
Omówienie algorytmów sieci neuronowej
- Najpierw dowiedzmy się, co oznacza sieć neuronowa? Sieci neuronowe są inspirowane biologicznymi sieciami neuronowymi w mózgu lub można powiedzieć, że układ nerwowy. Wywołało to wiele emocji i nadal trwają badania nad tym podzbiorem uczenia maszynowego w przemyśle.
- Podstawową jednostką obliczeniową sieci neuronowej jest neuron lub węzeł. Odbiera wartości z innych neuronów i oblicza wynik. Każdy węzeł / neuron jest powiązany z wagą (w). Ta waga jest podawana zgodnie ze względnym znaczeniem tego konkretnego neuronu lub węzła.
- Tak więc, jeśli weźmiemy f jako funkcję węzła, wówczas funkcja węzła f zapewni dane wyjściowe, jak pokazano poniżej: -
Wyjście neuronu (Y) = f (w1.X1 + w2.X2 + b)
- Gdzie w1 i w2 są wagami, X1 i X2 są danymi liczbowymi, podczas gdy b jest błędem.
- Powyższa funkcja f jest funkcją nieliniową zwaną również funkcją aktywacji. Jego podstawowym celem jest wprowadzenie nieliniowości, ponieważ prawie wszystkie rzeczywiste dane są nieliniowe i chcemy, aby neurony poznały te reprezentacje.
Różne algorytmy sieci neuronowej
Spójrzmy teraz na cztery różne algorytmy sieci neuronowej.
1. Spadek gradientu
Jest to jeden z najpopularniejszych algorytmów optymalizacji w dziedzinie uczenia maszynowego. Jest używany podczas szkolenia modelu uczenia maszynowego. Mówiąc najprościej, służy w zasadzie do znalezienia wartości współczynników, które po prostu redukują funkcję kosztu tak bardzo, jak to możliwe. Po pierwsze, zaczynamy od zdefiniowania niektórych wartości parametrów, a następnie za pomocą rachunku różniczkowego i liczbowego zaczynamy iteracyjnie dostosowywać wartości, aby utracona funkcja jest zmniejszona.
Teraz przejdźmy do części, która jest gradientem ?. Tak więc gradient oznacza, że wyjście dowolnej funkcji ulegnie zmianie, jeśli zmniejszymy wejście nieznacznie lub innymi słowy, możemy wywołać go na zboczu. Jeśli nachylenie jest strome, model uczy się szybciej, podobnie model przestaje się uczyć, gdy nachylenie wynosi zero. Jest tak, ponieważ jest to algorytm minimalizacji, który minimalizuje dany algorytm.
Poniżej wzoru na znalezienie następnej pozycji pokazano w przypadku opadania gradientu.
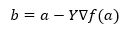
Gdzie b to następna pozycja
a to aktualna pozycja, gamma to funkcja oczekiwania.
Jak widać opadanie gradientu jest bardzo dobrą techniką, ale istnieje wiele obszarów, w których opadanie gradientu nie działa poprawnie. Poniżej niektóre z nich:
- Jeśli algorytm nie zostanie poprawnie wykonany, możemy napotkać problem zanikania gradientu. Występują, gdy gradient jest za mały lub za duży.
- Problemy pojawiają się, gdy uporządkowanie danych stanowi problem niewypukłej optymalizacji. Gradient przyzwoity działa tylko z problemami, które są problemami wypukłymi.
- Jednym z bardzo ważnych czynników, na które należy zwrócić uwagę przy stosowaniu tego algorytmu, są zasoby. Jeśli mamy mniej pamięci przypisanej do aplikacji, powinniśmy unikać algorytmu spadku gradientu.
2. Metoda Newtona
Jest to algorytm optymalizacji drugiego rzędu. Nazywa się to drugim rzędem, ponieważ wykorzystuje matrycę hesyjską. Tak więc macierz Hesji jest niczym więcej niż kwadratową macierzą pochodnych cząstkowych drugiego rzędu funkcji o wartościach skalarnych. W algorytmie optymalizacji metody Newtona jest stosowana do pierwszej pochodnej podwójnie różniczkowalnej funkcji f, aby mogła znaleźć pierwiastki / punkty stacjonarne. Przejdźmy teraz do kroków wymaganych przez metodę Newtona do optymalizacji.
Najpierw ocenia wskaźnik strat. Następnie sprawdza, czy kryteria zatrzymania są prawdziwe czy fałszywe. Jeśli fałsz, to oblicza kierunek treningu Newtona i tempo treningu, a następnie poprawia parametry lub wagi neuronu i ponownie ten sam cykl trwa. Możesz więc powiedzieć, że potrzeba mniej kroków w porównaniu do spadku gradientu, aby uzyskać minimum wartość funkcji. Chociaż zajmuje mniej kroków w porównaniu z algorytmem opadania gradientu, nadal nie jest szeroko stosowany, ponieważ dokładne obliczenia hessianu i jego odwrotności są bardzo kosztowne obliczeniowo.
3. Gradient sprzężony
Jest to metoda, którą można uznać za coś między spadkiem gradientu a metodą Newtona. Główna różnica polega na tym, że przyspiesza powolną konwergencję, którą zwykle kojarzymy z opadaniem gradientu. Innym ważnym faktem jest to, że można go stosować zarówno w systemach liniowych, jak i nieliniowych i jest to algorytm iteracyjny.
Został opracowany przez Magnusa Hestenesa i Eduarda Stiefela. Jak już wspomniano powyżej, że powoduje on szybszą zbieżność niż opadanie gradientu, powodem tego jest to, że w algorytmie sprzężonego gradientu wyszukiwanie odbywa się wraz ze sprzężonymi kierunkami, dzięki czemu zbiega się szybciej niż algorytmy spadku gradientu. Należy zwrócić uwagę na to, że γ nazywa się parametrem sprzężonym.
Kierunek treningu jest okresowo resetowany do ujemnej wartości gradientu. Ta metoda jest bardziej skuteczna niż opadanie gradientu w uczeniu sieci neuronowej, ponieważ nie wymaga macierzy Hesji, która zwiększa obciążenie obliczeniowe, a także zbiega się szybciej niż opadanie gradientu. Należy stosować w dużych sieciach neuronowych.
4. Metoda Quasi-Newtona
Jest to alternatywne podejście do metody Newtona, ponieważ wiemy teraz, że metoda Newtona jest drogo obliczeniowa. Ta metoda rozwiązuje te wady w takim stopniu, że zamiast obliczać macierz Hesji, a następnie bezpośrednio obliczać odwrotność, metoda ta tworzy przybliżenie odwrotnego Hesji przy każdej iteracji tego algorytmu.
To przybliżenie jest teraz obliczane na podstawie informacji z pierwszej pochodnej funkcji straty. Możemy więc powiedzieć, że jest to prawdopodobnie najlepsza metoda radzenia sobie z dużymi sieciami, ponieważ oszczędza czas obliczeń, a także jest znacznie szybsza niż gradient opadania lub metoda gradientu sprzężonego.
Wniosek
Zanim zakończymy ten artykuł, porównajmy obliczeniową szybkość i pamięć dla wyżej wymienionych algorytmów. Zgodnie z wymaganiami dotyczącymi pamięci opadanie gradientu wymaga najmniejszej ilości pamięci i jest również najwolniejsze. W przeciwieństwie do tej metody Newtona wymaga większej mocy obliczeniowej. Biorąc to wszystko pod uwagę, najlepiej nadaje się metoda Quasi-Newtona.
Polecane artykuły
Jest to przewodnik po algorytmach sieci neuronowej. Tutaj omawiamy także przegląd algorytmu sieci neuronowej wraz z czterema różnymi algorytmami. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Uczenie maszynowe a sieć neuronowa
- Ramy uczenia maszynowego
- Sieci neuronowe a głębokie uczenie się
- K- oznacza algorytm grupowania
- Przewodnik po klasyfikacji sieci neuronowej