

Wprowadzenie do Python Pandas DataFrame
Wiele rozszerzeń biblioteki Pythona, Pandy, można znaleźć w Internecie. Jednym z nich są Dane Panelu (Pan) (das). To słowo * Panel * subtelnie wskazuje na dwuwymiarową strukturę danych obecną w tej bibliotece, ogromnie wzmacniając jej użytkowników. Ta sama struktura nosi nazwę DataFrame.
Zasadniczo jest to macierz wierszy i kolumn, zawierająca cały zestaw danych, z bardzo rozbudowanymi opcjami indeksowania tego samego. DataFrame (DF) można sobie wyobrazić obrazowo bardzo podobnym do arkusza programu Excel. Ale to, co czyni go potężnym, to łatwość, z jaką operacje analityczne i transformacyjne można wykonywać na danych przechowywanych w DataFrame.
Czym dokładnie jest ramka danych Pandas Python?
Na stronie Pydata można znaleźć oficjalną definicję.
Jeśli poprawnie zrozumiany, wspomina DataFrame jako strukturę kolumnową, zdolną do przechowywania dowolnego obiektu pytona (w tym samego DataFrame) jako jednej wartości komórki. (Komórka jest indeksowana przy użyciu unikalnej kombinacji wierszy i kolumn)
DataFrames składa się z trzech podstawowych elementów: danych, wierszy i kolumn.
- Dane: odnosi się do rzeczywistych obiektów / podmiotów przechowywanych w komórce w DataFrame i wartości reprezentowanych przez te podmioty. Obiekt jest dowolnego poprawnego typu danych Pythona, zarówno wbudowanego, jak i zdefiniowanego przez użytkownika.
- Wiersze: odniesienia używane do identyfikacji (lub indeksowania) określonego zestawu obserwacji z pełnych danych przechowywanych w DataFrame są nazywane wierszami. Żeby było jasne, reprezentuje zastosowane wskaźniki, a nie tylko dane w konkretnej obserwacji.
- Kolumny: odwołania używane do identyfikacji (lub indeksowania) zestawu atrybutów dla wszystkich obserwacji w ramce danych. Podobnie jak w przypadku wierszy, odnoszą się one do indeksu kolumny (lub nagłówków kolumn) zamiast tylko danych w kolumnie.
Więc bez zbędnych ceregieli wypróbujmy kilka sposobów tworzenia tych niesamowicie potężnych struktur.
Kroki tworzenia ramek danych Pandas w języku Python
Python Pandas DataFrame można utworzyć za pomocą następującej implementacji kodu,
1. Importuj pandy
Aby utworzyć DataFrames, należy zaimportować bibliotekę pand (nie jest to zaskoczeniem). Zaimportujemy go z aliasem pd, aby wygodnie odwoływać się do obiektów w module.
Kod:
import pandas as pd
2. Tworzenie pierwszego obiektu DataFrame
Po zaimportowaniu biblioteki wszystkie metody, funkcje i konstruktory są dostępne w obszarze roboczym. Spróbujmy więc utworzyć waniliową ramkę DataFrame.
Kod:
import pandas as pd
df = pd.DataFrame()
print(df)
Wynik:
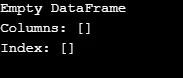
Jak pokazano w danych wyjściowych, konstruktor zwraca pustą ramkę danych.
Skupmy się teraz na tworzeniu ramek danych z danych przechowywanych w niektórych prawdopodobnych reprezentacjach.
- DataFrame ze słownika: Załóżmy, że mamy słownik przechowujący listę firm w domenie programowej i liczbę lat ich aktywności.
Kod:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Zobaczmy reprezentację zwróconego obiektu DataFrame, drukując go na konsoli.
Wynik:

Jak widać, każdy klucz słownika jest traktowany jako kolumna w DataFrame, a indeksy wierszy są generowane automatycznie, zaczynając od 0. Całkiem proste huh!
Powiedzmy, że chcesz nadać mu indeks niestandardowy zamiast 0, 1, 4. Musisz tylko przekazać żądaną listę jako parametr do konstruktora, a pandy zrobią to, co potrzebne.
Kod:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Wynik:
Wiek firmy
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Teraz możesz ustawić indeksy wierszy na dowolną żądaną wartość.
- DataFrame z pliku CSV: Stwórzmy plik CSV zawierający te same dane, co w przypadku naszego słownika. Nazwijmy plik CompanyAge.csv
Google, 21 lat
Amazonka, 23
Infosys, 38
Directi, 22
Plik można załadować do ramki danych (zakładając, że jest obecny w bieżącym katalogu roboczym) w następujący sposób.
Kod:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Wynik:
Wiek firmy
0 Google 21
1 Amazonka 23
2 Infosys 38
3 Directi 22
Ustawienie nazw parametrów , pomijając listę wartości, przypisuje je jako nagłówki kolumn w tej samej kolejności, w jakiej znajdują się na liście. Podobnie indeksy wierszy można ustawić, przekazując listę do parametru indeksu, jak pokazano w poprzedniej sekcji. Nagłówek = Brak oznacza brak nagłówków kolumn w pliku danych.
Powiedzmy teraz, że nazwy kolumn były częścią pliku danych. Następnie ustawienie nagłówka = False wykona wymagane zadanie.
3. CompanyAgeWithHeader.csv
Firma, wiek
Google, 21 lat
Amazonka, 23
Infosys, 38
Directi, 22
Kod zmieni się na
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Wynik:
Wiek firmy
0 Google 21
1 Amazonka 23
2 Infosys 38
3 Directi 22
- DataFrame z pliku Excel: Często dane są udostępniane w plikach Excela, ponieważ pozostają najpopularniejszym narzędziem używanym przez zwykłych ludzi do śledzenia AdHoc. Dlatego nie powinno się tego ignorować w naszej dyskusji.
Załóżmy, że dane, takie same jak w CompanyAgeWithHeader.csv, są teraz przechowywane w CompanyAgeWithHeader.xlsx, w arkuszu o nazwie Company Age. Te same DataFrame jak powyżej zostaną utworzone przez następujący kod.
Kod:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Wynik:
Wiek firmy
0 Google 21
1 Amazonka 23
2 Infosys 38
3 Directi 22
Jak widać, tę samą ramkę danych można utworzyć, przekazując nazwę pliku i nazwę arkusza.
Dalsza lektura i kolejne kroki
Pokazane metody stanowią bardzo mały podzbiór w porównaniu do wszystkich różnych sposobów tworzenia ramek danych. Zostały one utworzone z myślą o rozpoczęciu. Zdecydowanie powinieneś zbadać wymienione odniesienia i spróbować odkryć inne sposoby, w tym połączenie z bazą danych w celu odczytania danych bezpośrednio do DataFrame.
Wniosek
Pandas DataFrame okazał się przełomem w świecie Data Science i Data Analytics, a także jest wygodny w krótkoterminowych projektach ad-hoc. Jest wyposażony w armię narzędzi umożliwiających krojenie i krojenie zestawu danych z niezwykłą łatwością. Mamy nadzieję, że będzie to kamień milowy w dalszej podróży.
Polecane artykuły
Jest to przewodnik po Python-Pandas DataFrame. Tutaj omawiamy kroki tworzenia ramki danych pand python-pandas wraz z implementacją kodu. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- 15 najważniejszych funkcji Pythona
- Różne typy zestawów Python
- Top 4 typy zmiennych w Pythonie
- 6 najlepszych redaktorów Pythona
- Tablice w strukturze danych