
Wprowadzenie do nauki o wzmocnieniu
Uczenie się ze wzmocnieniem jest rodzajem uczenia maszynowego, a zatem jest również częścią sztucznej inteligencji, gdy zastosowane do systemów, systemy wykonują kroki i uczą się w oparciu o wyniki kroków w celu uzyskania złożonego celu, który ma zostać osiągnięty przez system.
Zrozumienie uczenia się przez wzmocnienie
Spróbujmy w ramach uczenia się przez wzmocnienie przy pomocy 2 prostych przypadków użycia:
Przypadek 1
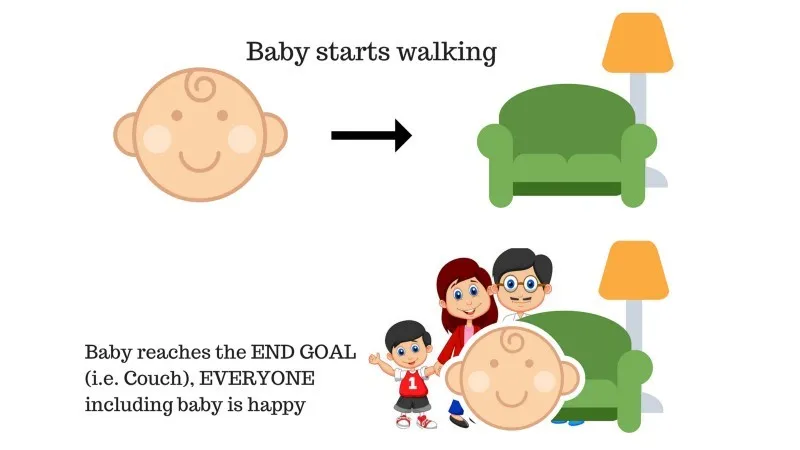
W rodzinie jest dziecko, które właśnie zaczęło chodzić i wszyscy są z tego powodu bardzo zadowoleni. Pewnego dnia rodzice starają się wyznaczyć sobie cel, pozwolić dziecku dotrzeć do kanapy i sprawdzić, czy dziecko jest w stanie to zrobić.
Wynik przypadku 1: Dziecko z powodzeniem dociera do kanapy, dlatego wszyscy w rodzinie są bardzo zadowoleni z tego. Wybrana ścieżka ma teraz pozytywną nagrodę.
Punkty: Nagroda + (+ n) → Pozytywna nagroda.
Źródło: https://images.app.goo.gl/pGCXJ1N1bzLAer126
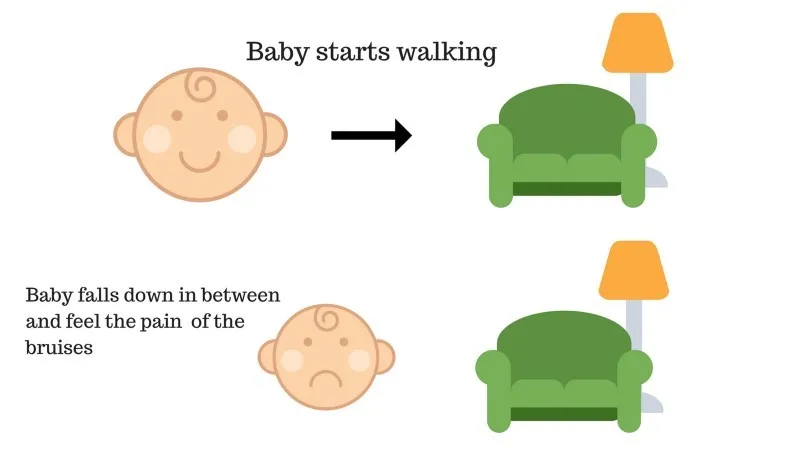
Przypadek nr 2
Dziecko nie było w stanie dosięgnąć kanapy i dziecko upadło. To boli! Co może być przyczyną? Na drodze do kanapy mogą znajdować się przeszkody, a dziecko wpadło na przeszkody.
Wynik przypadku 2: Dziecko napotyka pewne przeszkody i płacze! Och, to było złe, nauczyła się, aby nie wpaść w pułapkę przeszkody następnym razem. Wybrana ścieżka ma teraz nagrodę negatywną.
Punkty: Nagrody + (-n) → Nagroda ujemna.
Źródło: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
To teraz widzieliśmy przypadki 1 i 2, w praktyce uczenie się przez wzmacnianie robi to samo, z tym wyjątkiem, że nie jest to człowiek, ale zamiast tego wykonywane obliczeniowo.
Krokowe stosowanie zbrojenia
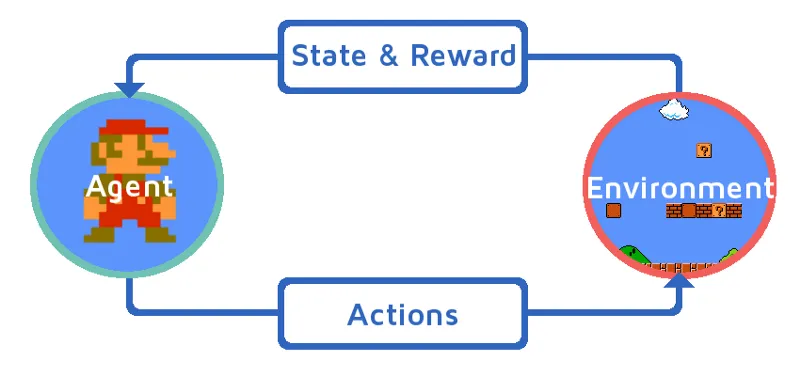
Pozwól nam zrozumieć uczenie się przez zbrojenie poprzez stopniowe wprowadzenie agenta zbrojenia. W tym przykładzie naszym uczącym się wzmacniaczem jest Mario, który nauczy się grać samodzielnie:
Źródło: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Obecny stan środowiska gry Mario to S_0. Ponieważ gra jeszcze się nie rozpoczęła, a Mario jest na swoim miejscu.
- Następnie rozpoczyna się gra i Mario się porusza, Mario, czyli agent RL, podejmuje akcję, powiedzmy A_0.
- Teraz stan środowiska gry zmienił się na S_1.
- Ponadto agentowi RL, tj. Mario, przypisano teraz jakiś pozytywny punkt nagrody, R_1, prawdopodobnie dlatego, że Mario wciąż żyje i nie napotkano żadnego niebezpieczeństwa.
Teraz powyższa pętla będzie działać, dopóki Mario nie będzie w końcu martwy lub Mario nie dotrze do celu. Ten model będzie nieprzerwanie generował akcję, nagrodę i stan.
Nagrody za maksymalizację
Celem uczenia się przez wzmocnienie jest maksymalizacja korzyści poprzez uwzględnienie pewnych innych czynników, takich jak rabat nagród; wyjaśnimy wkrótce, co należy rozumieć przez rabat za pomocą ilustracji.
Łączna formuła nagród zdyskontowanych jest następująca:
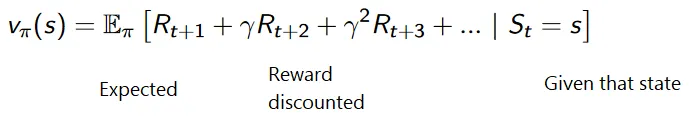
Nagrody rabatowe
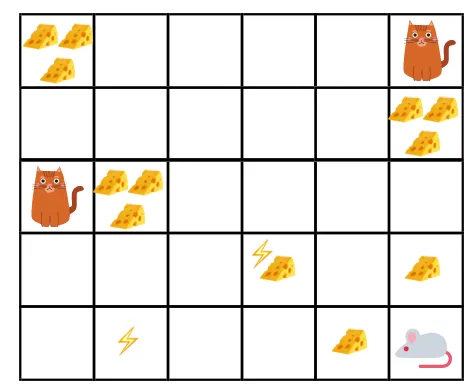
Pozwól nam to zrozumieć na przykładzie:
- Na podanym rysunku celem jest, aby mysz w grze zjadła tyle sera, zanim zostanie zjedzona przez kota lub bez porażenia prądem.
- Teraz możemy założyć, że im bliżej jesteśmy kota lub pułapki elektrycznej, tym większe prawdopodobieństwo, że mysz zostanie zjedzona lub zszokowana.
- Oznacza to, że nawet jeśli mamy pełny ser w pobliżu bloku porażenia prądem lub w pobliżu kota, bardziej ryzykowne jest tam pójść, lepiej jest jeść ser, który jest w pobliżu, aby uniknąć ryzyka.
- Mimo to mamy jeden „blok 1” sera, który jest pełny i znajduje się daleko od kota, i blok porażenia prądem, a drugi „blok 2”, który również jest pełny, ale jest albo blisko kota, albo bloku porażenia prądem, późniejszy blok sera, tj. „blok2”, będzie bardziej dyskontowany pod względem nagród niż poprzedni.
Źródło: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Źródło: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Rodzaje uczenia się przez zbrojenie
Poniżej znajdują się dwa rodzaje uczenia się przez wzmocnienie wraz z jego zaletami i wadami:
1. Pozytywne
Kiedy siła i częstotliwość zachowania są zwiększone z powodu wystąpienia określonego zachowania, jest to znane jako pozytywne uczenie się wzmacniające.
Zalety: Wydajność jest zmaksymalizowana, a zmiana pozostaje na dłużej.
Wady: wyniki mogą być zmniejszone, jeśli mamy zbyt dużo wzmocnienia.
2. Negatywne
Jest to wzmocnienie zachowania, głównie z powodu zniknięcia negatywnego terminu.
Zalety: Zachowanie jest zwiększone.
Wady: Tylko minimalne zachowanie modelu można osiągnąć za pomocą negatywnego uczenia się wzmacniającego.
Gdzie warto zastosować uczenie się przez wzmocnienie?
Rzeczy, które można zrobić za pomocą Reinforcement Learning / Przykłady. Oto obszary, w których obecnie wykorzystuje się uczenie się przez wzmocnienie:
- Opieka zdrowotna
- Edukacja
- Gry
- Wizja komputerowa
- Zarządzanie przedsiębiorstwem
- Robotyka
- Finanse
- NLP (przetwarzanie w języku naturalnym)
- Transport
- Energia
Kariera w uczeniu się przez zbrojenie
Rzeczywiście jest raport z miejsca pracy, ponieważ RL jest gałęzią uczenia maszynowego, zgodnie z raportem, Machine Learning to najlepsza praca z 2019 roku. Poniżej znajduje się migawka raportu. Zgodnie z obecnymi trendami inżynierowie uczenia maszynowego mają imponującą średnią pensję w wysokości 146 085 USD i stopę wzrostu 344 procent.
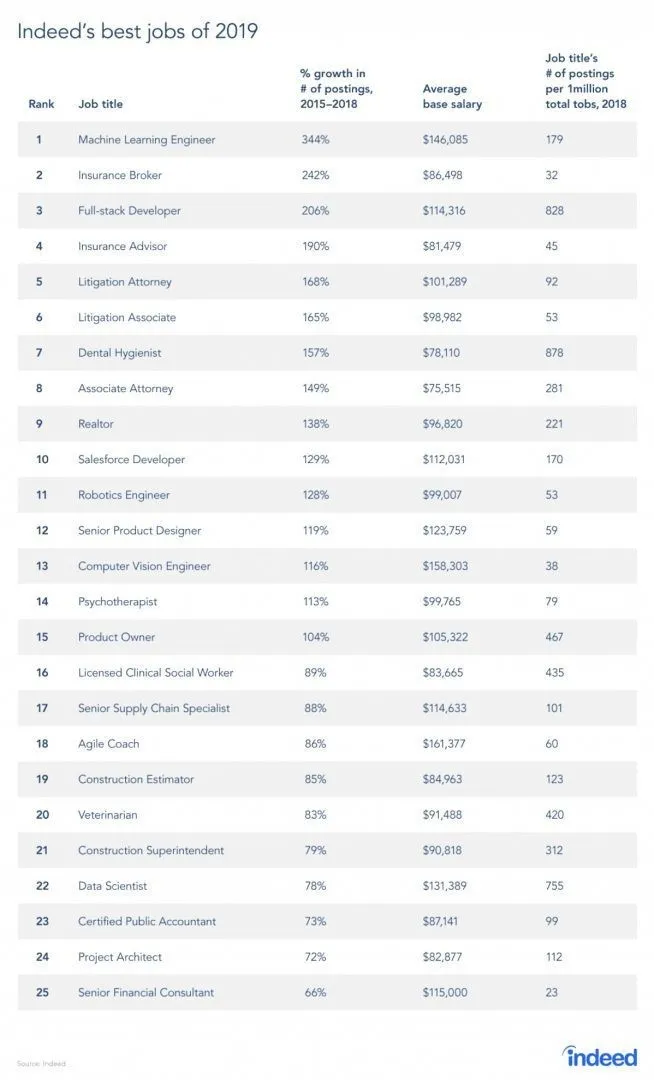
Źródło: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Umiejętności dla uczenia się ze wzmocnieniem
Poniżej znajdują się umiejętności potrzebne do uczenia się przez wzmocnienie:
1. Podstawowe umiejętności
- Prawdopodobieństwo
- Statystyka
- Modelowanie danych
2. Umiejętności programowania
- Podstawy programowania i informatyki
- Projektowanie oprogramowania
- Potrafi zastosować biblioteki i algorytmy uczenia maszynowego
3. Języki programowania maszynowego
- Pyton
- R
- Chociaż istnieją również inne języki, w których można zaprojektować modele uczenia maszynowego, takie jak Java, C / C ++, ale Python i R są najczęściej używanymi językami.
Wniosek
W tym artykule zaczęliśmy od krótkiego wprowadzenia na temat nauki o wzmocnieniu, a następnie zagłębiliśmy się w działanie RL i różne czynniki, które są zaangażowane w działanie modeli RL. Następnie umieściliśmy kilka rzeczywistych przykładów, aby lepiej zrozumieć ten temat. Pod koniec tego artykułu należy dobrze zrozumieć działanie uczenia się wzmacniającego.
Polecane artykuły
To jest przewodnik po tym, czym jest uczenie się zbrojenia ?. W tym miejscu omawiamy przykłady i różne czynniki związane z opracowywaniem modeli uczenia się zbrojenia. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej -
- Rodzaje algorytmów uczenia maszynowego
- Wprowadzenie do sztucznej inteligencji
- Narzędzia sztucznej inteligencji
- Platforma IoT
- Top 6 języków programowania maszynowego