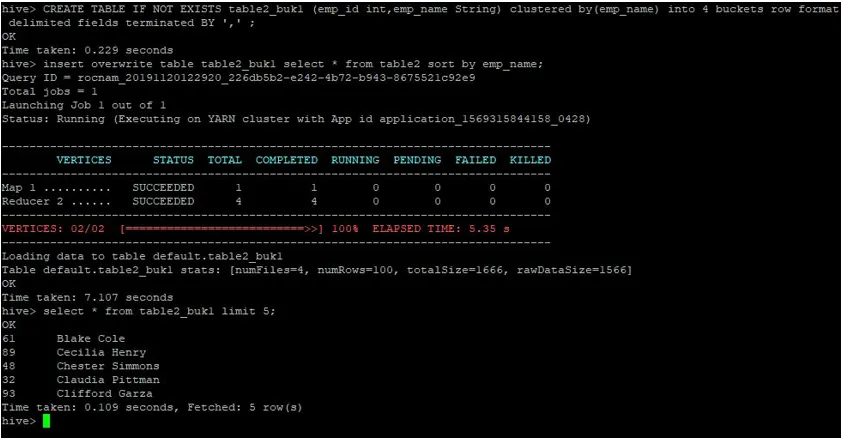
Biorąc pod uwagę, że mamy teraz obie tabele z 4 segmentami, ponownie wykonajmy kwerendę łączenia.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Zapytanie ponownie zajęło 8, 851 sekundy szybciej niż normalne zapytanie o przyłączenie do mapy.
Zalety
- Łączenie map skraca czas sortowania i scalania procesów zachodzących w tasowaniu i redukuje etapy, tym samym minimalizując również koszty.
- Zwiększa wydajność działania zadania.
Ograniczenia
- Tej samej tabeli / aliasu nie można używać do łączenia różnych kolumn w tym samym zapytaniu.
- Zapytanie o połączenie mapy nie może przekształcić pełnych połączeń zewnętrznych w sprzężenia boczne mapy.
- Łączenie mapy można wykonać tylko wtedy, gdy jedna z tabel jest wystarczająco mała, aby można ją było dopasować do pamięci. Dlatego nie można go wykonać, gdy dane w tabeli są ogromne.
- Lewe połączenie jest możliwe do przyłączenia do mapy tylko wtedy, gdy odpowiedni rozmiar stołu jest mały.
- Prawego łączenia można dokonać do połączenia mapy tylko wtedy, gdy lewy rozmiar stołu jest mały.
Wniosek
Staraliśmy się uwzględnić najlepsze możliwe punkty Map Join w Hive. Jak widzieliśmy powyżej, łączenie po stronie mapy działa najlepiej, gdy jedna tabela zawiera mniej danych, dzięki czemu zadanie jest szybko wykonywane. Czas potrzebny na pokazanie tutaj zapytań zależy od wielkości zbioru danych, dlatego pokazany tutaj czas służy tylko do analizy. Łączenie map można łatwo wdrożyć w aplikacjach czasu rzeczywistego, ponieważ mamy ogromne dane, co pomaga zmniejszyć ruch we / wy w sieci.
Polecane artykuły
To jest przewodnik po Map Join in Hive. Tutaj omawiamy przykłady Map Join in Hive wraz z zaletami i ograniczeniami. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Dołącza do ula
- Wbudowane funkcje Hive
- Co to jest ul?
- Polecenia gałęzi