

Wprowadzenie do technik Data Science
W dzisiejszym świecie, w którym dane są nowym złotem, firma może przeprowadzić różne analizy. Wynik projektu dotyczącego analizy danych różni się znacznie w zależności od rodzaju dostępnych danych, a zatem wpływ jest również zmienny. Ponieważ dostępnych jest wiele różnych rodzajów analiz, konieczne jest zrozumienie, co trzeba wybrać kilka podstawowych technik. Podstawowym celem technik analizy danych jest nie tylko wyszukiwanie odpowiednich informacji, ale także wykrywanie słabych łączy, które mają tendencję do słabego działania modelu.
Co to jest Data Science?
Analiza danych jest dziedziną, która rozciąga się na kilka dyscyplin. Zawiera metody naukowe, procesy, algorytmy i systemy do gromadzenia wiedzy i pracy nad nimi. Dziedzina ta obejmuje różnorodne gatunki i jest wspólną platformą do unifikacji pojęć statystyki, analizy danych i uczenia maszynowego. W tym teoretyczna wiedza statystyczna wraz z danymi i technikami w czasie rzeczywistym w uczeniu maszynowym działa ręka w rękę, aby uzyskać owocne wyniki dla biznesu. Stosując różne techniki stosowane w informatyce, w dzisiejszym świecie możemy sugerować lepsze podejmowanie decyzji, które w przeciwnym razie mogłyby zostać pominięte przez ludzkie oko i umysł. Pamiętaj, że maszyna nigdy nie zapomina! Aby zmaksymalizować zysk w świecie opartym na danych, magia Data Science jest niezbędnym narzędziem.
Różne rodzaje techniki Data Science
W kilku następnych akapitach zajmiemy się powszechnymi technikami analizy danych stosowanymi w każdym innym projekcie. Chociaż czasami technika analizy danych może być specyficzna dla problemu biznesowego i może nie należeć do poniższych kategorii, nie ma problemu z określeniem ich jako różnych typów. Na wysokim poziomie dzielimy techniki na nadzorowane (znamy wpływ celu) i nienadzorowane (nie wiemy o zmiennej docelowej, którą próbujemy osiągnąć). Na kolejnym poziomie techniki można podzielić pod względem
- Wynik, jaki otrzymalibyśmy lub jaki jest cel problemu biznesowego
- Rodzaj użytych danych.
Przyjrzyjmy się najpierw segregacji opartej na intencji.
1. Uczenie się bez nadzoru
- Wykrywanie anomalii
W tego typu technice identyfikujemy wszelkie nieoczekiwane zdarzenia w całym zbiorze danych. Ponieważ zachowanie różni się od faktycznego przebiegu danych, podstawowe założenia są następujące:
- Wystąpienie tych przypadków jest bardzo małe.
- Różnica w zachowaniu jest znacząca.
Algorytmy anomalii są wyjaśnione, na przykład Las izolacji, który zapewnia ocenę dla każdego rekordu w zestawie danych. Ten algorytm jest modelem opartym na drzewie. Korzystając z tego rodzaju techniki wykrywania i jej popularności, są one wykorzystywane w różnych przypadkach biznesowych, na przykład podczas przeglądania stron internetowych, współczynnika rezygnacji, przychodu na kliknięcie itp. Na poniższym wykresie możemy wyjaśnić, jak wygląda anomalia.
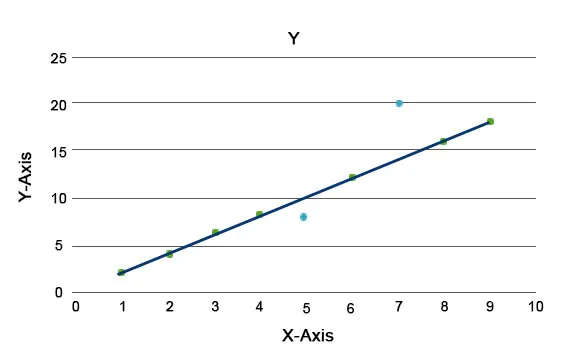
Te w kolorze niebieskim reprezentują anomalię w zbiorze danych. Różnią się one od zwykłej linii trendu i występują rzadziej.
- Analiza skupień
Dzięki tej analizie głównym zadaniem jest podzielenie całego zestawu danych na grupy, aby trend lub cechy w punktach danych jednej grupy były do siebie bardzo podobne. W terminologii nauki o danych nazywamy je klastrami. Na przykład w branży detalicznej planuje się skalowanie działalności i konieczne jest, aby wiedzieć, jak zachowają się nowi klienci w nowym regionie na podstawie danych z przeszłości, które posiadamy. Opracowanie strategii dla każdej osoby w populacji staje się niemożliwe, ale przydatne będzie grupowanie populacji w klastry, aby strategia była skuteczna w grupie i była skalowalna.
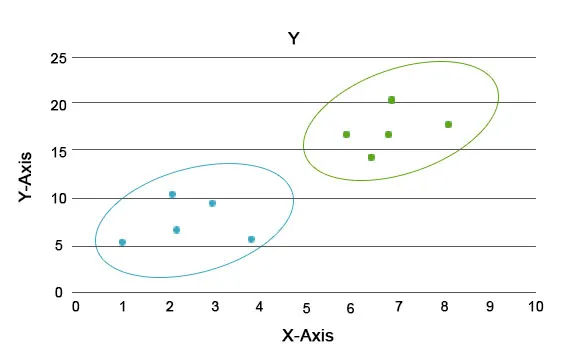
Tutaj kolory niebieski i pomarańczowy są różnymi skupieniami posiadającymi w sobie unikalne cechy.
- Analiza asocjacji
Ta analiza pomaga nam budować ciekawe relacje między elementami w zestawie danych. Ta analiza ujawnia ukryte relacje i pomaga w reprezentowaniu elementów zestawu danych w postaci reguł asocjacji lub zestawów częstych elementów. Reguła asocjacji jest podzielona na 2 kroki:
- Częste generowanie zestawu przedmiotów: W tym zestawie generowany jest zestaw, w którym często występujące elementy są zestawiane razem.
- Generowanie reguł: zestaw zbudowany powyżej jest przepuszczany przez różne warstwy tworzenia reguł, aby zbudować ukrytą relację między sobą. Na przykład zestaw może wpaść w problemy koncepcyjne lub związane z implementacją lub aplikacjami. Są one następnie rozgałęzione w odpowiednich drzewach, aby zbudować reguły asocjacji.
Na przykład APRIORI jest algorytmem budowania reguł asocjacyjnych.
2. Uczenie nadzorowane
- Analiza regresji
W analizie regresji definiujemy zmienną zależną / docelową i pozostałe zmienne jako zmienne niezależne i ostatecznie hipotezujemy, w jaki sposób jedna / więcej zmiennych niezależnych wpływa na zmienną docelową. Regresja z jedną zmienną niezależną nazywa się jednowymiarową, a więcej niż jedna jest znana jako wielowymiarowa. Pozwól nam zrozumieć, używając jednowymiarowego, a następnie skaluj dla wielowymiarowego.
Na przykład y jest zmienną docelową, a x 1 jest zmienną niezależną. Tak więc, znając linię prostą, możemy zapisać równanie jako y = mx 1 + c. Tutaj „m” określa, jak silnie na y wpływa x 1 . Jeśli „m” jest bardzo bliskie zeru, oznacza to, że zmiana x 1 nie ma silnego wpływu na y. Przy liczbie większej niż 1 uderzenie staje się silniejsze, a niewielka zmiana x 1 prowadzi do dużej zmienności y. Podobnie jak w przypadku jednowymiarowego, w wielowymiarowym można zapisać jako y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………. Tutaj wpływ każdej zmiennej niezależnej jest określony przez odpowiadające jej „m”.
- Analiza klasyfikacji
Podobnie jak w przypadku analizy skupień, algorytmy klasyfikacji są zbudowane ze zmienną docelową w postaci klas. Różnica między grupowaniem a klasyfikacją polega na tym, że w grupowaniu nie wiemy, do której grupy należą punkty danych, podczas gdy w klasyfikacji wiemy, do której grupy należy. I różni się od regresji z perspektywy, że liczba grup powinna być stałą liczbą w przeciwieństwie do regresji, jest ciągła. W analizie klasyfikacji istnieje szereg algorytmów, na przykład Maszyny wektorowe wsparcia, Regresja logistyczna, Drzewa decyzyjne itp.
Wniosek
Podsumowując, rozumiemy, że każdy rodzaj analizy jest sam w sobie rozległy, ale tutaj możemy nadać niewielki smak różnym technikom. W następnych kilku notatkach weźmiemy każdą z nich osobno i szczegółowo omówimy różne pod-techniki zastosowane w każdej z technik nadrzędnych.
Polecany artykuł
To jest przewodnik po technikach Data Science. Tutaj omawiamy wprowadzenie i różne rodzaje technik w dziedzinie danych. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Narzędzia do analizy danych | 12 najlepszych narzędzi
- Algorytmy analizy danych z typami
- Wprowadzenie do kariery Data Science
- Nauka danych a wizualizacja danych
- Przykłady regresji wielowymiarowej
- Utwórz drzewo decyzyjne z zaletami
- Krótki przegląd cyklu życia Data Science