
Różnica między Hadoop a Redshift
Hadoop to platforma open source opracowana przez Apache Software Foundation, której główne zalety to skalowalność, niezawodność i przetwarzanie rozproszone. Przetwarzanie danych, przechowywanie, dostęp, bezpieczeństwo to kilka rodzajów funkcji dostępnych w ekosystemie Hadoop. HDFS ma wysoką przepustowość, co oznacza zdolność do obsługi dużych ilości danych z możliwością przetwarzania równoległego. Redshift jest usługą hostingową w chmurze opracowaną przez jednostkę Amazon Web Services w ramach Amazon.com Inc., Spośród istniejących usług świadczonych przez Amazon. Służy do projektowania hurtowni danych na dużą skalę w chmurze. Redshift to usługa hurtowni danych w skali petabajta, która jest w pełni zarządzana i opłacalna pod względem operowania na dużych zestawach danych.
Przyjrzyjmy się szczegółowo Hadoop i Redshift:
Hadoop HDFS ma wysoką odporność na uszkodzenia i został zaprojektowany do pracy na niedrogich systemach sprzętowych. Hadoop może obsługiwać minimalny rozmiar TeraBytes do GigaBytes plików w swoim systemie. HDFS to architektura master-slave składająca się z węzłów nazw i węzłów danych, w których węzeł nazw zawiera metadane, a węzeł danych zawiera rzeczywiste dane do przetworzenia lub obsługi.
RedShift wykorzystuje różne techniki ładowania danych, takie jak raportowanie BI (Business Intelligence), narzędzia analityczne i eksploracja danych. Redshift zapewnia konsolę do tworzenia i zarządzania klastrami Amazon Redshift. Podstawowym składnikiem Redshift Data Warehouse jest klaster.
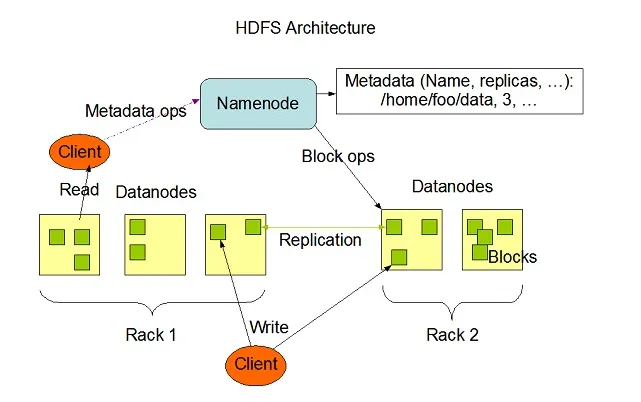
Źródło obrazu: Apache.org
Architektura RedShift:
 Źródło obrazu: Amazon.com
Źródło obrazu: Amazon.com
Bezpośrednie porównanie między Hadoop a Redshift (infografiki):
Poniżej znajduje się 10 najlepszych zestawień między Hadoop i Redshift:

Kluczowe różnice między Hadoop a Redshift:
Poniżej znajdują się kluczowe różnice między Hadoop a Redshift w następujący sposób
1. Architektura Hadoop HDFS (Hadoop Distributed File System) ma węzły nazw i węzły danych, podczas gdy Redshift ma węzeł wiodący i węzły obliczeniowe, w których węzły obliczeniowe zostaną podzielone na partycje jako plastry.
2. Hadoop zapewnia interfejs wiersza poleceń do interakcji z systemem plików, podczas gdy RedShift ma konsolę zarządzania do interakcji z usługami pamięci Amazon, takimi jak S3, DynamoDB itp.,
3. Operacje na bazie danych mają być konfigurowane przez programistów. W Redshift automatyzuje operacje na bazie danych, analizując plany wykonania.
4.Hadoop ma kilka narzędzi innych firm, które można łatwo zintegrować, podczas gdy Redshift obsługuje tylko produkty opracowane przez Amazon w chmurze.
5. Pod względem projektu architektonicznego Hadoop sieć, pamięć masowa, bezpieczeństwo i wydajność zostały uznane za podstawowe elementy, podczas gdy w Redshift elementy te można łatwo i elastycznie konfigurować za pomocą konsoli zarządzania chmurą Amazon.
6.Hadoop to architektura systemu plików oparta na interfejsach programowania aplikacji Java (API), natomiast Redshift oparty jest na systemie zarządzania bazami danych modelu relacyjnego (RDBMS).
7.Hadoop może mieć integracje z różnymi dostawcami, a Redshift nie ma wsparcia w tym przypadku, w którym Amazon jest ich jedynym dostawcą. Co się stanie, jeśli użytkownik będzie niezadowolony z usługi? W tym przypadku Hadoop jest zaletą.
8. Większość istniejących firm nadal korzysta z Hadoop, podczas gdy nowi klienci wybierają RedShift.
9.Pod względem wydajności Hadoop zawsze pozostaje w tyle, a Redshift zawsze wygrywa w przypadku wykonywania zapytań na dużych ilościach danych.
10.Hadoop używa modelu programowania Map Reduce do uruchamiania zadań. Amazon Redshift korzysta z elastycznej redukcji mapy Amazon.
11.Hadoop używa modelu programowania Map Reduce do uruchamiania zadań. Amazon Redshift korzysta z elastycznej redukcji mapy Amazon.
12. Hadoop lepiej jest codziennie uruchamiać zadania wsadowe, które stają się tańsze, podczas gdy Redshift wychodzi taniej w przypadku technologii przetwarzania analitycznego online (OLAP), która stoi za wieloma narzędziami Business Intelligence.
13.Hadoop jest 10 razy wolniejszy niż Redshift w uruchamianiu zapytań w podobny sposób, jak Hadoop jest 10 razy droższy niż Redshift, co powoduje, że Hadoop jest najmniej wybrany przed Redshift.
14. Jeśli chodzi o ładowanie danych, Hadoop jest za Redshift, jeśli system poświęca godziny na załadowanie danych z pamięci do swojego systemu przetwarzania plików.
15.Hadoop może być wykorzystywany do tanich magazynów, archiwizacji danych, jezior danych, hurtowni danych i analiz danych, podczas gdy Redshift jest objęty możliwościami hurtowni danych, co ogranicza wykorzystanie do wielu celów.
16. Platforma Hadoop zapewnia wsparcie dla różnych zewnętrznych dostawców i własnych projektów Apache, takich jak Storm, Spark, Kafka, Solr itp., Z drugiej strony Redshift ma ograniczoną obsługę integracji z jej jedynymi produktami Amazon
Tabela porównawcza Hadoop vs Redshift
| PODSTAWA DO
PORÓWNANIE | HADOOP | PRZESUNIĘCIE KU CZERWIENI |
| Dostępność | Framework Open Source autorstwa Apache Projects | Usługi wycenione świadczone przez Amazon |
| Realizacja | Dostarczone przez dostawców Hortonworks i Cloudera itp., | Opracowane i dostarczone przez Amazon |
| Występ | Zadania Hadoop MapReduce są wolniejsze | Redshift działa szybciej niż klaster Hadoop |
| Skalowalność | Ograniczenia skalowalności | Łatwo zmniejszyć / zwiększyć zgodnie z wymaganiami |
| cennik | Uruchamianie zapytań kosztuje 200 USD miesięcznie | Cena zależy od regionu serwera i jest tańsza niż Hadoop
Np .: 20 USD / miesiąc |
| Prędkość | Szybszy, ale wolniejszy w porównaniu do Redshift | 10 razy szybszy niż Hadoop |
| Szybkość zapytania | Uruchomienie danych o pojemności 1, 2 TB zajmuje 1491 sekund | 155 sekund na uruchomienie danych o pojemności 1, 2 TB |
| Integracja danych | Elastyczny z lokalnym systemem plików i dowolną bazą danych | Może ładować dane tylko z Amazon S3 lub DynamoDB |
| Format danych | Obsługiwane są wszystkie formaty danych | Surowe w formatach danych, takich jak formaty plików CSV |
| Łatwość użycia | Złożone i trudniejsze w obsłudze czynności administracyjne | Zautomatyzowane tworzenie kopii zapasowych i zarządzanie hurtownią danych |
Wniosek - Hadoop vs Redshift
Ostatecznym stwierdzeniem, które kończy wielki zwycięzca tego porównania, jest Redshift, który wygrywa pod względem łatwości obsługi, konserwacji i wydajności, podczas gdy Hadoop brakuje pod względem skalowalności wydajności i kosztów usług, z jedyną korzyścią łatwej integracji z narzędziami innych firm i produkty. Redshift ewoluował ostatnio z ogromnym wzrostem i akceptacją ze strony wielu klientów i klientów ze względu na wysoką dostępność i mniejszy koszt operacji w porównaniu do Hadoop, dzięki czemu jest coraz bardziej popularny. Ale do tej pory większość istniejących firm z listy Fortune 1000 używało platform Hadoop w swoich architekturach do zarządzania danymi klientów.
W większości przypadków RedShift był najlepszym wyborem do rozważenia w celach biznesowych przez dowolnego klienta lub klienta w celu obsługi dużych i poufnych danych wszelkich instytucji finansowych lub informacji publicznych z większą integralnością i bezpieczeństwem danych.
Oprócz tego Hadoop ma swoje zalety, ponieważ jest projektem open source i był dostępny przez wiele lat, a także powoduje, że istniejące systemy są wymieniane jako proces ponoszący koszty. Produkt należy ostatecznie wybrać na podstawie wymagań i elastyczności, a nie ceny lub popularności w oparciu o potrzeby biznesowe.
Polecany artykuł:
Jest to przewodnik po Hadoop vs Redshift, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Hadoop vs Hive - Znajdź najlepsze różnice
- HADOOP vs RDBMS | Poznaj 12 przydatnych różnic
- Apache Hadoop vs Apache Spark | 10 najlepszych porównań, które musisz znać!
- Big Data vs Data Science - czym się różnią?
- Przewodnik po Hadoop vs Spark
- 4 najlepszych dostawców hostingu w chmurze z funkcjami