

Wprowadzenie do ANOVA w R
Poniższy artykuł ANOVA w R zawiera zarys porównania średnich wartości różnych grup. Analiza wariancji (ANOVA) jest bardzo popularną techniką stosowaną do porównywania średniej wartości różnych grup. Model ANOVA służy do testowania hipotez, w którym dla populacji generowane jest pewne założenie lub parametr, a metoda statystyczna służy do ustalenia, czy hipoteza jest prawdziwa czy fałszywa.
Hipoteza wywodzi się z założenia badacza i dostępnych informacji o populacji. ANOVA nazywa się analizą wariancji i jest wykorzystywana do testowania hipotez, w których należy zmierzyć średnie zmiennej w wielu niezależnych grupach.
Na przykład w laboratorium do badania lub wynalezienia nowego leku na otyłość naukowcy porównają wyniki leczenia eksperymentalnego i standardowego. W badaniu otyłości można uzyskać cenne wyniki, gdy średni wskaźnik otyłości populacji można porównać w różnych grupach wiekowych. W tym przypadku chciałoby się zaobserwować średni wskaźnik otyłości wśród różnych grup wiekowych, takich jak wiek (od 5 do 18 lat), (19, 35) i (od 36 do 50). Zastosowano metodę ANOVA, ponieważ istnieją więcej niż dwie grupy, które są niezależne. Metoda ANOVA służy do porównania średniej otyłości niezależnych grup. Używana jest funkcja aov (), a składnia to aov (formuła, dane = ramka danych) W tym artykule dowiemy się o modelu ANOVA i omówimy dalej jednokierunkowy i dwukierunkowy model ANOVA wraz z przykładami.
Dlaczego ANOVA?
- Ta technika służy do odpowiedzi na hipotezę podczas analizy wielu grup danych. Istnieje wiele podejść statystycznych, jednak ANOVA w R jest stosowana, gdy trzeba dokonać porównania na więcej niż dwóch niezależnych grupach, tak jak w naszym poprzednim przykładzie trzy różne grupy wiekowe.
- Technika ANOVA mierzy średnią niezależnych grup, aby zapewnić badaczom wynik hipotezy. Aby uzyskać dokładne wyniki, należy wziąć pod uwagę średnie, wielkość próby i odchylenie standardowe dla każdej grupy.
- Można porównać średnią dla każdej z trzech grup do porównania. Jednak to podejście ma ograniczenia i może okazać się nieprawidłowe, ponieważ te trzy porównania nie uwzględniają danych całkowitych, a zatem mogą prowadzić do błędu typu 1. R zapewnia nam funkcję do przeprowadzania analizy ANOVA w celu zbadania zmienności między niezależnymi grupami danych. Istnieje pięć etapów analizy ANOVA. W pierwszym etapie dane są uporządkowane w formacie csv, a kolumna jest generowana dla każdej zmiennej. Jedna z kolumn byłaby zmienną zależną, a pozostałe to zmienna niezależna. W drugim etapie dane są odczytywane w R studio i odpowiednio nazywane. W trzecim etapie zestaw danych jest dołączany do poszczególnych zmiennych i odczytywany przez pamięć. Wreszcie, ANOVA w R jest zdefiniowana i analizowana. W poniższych sekcjach przedstawiłem kilka przykładów studiów przypadku, w których należy zastosować techniki ANOVA.
- Sześć insektycydów przetestowano na 12 polach, a naukowcy policzyli liczbę błędów, które pozostały na każdym polu. Teraz rolnicy muszą wiedzieć, czy insektycydy mają jakąkolwiek różnicę, a jeśli tak, to z którego najlepiej będą korzystać. Odpowiadasz na to pytanie za pomocą funkcji aov () w celu wykonania ANOVA.
- Pięćdziesięciu pacjentów otrzymało jeden z pięciu leków zmniejszających poziom cholesterolu (trt). Trzy stany leczenia obejmowały ten sam lek, który podawano 20 mg raz dziennie (1 raz) 10 mg dwa razy dziennie (2 razy) 5 mg cztery razy dziennie (4 razy). Dwa pozostałe warunki (drugD i drugE) reprezentowały konkurencyjne leki. Które leczenie farmakologiczne spowodowało największą redukcję cholesterolu (odpowiedź)?
ANOVA One-Way
- Metoda jednokierunkowa jest jedną z podstawowych technik ANOVA, w której stosuje się analizę wariancji i porównuje średnią wartość wielu grup populacji.
- Jednokierunkowa ANOVA ma swoją nazwę ze względu na dostępność danych klasyfikowanych w jedną stronę. W jednokierunkowej ANOVA może być dostępna jedna zmienna zależna i jedna lub więcej zmiennych niezależnych.
- Na przykład wykonamy technikę ANOVA na zbiorze danych cholesterolu. Zestaw danych składa się z dwóch zmiennych trt (które są zabiegami na 5 różnych poziomach) i zmiennych odpowiedzi. Zmienna niezależna - grupy leczenia uzależnień, zmienna zależna - średnia z 2 lub więcej grup ANOVA. Na podstawie tych wyników można potwierdzić, że przyjmowanie dawek 5 mg 4 razy dziennie było lepsze niż przyjmowanie dawki dwudziestu mg raz dziennie. Lek D ma lepsze działanie w porównaniu do tego leku E.
Lek D zapewnia lepsze wyniki, jeśli jest przyjmowany w dawkach 20 mg w porównaniu do leku E.
Wykorzystuje zestaw danych cholesterolu w pakiecie multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Test ANOVA F dla leczenia (trt) jest istotny (p <0, 0001), dostarczając dowodów, że pięć zabiegów
# nie wszystkie są równie skuteczne.
podsumowanie (aov_model)
odłączyć (cholesterol)

Funkcja plotmeans () w pakiecie gplots może służyć do tworzenia wykresu średnich grup i przedziałów ufności. To wyraźnie pokazuje różnice w leczeniuinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
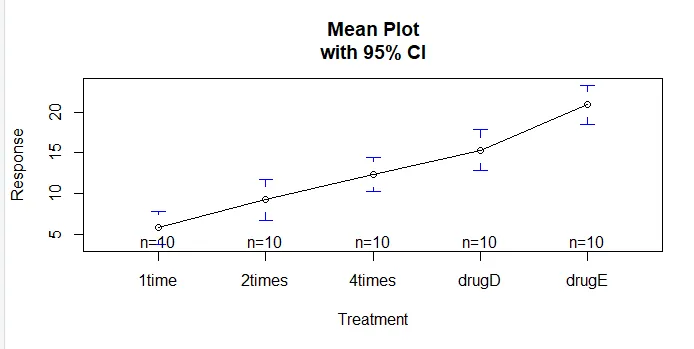
Przeanalizujmy dane wyjściowe z TukeyHSD () pod kątem różnic par pomiędzy średnimi grupowymi
TukeyHSD (aov_model)
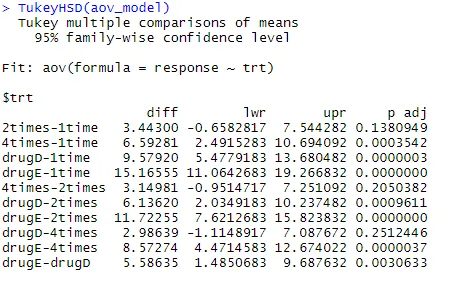
Średnie obniżenie cholesterolu 1 raz i 2 razy nie różnią się znacząco między sobą (p = 0, 138), podczas gdy różnica między 1 raz a 4 razy jest znacząco różna (p <0, 001).
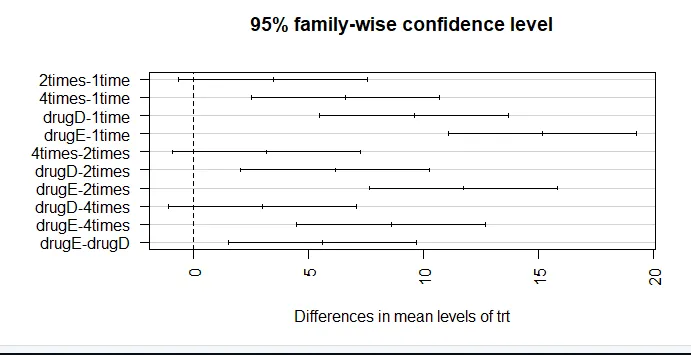
par (mar = c (5, 8, 4, 2)) # wzrost wykresu lewego marginesu (TukeyHSD (aov_model), las = 2)
Zaufanie do wyników zależy od tego, w jakim stopniu twoje dane spełniają założenia leżące u podstaw testów statystycznych. W jednostronnej ANOVA zakłada się, że zmienna zależna jest normalnie rozłożona i ma jednakową wariancję w każdej grupie. Za pomocą wykresu QQ można ocenić bibliotekę założeń normalności (samochód).
Wykres QQ (lm (odpowiedź ~ trt, dane = cholesterol), symulacja = PRAWDA, main = „Wykres QQ”, etykiety = FAŁSZ)
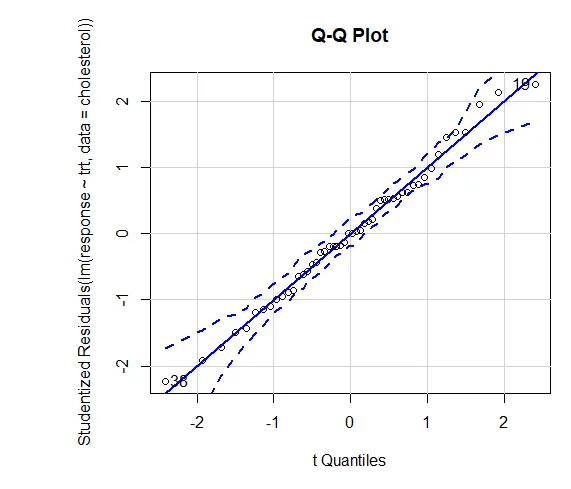
Linia przerywana = 95% przedziału ufności, co sugeruje, że założenie normalności zostało spełnione dość dobrze ANOVA zakłada, że wariancje są równe dla grup lub próbek. Test Bartletta można wykorzystać do zweryfikowania tego założenia
bartlett.test (odpowiedź ~ trt, dane = cholesterol). Test Bartletta wskazuje, że wariancje w pięciu grupach nie różnią się znacząco (p = 0, 97).
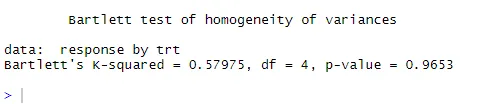
ANOVA jest również wrażliwa na test wartości odstających za pomocą funkcji outlierTest () w pakiecie samochodowym. Może nie być konieczne uruchomienie tego pakietu, aby zaktualizować bibliotekę samochodową.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
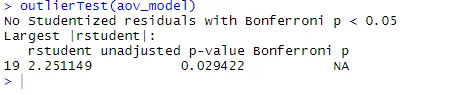
Na podstawie danych wyjściowych widać, że dane dotyczące cholesterolu nie wskazują na wartości odstające (NA występuje, gdy p> 1). Biorąc pod uwagę wykres QQ, test Bartletta i test odstający, dane wydają się całkiem dobrze pasować do modelu ANOVA.
Dwukierunkowa Anova
Kolejna zmienna jest dodawana w dwukierunkowym teście ANOVA. Gdy istnieją dwie zmienne niezależne, będziemy musieli zastosować dwukierunkową ANOVA zamiast jednokierunkowej techniki ANOVA, która została zastosowana w poprzednim przypadku, w którym mieliśmy jedną ciągłą zmienną zależną i więcej niż jedną zmienną niezależną. Aby zweryfikować dwukierunkową ANOVA, należy spełnić wiele założeń.
- Dostępność niezależnych obserwacji
- Obserwacje powinny być normalnie rozpowszechniane
- Odchylenie powinno być równe w obserwacjach
- Wartości odstające nie powinny być obecne
- Niezależne błędy
Aby zweryfikować dwukierunkową ANOVA, do zestawu danych dodawana jest inna zmienna o nazwie BP. Zmienna wskazuje tempo ciśnienia krwi u pacjentów. Chcielibyśmy sprawdzić, czy istnieje jakakolwiek różnica statystyczna między BP a dawką podawaną pacjentom.
df <- read.csv („plik.csv”)
df
anova_two_way <- aov (odpowiedź ~ trt + BP, dane = df)
podsumowanie (anova_two_way)
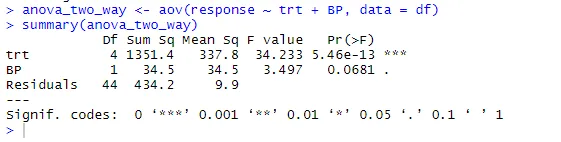
Z danych wyjściowych można wywnioskować, że zarówno trt, jak i BP różnią się statystycznie od 0. Stąd hipotezę zerową można odrzucić.
Korzyści z ANOVA w R.
Test ANOVA określa różnicę średniej między dwiema lub więcej niezależnymi grupami. Ta technika jest bardzo przydatna do analizy wielu pozycji, która jest niezbędna do analizy rynku. Za pomocą testu ANOVA można uzyskać niezbędne dane z danych. Na przykład podczas ankiety dotyczącej produktu, w której gromadzone są różne informacje, takie jak listy zakupów, upodobania klientów i niechęci. Test ANOVA pomaga nam porównywać grupy populacji. Grupą może być mężczyzna lub kobieta lub różne grupy wiekowe. Technika ANOVA pomaga rozróżnić średnie wartości różnych grup populacji, które są rzeczywiście różne.
Wniosek - ANOVA w R.
ANOVA jest jedną z najczęściej stosowanych metod testowania hipotez. W tym artykule przeprowadziliśmy test ANOVA na zbiorze danych składającym się z pięćdziesięciu pacjentów, którzy otrzymywali leki obniżające poziom cholesterolu, a także widzieliśmy, jak można wykonać dwukierunkową ANOVA, gdy dostępna jest dodatkowa niezależna zmienna.
Polecane artykuły
To jest przewodnik po ANOVA w R. Tutaj omawiamy jednokierunkowy i dwukierunkowy model Anova wraz z przykładami i zaletami ANOVA. Możesz także przejrzeć nasze inne sugerowane artykuły -
- Regresja vs ANOVA
- Co to jest SPSS?
- Jak interpretować wyniki za pomocą testu ANOVA
- Funkcje w R.