

Wprowadzenie do RDBMS Wywiad Pytania i odpowiedzi
Więc jeśli przygotowujesz się do rozmowy kwalifikacyjnej w RDBMS. Jestem pewien, że chcesz poznać najczęstsze pytania i odpowiedzi na wywiad RDBMS 2019, które pomogą Ci łatwo przełamać wywiad RDBMS. Poniżej znajduje się lista najlepszych pytań i odpowiedzi na wywiad RDBMS.
Dlatego zwykle dodajemy najlepsze pytania do wywiadu RDBMS 2019, które są zadawane głównie w trakcie wywiadu
1. Jakie są różne funkcje RDBMS?
Odpowiedź:
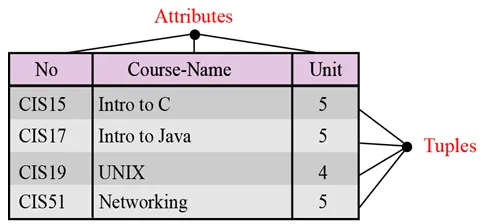
Nazwa. Każda relacja w relacyjnej bazie danych powinna mieć nazwę unikalną wśród wszystkich innych relacji.
Atrybuty Każda kolumna w relacji jest nazywana atrybutem.
Krotki Każdy wiersz w relacji nazywany jest krotką. Krotka definiuje zbiór wartości atrybutów.
2. Wyjaśnić model ER?
Odpowiedź:
Model ER to model relacji jednostka-związek. Model ER oparty jest na realnym świecie, który składa się z bytów i obiektów relacji. Elementy są ilustrowane w bazie danych przez zestaw atrybutów.
3. Zdefiniować model obiektowy?
Odpowiedź:
Model obiektowy oparty jest na kolekcjach obiektów. Obiekt przyjmuje wartości przechowywane w zmiennych instancji wewnątrz obiektu. Obiekty o identycznym typie wartości i dokładnie tych samych metodach są pogrupowane w klasy.
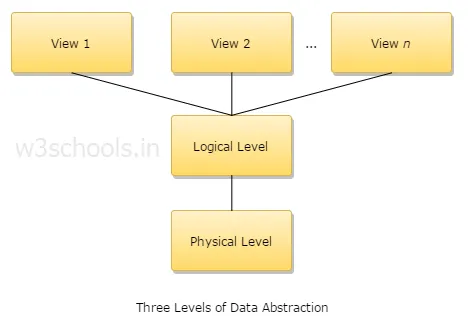
4. Wyjaśnić trzy poziomy abstrakcji danych?
Odpowiedź:
1. Poziom fizyczny: jest to najniższy poziom abstrakcji i opisuje sposób przechowywania danych.
2. Poziom logiczny: Następny poziom abstrakcji jest logiczny, opisuje, jaki typ danych jest przechowywany w bazie danych i jaki jest związek między tymi danymi.
3. Poziom widoku: najwyższy poziom abstrakcji i opisuje jedyną całą bazę danych.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Jakie są różne 12 zasad Codda dotyczących relacyjnej bazy danych?
Odpowiedź:
12 zasad Codda to zestaw trzynastu zasad (ponumerowanych od zera do dwunastu) zaproponowanych przez Edgara F. Codda.
Zasady Codda:
Reguła 0: System musi kwalifikować się jako relacyjny, jako baza danych, a także jako system zarządzania.
Reguła 1: Reguła informacyjna: Każda informacja w bazie danych musi być reprezentowana w sposób jednoznaczny, głównie nazwy wartości w pozycjach kolumn w innym wierszu tabeli.
Zasada 2: Zasada gwarantowanego dostępu: wszystkie dane muszą być ingresywne. Mówi, że każda wartość skalarna w bazie danych musi być poprawnie / logicznie adresowalna.
Reguła 3: Systematyczne traktowanie wartości zerowych: DBMS musi pozwalać każdej krotce pozostawać zerową.
Zasada 4: Aktywny katalog online (struktura bazy danych) oparty na modelu relacyjnym: System musi obsługiwać strukturę online, relacyjną itp., Która jest istotna dla dozwolonych użytkowników za pomocą ich regularnych zapytań.
Zasada 5: Podrzędny język danych: System musi obsługiwać co najmniej jeden język relacyjny, który:
1.Posiada składnię liniową
2. Które mogą być używane zarówno interaktywnie, jak i w aplikacjach,
3.Obsługuje operacje definiowania danych (DDL), operacje manipulacji danymi (DML), ograniczenia bezpieczeństwa i integralności oraz operacje zarządzania transakcjami (rozpoczynanie, zatwierdzanie i wycofywanie).
Reguła 6: Reguła aktualizacji widoków : Wszystkie widoki, które teoretycznie poprawiają się, muszą być aktualizowane przez system.
Reguła 7: Wstawianie, aktualizacja i usuwanie wysokiego poziomu: System musi obsługiwać operatory wstawiania, aktualizacji i usuwania.
Zasada 8: Fizyczna niezależność danych: modyfikacja poziomu fizycznego (sposób przechowywania danych, używanie tablic lub połączonych list itp.) Nie może wymagać modyfikacji aplikacji.
Reguła 9: Niezależność danych logicznych: modyfikacja poziomu logicznego (tabele, kolumny, wiersze itp.) Nie może wymagać modyfikacji aplikacji.
Reguła 10: Niezależność od integralności: Ograniczenia dotyczące integralności muszą być identyfikowane indywidualnie przez aplikacje i przechowywane w katalogu.
Zasada 11: Niezależność dystrybucji: Dystrybucja części bazy danych do różnych lokalizacji nie powinna być widoczna dla użytkowników bazy danych.
Reguła 12: Reguła braku subwersji: Jeśli system zapewnia interfejs niskiego poziomu (tj. Rekordy), to interfejs ten nie może być użyty do obalenia systemu.
6.Co to jest normalizacja? i co wyjaśnia różne formy normalizacji.
Odpowiedź:
Normalizacja bazy danych to proces organizowania danych w celu zminimalizowania nadmiarowości danych. Co z kolei zapewnia spójność danych. Istnieje wiele problemów związanych z redundancją danych, takich jak marnowanie miejsca na dysku, niespójność danych, spowolnienie zapytań DML (Data Manipulation Language). Istnieją różne formy normalizacji: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Dane w każdej kolumnie powinny być wielokrotnymi liczbami atomowymi oddzielonymi przecinkiem. Tabela nie zawiera powtarzających się grup kolumn. Zidentyfikuj każdy rekord w sposób unikalny, używając klucza podstawowego.
2. 2NF: - Tabela powinna spełniać wszystkie warunki 1NF i przenieść zbędne dane do osobnej tabeli. Ponadto tworzy relacje między tymi tabelami przy użyciu kluczy obcych.
3. 3NF: - dla tabeli 3NF powinien spełniać wszystkie warunki 1NF i 2NF. 3NF nie zawiera atrybutów częściowo zależnych od klucza podstawowego.
7. Zdefiniować klucz główny, klucz obcy, klucz kandydujący, klucz super?
Odpowiedź:
Klucz podstawowy : klucz podstawowy to klucz, który nie pozwala na duplikowanie wartości i wartości zerowych. Klucz podstawowy można zdefiniować na poziomie kolumny lub tabeli. Dozwolony jest tylko jeden klucz podstawowy na tabelę.
Klucz obcy : klucz obcy dopuszcza tylko wartości obecne w odnośnej kolumnie. Pozwala na zduplikowanie lub zerowanie wartości. Można go zdefiniować jako poziom kolumny lub poziom tabeli. Może odwoływać się do kolumny klucza unikalnego / podstawowego.
Klucz kandydata: Klucz kandydata to minimalny superklucz, brak odpowiedniej podgrupy atrybutów Klucz kandydata może być superkluczem.
Superklucz : Superklucz to zestaw atrybutów schematu relacji, od którego wszystkie atrybuty schematu są częściowo zależne. Żadne dwa wiersze nie mogą mieć takiej samej wartości superkluczowych atrybutów.
8. Jaki jest inny typ indeksów?
Odpowiedź:
Indeksy to:
Indeks klastrowy: - Jest to indeks, w którym dane są fizycznie przechowywane na dysku. Dlatego do tabeli bazy danych można utworzyć tylko jeden indeks klastrowy.
Indeks nieklastrowany: - Nie definiuje danych fizycznych, ale definiuje logiczne uporządkowanie. Zazwyczaj w tym celu tworzy się B-Tree lub B + tree.
9. Jakie są zalety RDBMS?
Odpowiedź:
• Kontrolowanie nadmiarowości.
• Można dochować integralności.
• Można uniknąć niespójności.
• Dane mogą być udostępniane.
• Standard można egzekwować.
10. Nazwać niektóre podsystemy RDBMS?
Odpowiedź:
Wejście-wyjście, bezpieczeństwo, przetwarzanie języka, zarządzanie pamięcią masową, rejestrowanie i odzyskiwanie, kontrola dystrybucji, kontrola transakcji, zarządzanie pamięcią.
11. Co to jest Menedżer buforów?
Odpowiedź:
Menedżer buforów udaje się zbierać dane z pamięci dyskowej do pamięci głównej i decydować, które dane mają być przechowywane w pamięci podręcznej w celu szybszego przetwarzania.
Polecany artykuł
Jest to przewodnik po liście pytań i odpowiedzi na rozmowę kwalifikacyjną RDBMS, dzięki czemu kandydat może łatwo stłumić pytania podczas rozmowy kwalifikacyjnej RDBMS. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Najważniejsze pytania dotyczące wywiadu z zakresu analizy danych
- 13 niesamowitych testów bazy danych Wywiad Pytania i odpowiedzi
- 10 najlepszych wzorów wywiadu Pytania i odpowiedzi
- 5 Przydatnych wywiadów SSIS Pytania i odpowiedzi