
Wprowadzenie do cyklu życia Data Science
Cykl życia Data Science obraca się wokół uczenia maszynowego i innych metod analitycznych w celu uzyskania wglądu i prognoz na podstawie danych w celu osiągnięcia celu biznesowego. Cały proces obejmuje kilka etapów, takich jak czyszczenie danych, przygotowanie, modelowanie, ocena modelu itp. Jest to długi proces i jego ukończenie może potrwać kilka miesięcy. Dlatego bardzo ważna jest ogólna struktura dla każdego dostępnego problemu. Uznana na całym świecie struktura rozwiązywania wszelkich problemów analitycznych nazywana jest standardowym procesem międzybranżowym dla eksploracji danych lub strukturą CRISP-DM.
Cykl życia nauki o danych
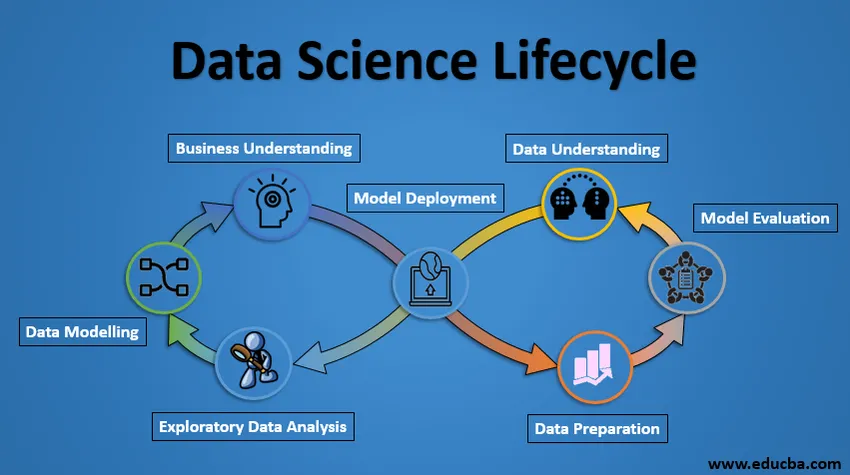
Poniżej znajduje się projekt Lifecycle of Data Science.
1. Zrozumienie biznesu
Cały cykl koncentruje się wokół celu biznesowego. Co rozwiążesz, jeśli nie będziesz miał konkretnego problemu? Niezwykle ważne jest jasne zrozumienie celu biznesowego, ponieważ będzie to twój ostateczny cel analizy. Tylko po odpowiednim zrozumieniu możemy ustalić konkretny cel analizy, który jest zsynchronizowany z celem biznesowym. Musisz wiedzieć, czy klient chce zmniejszyć stratę kredytową, czy może przewidzieć cenę towaru itp.
2. Zrozumienie danych
Po zrozumieniu biznesu następnym krokiem jest zrozumienie danych. Obejmuje to gromadzenie wszystkich dostępnych danych. Tutaj musisz ściśle współpracować z zespołem biznesowym, ponieważ tak naprawdę są świadomi, jakie dane są obecne, jakie dane mogą być wykorzystane do tego problemu biznesowego i innych informacji. Ten krok obejmuje opis danych, ich strukturę, ich znaczenie, typ danych. Przeglądaj dane za pomocą wykresów graficznych. Zasadniczo wyodrębnianie wszelkich informacji, które można uzyskać na temat danych, po prostu eksplorując dane.
3. Przygotowanie danych
Następnie następuje etap przygotowania danych. Obejmuje to takie kroki, jak wybieranie odpowiednich danych, integrowanie danych przez scalanie zestawów danych, czyszczenie ich, leczenie brakujących wartości przez ich usunięcie lub przypisanie, leczenie błędnych danych przez usunięcie ich, a także sprawdzenie wartości odstających za pomocą wykresów pudełkowych i obsługa ich . Konstruowanie nowych danych, czerpanie nowych funkcji z istniejących. Sformatuj dane do żądanej struktury, usuń niechciane kolumny i funkcje. Przygotowanie danych jest najbardziej czasochłonnym, ale prawdopodobnie najważniejszym krokiem w całym cyklu życia. Twój model będzie tak dobry, jak twoje dane.
4. Analiza danych eksploracyjnych
Ten krok wymaga zapoznania się z rozwiązaniem i wpływającymi na niego czynnikami przed zbudowaniem rzeczywistego modelu. Rozkład danych w obrębie różnych zmiennych obiektu jest badany graficznie za pomocą wykresów słupkowych. Relacje między różnymi obiektami są rejestrowane za pomocą reprezentacji graficznych, takich jak wykresy rozproszenia i mapy cieplne. Wiele innych technik wizualizacji danych jest szeroko wykorzystywanych do eksploracji każdej funkcji osobno i poprzez połączenie ich z innymi funkcjami.
5. Modelowanie danych
Modelowanie danych jest sercem analizy danych. Model przyjmuje przygotowane dane jako dane wejściowe i zapewnia pożądany wynik. Ten krok obejmuje wybór odpowiedniego typu modelu, niezależnie od tego, czy jest to problem z klasyfikacją, czy problem regresji, czy problem klastrowania. Po wybraniu rodziny modeli spośród różnych algorytmów z tej rodziny musimy starannie wybrać algorytmy do ich wdrożenia i wdrożenia. Musimy dostroić hiperparametry każdego modelu, aby osiągnąć pożądaną wydajność. Musimy również upewnić się, że istnieje odpowiednia równowaga między wydajnością a możliwością generalizacji. Nie chcemy, aby model uczył się danych i działał słabo na nowych danych.
6. Ocena modelu
Tutaj model jest oceniany pod kątem sprawdzenia, czy jest gotowy do wdrożenia. Model jest testowany na niewidzialnych danych, ocenianych na starannie przemyślanym zestawie wskaźników oceny. Musimy także upewnić się, że model jest zgodny z rzeczywistością. Jeśli nie uzyskamy zadowalającego wyniku w ocenie, musimy powtórzyć cały proces modelowania, aż do osiągnięcia pożądanego poziomu wskaźników. Każde rozwiązanie do analizy danych, model uczenia maszynowego, podobnie jak człowiek, powinno ewoluować, powinno być w stanie poprawić się o nowe dane, dostosować się do nowej miary oceny. Możemy zbudować wiele modeli dla określonego zjawiska, ale wiele z nich może być niedoskonałych. Ocena modelu pomaga nam wybrać i zbudować idealny model.
7. Wdrożenie modelu
Model po rygorystycznej ocenie jest ostatecznie wdrażany w pożądanym formacie i kanale. To ostatni krok w cyklu życia nauki o danych. Należy dokładnie przeanalizować każdy krok w cyklu życia nauki o danych wyjaśnionym powyżej. Jeśli jakikolwiek krok zostanie wykonany nieprawidłowo, wpłynie to na następny krok i cały wysiłek zmarnuje się. Na przykład, jeśli dane nie zostaną poprawnie zebrane, stracisz informacje i nie będziesz budował idealnego modelu. Jeśli dane nie zostaną poprawnie wyczyszczone, model nie będzie działał. Jeśli model nie zostanie właściwie oceniony, zawiedzie się w świecie rzeczywistym. Od zrozumienia biznesu do wdrożenia modelu, na każdym kroku należy poświęcić odpowiednią uwagę, czas i wysiłek.
Polecane artykuły
Jest to przewodnik po cyklu życia Data Science. Tutaj omawiamy przegląd cyklu życia Data Science i kroki, które składają się na cykl życia Data Science. Możesz również przejrzeć nasze powiązane artykuły, aby dowiedzieć się więcej -
- Wprowadzenie do algorytmów nauki danych
- Nauka danych a inżynieria oprogramowania Top 8 przydatnych porównań
- Różnice rodzajów technik Data Science
- Umiejętności analizy danych z typami