

Różnica między Hadoop a HBase
Hadoop to platforma Java typu open source, używana do zarządzania i przetwarzania ogromnej ilości ustrukturyzowanych i nieustrukturyzowanych danych. Hadoop jest ogromnie skalowalny, dlatego służy do przetwarzania obciążeń dużych zbiorów danych. Duże dane są przechowywane, dostępne i przetwarzane w niezawodnym i rozszerzalnym klastrze. HBase (baza danych Hadoop) to nierelacyjna i nie tylko SQL, tj. Baza danych NoSQL, która działa na szczycie Hadoop jako rozproszona i skalowalna przechowalnia dużych zbiorów danych. Jest to baza danych typu open source, w której dane są przechowywane w postaci wierszy i kolumn, w tej komórce znajduje się przecięcie kolumn i wierszy.
Poniżej znajdują się podstawowe elementy architektury Hadoop:
- Hadoop Distributed File System (HDFS): Hadoop obejmuje rozproszony system pamięci masowej, Hadoop Distributed File System (HDFS). HDFS to architektura master-slave, która przechowuje dane w klastrze. Dane dystrybuowane w kilku węzłach podrzędnych przez węzeł główny w bloku formularza. Węzeł główny nazywa się Namenode, a węzły podrzędne nazywa się Datanode. HDFS można łatwo rozbudowywać i przechowuje ogromną ilość danych w Datanodes. HDFS ma konfigurowalny współczynnik replikacji z wartością domyślną 3, którą można edytować.
- MapReduce: MapReduce to paradygmat programowania, przetwarzany równolegle w ogromnej liczbie zestawów danych w sieci. MapReduce odnosi się do dwóch różnych zadań: odwzorowanie danych wejściowych, w których dane podzielone na podzbiór danych zwanych krotkami i zadanie redukcji, pobierają te krotki z mapy jako dane wejściowe i łączą się, tworząc dane wyjściowe oryginału.
- Przędza: YARN oznacza jeszcze jeden nawigator zasobów, który oblicza zasoby, takie jak zarządzanie procesorem i pamięcią, planowanie żądań zasobów.
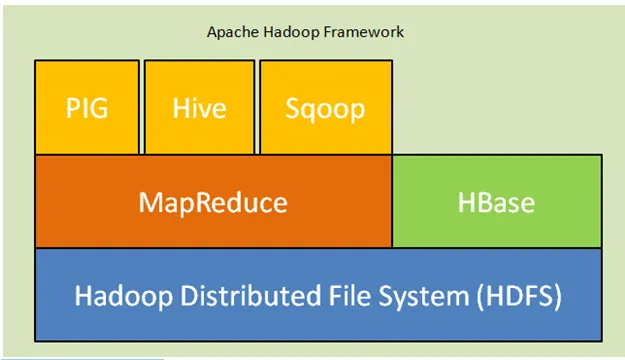
Ryc. Apache Hadoop Framework
Serwer regionu udostępnia dane do operacji odczytu / zapisu. Wszystkie dane HBase są przechowywane w pliku HDFS. HDFS Datanode przechowuje dane, którymi zarządza serwer regionalny. Tryb nazw HDFS przechowuje informacje o metadanych dla wszystkich fizycznych bloków danych, które składają się na pliki.
Wersjonowanie służy do śledzenia zmian w komórkach, co pozwala śledzić wersję zawartości. Z tego można pobrać dowolną wersję treści. Każda wartość komórki zawiera atrybut „wersja” w odniesieniu do znacznika czasu w celu pobrania komórki. Każda wartość na mapie to nieprzerwana tablica bajtów. Mapa jest indeksowana za pomocą klucza wiersza, klucza kolumny i znacznika czasu. Architektura HBase to wysoce skalowalne, rzadkie, rozproszone, trwałe i wielowymiarowe mapy sortowane.
Bezpośrednie porównanie między Hadoop a HBase (infografiki)
Poniżej znajduje się 7 najlepszych różnic między Hadoop a HBase
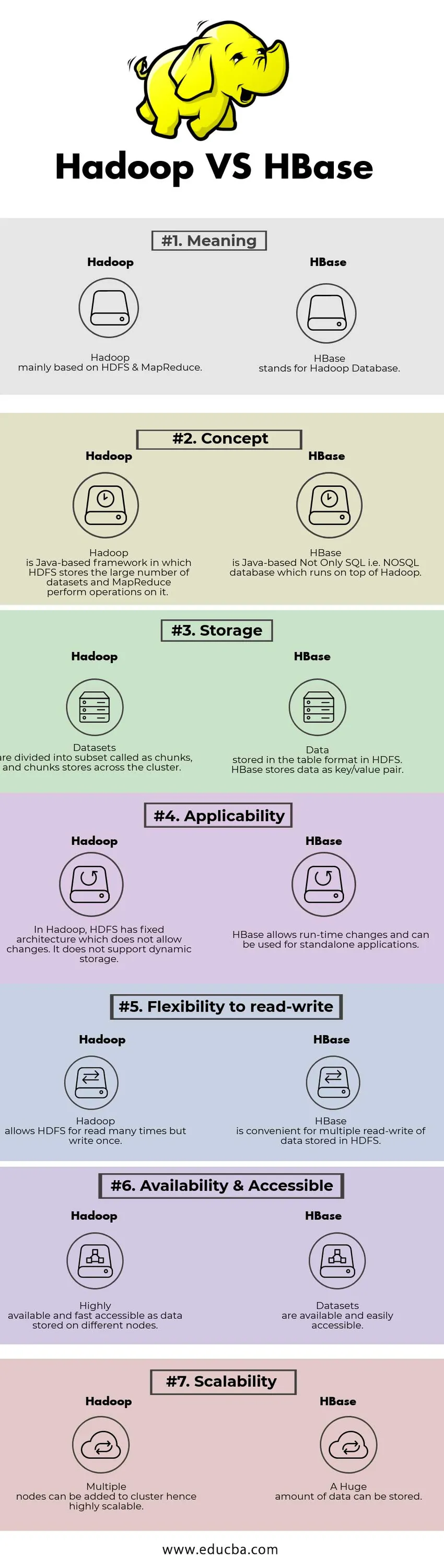
Kluczowe różnice między Hadoop a HBase
Różnicę między Hadoop i HBase wyjaśniono w punktach przedstawionych poniżej:
- Hadoop nie nadaje się do przetwarzania analitycznego online (OLAP), a HBase jest częścią ekosystemu Hadoop, który zapewnia losowy dostęp w czasie rzeczywistym (odczyt / zapis) do danych w systemie plików Hadoop.
- Struktura Hadoop jest z założenia odporna na uszkodzenia i obsługuje szybki transfer danych między węzłami nawet podczas awarii systemu. HBase to nierelacyjna i otwarta baza danych typu Non-Only-SQL, która działa na platformie Hadoop. HBase podlega twierdzeniu typu CAP (spójność, dostępność i tolerancja partycji) typu CP.
- Hadoop jest najbardziej odpowiedni do przeprowadzania analiz partii. Jednak jedną z jego największych wad jest niemożność przeprowadzania analiz w czasie rzeczywistym, co jest trendem w branży IT. Z kolei HBase może obsługiwać duże zestawy danych i nie jest odpowiedni do analizy wsadowej. Zamiast tego służy do zapisywania / odczytywania danych z Hadoop w czasie rzeczywistym.
- Zarówno Hadoop, jak i HBase są w stanie przetwarzać zarówno ustrukturyzowane, częściowo ustrukturyzowane, jak i nieustrukturyzowane dane. W Hadoop HDFS nie ma silnika przetwarzania w pamięci, który spowalnia proces analizy danych; ponieważ używa do tego zwykłego starego MapReduce. Przeciwnie, HBase posiada silnik przetwarzania w pamięci, który drastycznie zwiększa prędkość odczytu / zapisu.
- Hadoop jest bardzo przejrzysty w wykonywaniu analizy danych. Z kolei HBase, będąc bazą danych NoSQL w formacie tabelarycznym, pobiera wartości, sortując je według różnych wartości kluczowych.
Tabela porównawcza Hadoop vs HBase
| PODSTAWA DO PORÓWNANIA | Hadoop | HBase |
| Znaczenie | Hadoop oparty głównie na HDFS i MapReduce. | HBase oznacza Hadoop Database. |
| Pojęcie | Hadoop to framework oparty na Javie, w którym HDFS przechowuje dużą liczbę zestawów danych, a MapReduce wykonuje na nim operacje. | HBase to nie tylko SQL oparta na Javie, tj. Baza danych NoSQL działająca na platformie Hadoop. |
| Przechowywanie | Zestawy danych są podzielone na podzbiór zwany fragmentami, a fragmenty są przechowywane w klastrze. | Dane przechowywane w formacie tabeli w HDFS. HBase przechowuje dane jako parę klucz / wartość. |
| Możliwość zastosowania | W Hadoop HDFS ma poprawioną architekturę, która nie pozwala na zmiany. Nie obsługuje pamięci dynamicznej. | HBase umożliwia zmiany w czasie wykonywania i może być używany do samodzielnych aplikacji. |
| Elastyczność odczytu i zapisu | Hadoop pozwala HDFS na wielokrotne czytanie, ale pisanie raz. | HBase jest wygodny do wielokrotnego odczytu i zapisu danych przechowywanych w HDFS |
| Dostępność i dostępność | Wysoce dostępne i szybko dostępne jako dane przechowywane w różnych węzłach. | Zestawy danych są dostępne i łatwo dostępne |
| Skalowalność | Do węzła można dodawać wiele węzłów, dzięki czemu jest wysoce skalowalny. | Można przechowywać ogromną ilość danych. |
Wniosek - Hadoop vs HBase
Architektura Hadoop oparta głównie na HDFS i MapReduce. HBase jest komponentem wspierającym w systemie Hadoop. HBase może obsługiwać ogromne tabele i zapewnia szybki losowy dostęp do dostępnych danych, podczas gdy HDFS nadaje się do przechowywania dużych plików. Zarówno Hadoop, jak i HBase zapewniają szybki dostęp do danych, ale dzięki HBase operacje odczytu / zapisu mogą być wykonywane, a dla HDFS odczyt wiele razy, a raz zapis. W tym artykule opisano zrozumienie Hadoop i HBase, krótko wyróżniono funkcje i mądrze porównano.
Polecany artykuł
- Apache Hadoop vs Apache Spark | 10 najlepszych porównań, które musisz znać!
- Hadoop vs Hive - Znajdź najlepsze różnice
- HBase vs Cassandra - Który z nich jest lepszy (infografiki)
- Top 12 Porównanie Apache Hive vs Apache HBase (infografiki)
- Hadoop vs Spark: jakie są funkcje