

Co to jest AWS Kinesis?
Kinesis to platforma, która pomaga w gromadzeniu, przetwarzaniu i analizie danych przesyłanych strumieniowo w Amazon Web Services. Strumieniowe przesyłanie danych to duża ilość danych pochodzących z różnych źródeł, takich jak media społecznościowe, czujniki IoT, prognoza pogody, opieka zdrowotna itp. Są one wykorzystywane w budowaniu aplikacji opartych na wymaganiach użytkownika. Niektóre z typowych aplikacji to analizy predykcyjne w Big Data, Machine Learning itp. W tym temacie dowiemy się o AWS Kinesis.
Usługi AWS Kinesis
Zanim przejdziemy do usług, najpierw zrozummy niektóre terminologie stosowane w Kinesis.
Terminologia
| Semestr | Definicja |
| Zapis danych | Jednostka danych przechowywana w strumieniu danych Kinesis. Składa się z obiektu blob danych, numeru sekwencji i klucza partycji |
| Czerep | Zestaw sekwencji rekordów danych. Liczba odłamków może zostać zwiększona lub zmniejszona, jeśli szybkość transmisji danych zostanie zwiększona. |
| Okres przechowywania | Okres, w którym dane mogą być dostępne po dodaniu do strumienia.
Domyślny okres przechowywania: 24 godziny |
| Producent | Dostarcza rekordy danych do strumienia Kinesis |
| Konsument | Pobiera rekordy z Kinesis Stream i przetwarza je. |
Kinesis zapewnia 3 podstawowe usługi. Oni są:
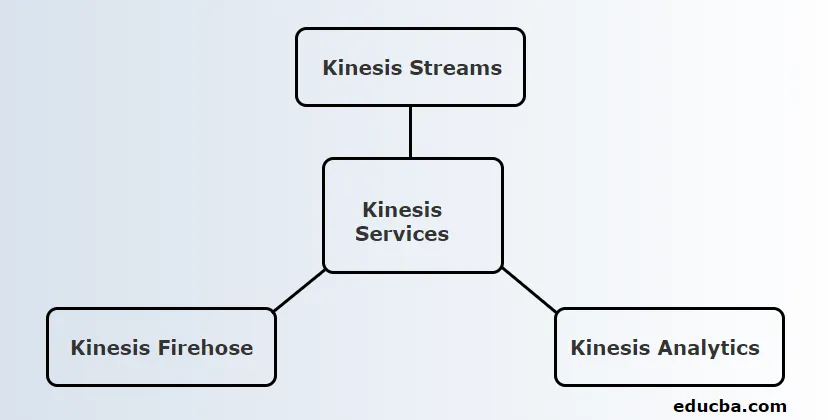
1. Strumienie kinezy
Strumień Kinesis składa się z zestawu sekwencji rekordów danych zwanych odłamkami. Odłamki te mają stałą pojemność, która może zapewnić maksymalną szybkość odczytu 2 MB / sekundę i szybkość zapisu 1 MB / sekundę. Maksymalna pojemność strumienia jest sumą pojemności każdego odłamka.
Działanie kinezy:
- Dane wytwarzane przez Internet Rzeczy i inne źródła znane jako Producenci są wprowadzane do strumieni Kinesis w celu przechowywania w Odłamkach.
- Te dane będą dostępne w odłamku przez maksymalnie 24 godziny.
- Jeśli musi być przechowywany dłużej niż ten domyślny czas, użytkownik może wydłużyć do 7-dniowego okresu przechowywania.
- Gdy dane dotrą do odłamków, instancje EC2 mogą wziąć te dane do różnych celów.
- Instancje EC2, które pobierają dane, są znane jako Konsumenci.
- Po przetworzeniu dane są przekazywane do jednej z usług internetowych Amazon, takich jak Simple Storage Service (S3), DynamoDB, Redshift itp.
2. Kinesis Firehose
Kinesis Firehose jest pomocny w przenoszeniu danych do serwisów Amazon, takich jak Redshift, prosta usługa przechowywania, wyszukiwanie elastyczne itp. Jest to część platformy przesyłania strumieniowego, która nie zarządza żadnymi zasobami. Producenci danych są skonfigurowani w taki sposób, że dane muszą być wysyłane do Kinesis Firehose, a następnie automatycznie wysyła je do odpowiedniego miejsca docelowego.
Działanie Kinesis Firehose:
- Jak wspomniano w pracy AWS Kinesis Streams, Kinesis Firehose pobiera również dane od producentów, takich jak telefony komórkowe, laptopy, EC2 itp. Ale to nie musi uwzględniać danych w odłamkach ani wydłużać okresów przechowywania, takich jak strumienie Kinesis. To dlatego, że Kinesis Firehose robi to automatycznie.
- Dane są następnie analizowane automatycznie i wprowadzane do Simple Storage Service
- Ponieważ nie ma okresu przechowywania, dane muszą zostać przeanalizowane lub wysłane do dowolnego miejsca zależnego od wymagań użytkownika.
- Jeśli dane muszą zostać wysłane do Redshift, należy je najpierw przenieść do Simple Storage Service i stamtąd skopiować je do Redshift.
- Jednak w przypadku wyszukiwania elastycznego dane mogą być bezpośrednio do niego wprowadzane, podobnie jak w przypadku usługi Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose pozwala na uruchamianie zapytań SQL w danych obecnych w Kinesis Firehose. Za pomocą tych zapytań SQL dane mogą być przechowywane w Redshift, Simple Storage Service, ElasticSearch itp.
Architektura AWS Kinesis
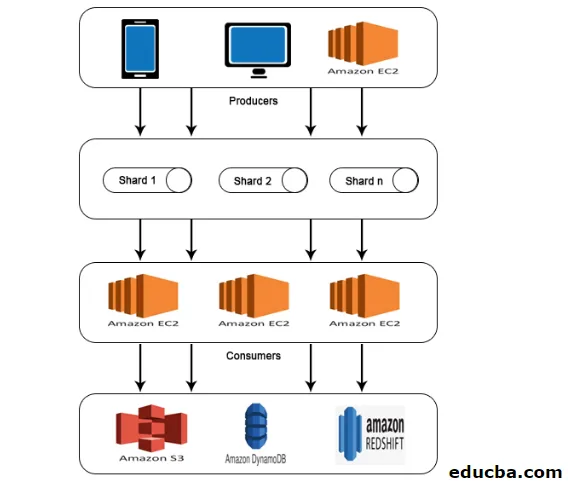
Architektura AWS Kinesis składa się z
- Producenci
- Odłamki
- Konsumenci
- Przechowywanie
Podobnie do pracy wyjaśnionej w AWS Kinesis Data Stream, dane od producentów są wprowadzane do odłamków, gdzie dane są przetwarzane i analizowane. Analizowane dane są następnie przenoszone do instancji EC2 w celu wykonania niektórych aplikacji. W końcu dane będą przechowywane w dowolnej usłudze internetowej Amazon, takiej jak S3, Redshift itp.
Jak korzystać z kinezy AWS?
Aby pracować z AWS Kinesis, należy wykonać następujące dwa kroki.
1. Zainstaluj interfejs wiersza polecenia AWS (CLI).
Instalowanie interfejsu wiersza polecenia jest różne dla różnych systemów operacyjnych. Tak więc zainstaluj CLI w zależności od systemu operacyjnego.
W przypadku użytkowników systemu Linux użyj polecenia sudo pip install AWS CLI
Upewnij się, że masz Python w wersji 2.6.5 lub nowszej. Po pobraniu skonfiguruj go za pomocą polecenia AWS config. Następnie zostaną wyświetlone następujące szczegóły, jak pokazano poniżej.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
W przypadku użytkowników systemu Windows pobierz odpowiedni Instalator MSI i uruchom go.
2. Wykonaj operacje kinezy za pomocą interfejsu CLI
Należy pamiętać, że strumienie danych Kinesis nie są dostępne dla warstwy wolnej od AWS. Tak więc utworzone strumienie Kinesis zostaną obciążone.
Zobaczmy teraz kilka operacji kinezy w CLI.
- Utwórz strumień
Utwórz strumień KStream za pomocą Shard count 2 za pomocą następującego polecenia.
aws kinesis create-stream --stream-name KStream --shard-count 2
Sprawdź, czy strumień został utworzony.
aws kinesis describe-stream --stream-name KStream
Jeśli zostanie utworzony, pojawi się wynik podobny do poniższego przykładu.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Umieść rekord
Teraz rekord danych można wstawić za pomocą polecenia put-record. Tutaj rekord zawierający test danych jest wstawiany do strumienia.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Jeśli wstawianie zakończy się powodzeniem, dane wyjściowe zostaną wyświetlone, jak pokazano poniżej.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Uzyskaj rekord
Najpierw użytkownik musi uzyskać iterator niezależnego fragmentu, który reprezentuje pozycję strumienia dla niezależnego fragmentu.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Następnie uruchom polecenie, używając uzyskanego iteratora odłamków.
aws kinesis get-records --shard-iterator ###########
Próbka wyjściowa zostanie uzyskana, jak pokazano poniżej.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Sprzątać
Aby uniknąć opłat, utworzony strumień można usunąć za pomocą poniższego polecenia.
aws kinesis delete-stream --stream-name KStream
Wniosek
AWS Kinesis to platforma, która gromadzi, przetwarza i analizuje dane strumieniowe dla wielu aplikacji, takich jak uczenie maszynowe, analizy predykcyjne i tak dalej. Dane przesyłane strumieniowo mogą mieć dowolny format, np. Audio, wideo, dane z czujników itp.
Polecane artykuły
To jest przewodnik po AWS Kinesis. Tutaj omawiamy sposób korzystania z AWS Kinesis, a także jego usługi z działaniem i architekturą. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Architektura AWS
- Co to jest AWS Lambda?
- Technologie Big Data
- Architektura Data Mining
- Usługi pamięci masowej AWS
- Przewodnik dla konkurentów AWS z funkcjami