

Wprowadzenie do drzewa decyzyjnego w eksploracji danych
W dzisiejszym świecie „Big Data” termin „Data Mining” oznacza, że musimy przyjrzeć się dużym zbiorom danych i przeprowadzić „eksplorację” danych oraz wydobyć ważny sok lub esencję tego, co dane chcą powiedzieć. Bardzo analogiczną sytuacją jest wydobycie węgla, gdzie do wydobywania węgla zakopanego głęboko pod ziemią potrzebne są różne narzędzia. Jednym z narzędzi w eksploracji danych jest „Drzewo decyzyjne”. Zatem eksploracja danych sama w sobie jest rozległym obszarem, w którym w następnych kilku akapitach zagłębimy się w „narzędzie” drzewa decyzyjnego w Data Mining.
Algorytm drzewa decyzyjnego w eksploracji danych
Drzewo decyzyjne jest nadzorowanym podejściem do uczenia się, w którym uczymy obecne dane, wiedząc już, czym jest zmienna docelowa. Jak sama nazwa wskazuje, ten algorytm ma strukturę typu drzewa. Najpierw przyjrzyjmy się teoretycznemu aspektowi drzewa decyzyjnego, a następnie przyjrzyjmy się temu samemu w podejściu graficznym. W drzewie decyzyjnym algorytm dzieli zestaw danych na podzbiory na podstawie najważniejszego lub najistotniejszego atrybutu. Najistotniejszy atrybut jest wyznaczony w węźle głównym i to tam następuje podział całego zestawu danych obecnego w węźle głównym. Wykonany podział jest znany jako węzły decyzyjne. W przypadku, gdy nie jest już możliwe podzielenie, węzeł ten jest nazywany węzłem liścia.
Aby zatrzymać algorytm, aby osiągnął przytłaczający etap, stosuje się kryterium zatrzymania. Jednym z kryteriów zatrzymania jest minimalna liczba obserwacji w węźle przed podziałem. Podczas stosowania drzewa decyzyjnego przy dzieleniu zestawu danych należy uważać, aby wiele węzłów mogło po prostu mieć zaszumione dane. Aby zaspokoić niejednoznaczne lub hałaśliwe problemy z danymi, stosujemy techniki znane jako przycinanie danych. Obcinanie danych jest niczym innym jak algorytmem do klasyfikowania danych z podzbioru, co utrudnia naukę na podstawie danego modelu.
Algorytm drzewa decyzyjnego został wydany jako ID3 (iteracyjny dychotomiser) przez badacza maszyn J. Ross Quinlan. Później C4.5 został wydany jako następca ID3. Zarówno ID3, jak i C4.5 są chciwym podejściem. Przyjrzyjmy się teraz schematowi działania algorytmu drzewa decyzyjnego.
Dla naszego zrozumienia pseudokodu, przyjmowalibyśmy punkty danych „n”, z których każdy ma atrybuty „k”. Poniżej przedstawiono schemat blokowy, biorąc pod uwagę „Zysk informacji” jako warunek podziału.
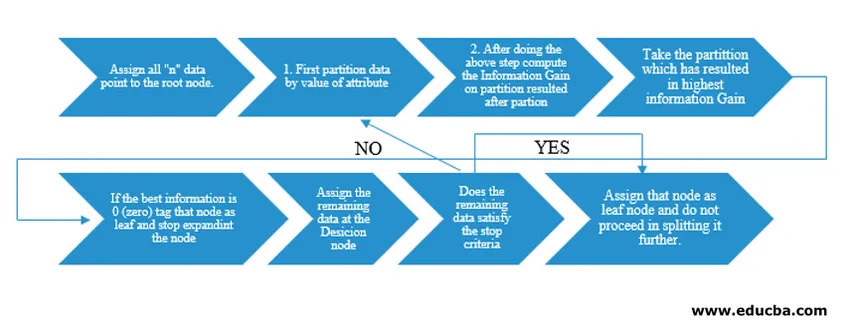
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Zamiast zdobywania informacji (IG), możemy również zastosować indeks Gini jako kryteria podziału. Aby zrozumieć różnicę między tymi dwoma kryteriami w kategoriach laika, możemy pomyśleć o uzyskaniu Informacji jako Różnicy Entropii przed podziałem i po podziale (podział na podstawie wszystkich dostępnych funkcji).
Entropia jest jak losowość i osiągnęlibyśmy punkt po podziale, aby mieć najmniejszy stan losowości. W związku z tym pozyskiwanie informacji musi być największe na temat funkcji, którą chcemy podzielić. W przeciwnym razie, jeśli chcemy wybrać podział na podstawie indeksu Gini, znaleźlibyśmy indeks Gini dla różnych atrybutów i korzystając z tego samego, uzyskamy ważony indeks Gini dla różnych podziałów i użyj tego z wyższym indeksem Gini do podzielenia zestawu danych.
Ważne warunki drzewa decyzyjnego w Data Mining
Oto niektóre z ważnych terminów drzewa decyzyjnego w eksploracji danych podane poniżej:
- Węzeł główny: jest to pierwszy węzeł, w którym następuje podział.
- Węzeł liścia: Jest to węzeł, po którym nie ma już rozgałęzień.
- Węzeł decyzyjny: Węzeł utworzony po podzieleniu danych z poprzedniego węzła jest znany jako węzeł decyzyjny.
- Gałąź: Podsekcja drzewa zawierająca informacje o następstwie podziału w węźle decyzyjnym.
- Przycinanie: Gdy usuwa się podwęzły węzła decyzyjnego w celu uwzględnienia danych odstających lub hałaśliwych, nazywa się to przycinaniem. Uważa się również, że jest przeciwieństwem podziału.
Zastosowanie drzewa decyzyjnego w eksploracji danych
Drzewo decyzyjne ma architekturę typu schemat blokowy wbudowaną w typ algorytmu. Zasadniczo ma wzór „Jeśli X, a następnie Y jeszcze Z” podczas podziału. Ten typ wzorca służy zrozumieniu ludzkiej intuicji w dziedzinie programowej. Dlatego można szeroko stosować to w różnych problemach kategoryzacji.
- Algorytm ten może być szeroko stosowany w dziedzinie, w której funkcja celu jest powiązana z wykonaną analizą.
- Gdy dostępnych jest wiele sposobów działania.
- Analiza wartości odstających.
- Zrozumienie znaczącego zestawu funkcji dla całego zestawu danych i „kopanie” kilku funkcji z listy setek funkcji w dużych zbiorach danych.
- Wybór najlepszego lotu do podróży do miejsca docelowego.
- Proces decyzyjny oparty na różnych okolicznościach okolicznościowych.
- Analiza odejść.
- Analiza sentymentów.
Zalety drzewa decyzyjnego
Oto niektóre zalety drzewa decyzyjnego wyjaśnionego poniżej:
- Łatwość zrozumienia: sposób, w jaki drzewo decyzyjne jest przedstawiane w formie graficznej, ułatwia zrozumienie dla osoby nieposiadającej wiedzy analitycznej. Zwłaszcza dla osób kierujących, którzy chcą sprawdzić, które cechy są ważne, wystarczy rzut oka na drzewo decyzyjne, które może ujawnić ich hipotezę.
- Eksploracja danych: Jak omówiono, uzyskiwanie znaczących zmiennych jest podstawową funkcjonalnością drzewa decyzyjnego i przy użyciu tego samego można odkryć, która zmienna wymaga szczególnej uwagi podczas fazy eksploracji i modelowania danych podczas eksploracji danych.
- Na etapie przygotowywania danych interwencja człowieka jest bardzo niewielka, a czyszczenie zajmuje mniej czasu.
- Drzewo decyzyjne jest zdolne do obsługi zmiennych jakościowych i liczbowych, a także do rozwiązywania problemów z klasyfikacją wielu klas.
- W ramach tego założenia drzewa decyzyjne nie mają żadnych założeń na podstawie rozkładu przestrzennego i struktury klasyfikatora.
Wniosek
Wreszcie, podsumowując Drzewa decyzyjne wprowadzają zupełnie inną klasę nieliniowości i służą rozwiązaniu problemów związanych z nieliniowością. Ten algorytm jest najlepszym wyborem do naśladowania myślenia na poziomie ludzkim na poziomie decyzji i przedstawienia go w formie matematyczno-graficznej. Przyjmuje podejście odgórne przy ustalaniu wyników z nowych niewidzialnych danych i jest zgodne z zasadą dzielenia i podbijania.
Polecane artykuły
Jest to przewodnik po drzewie decyzyjnym w Data Mining. Tutaj omawiamy algorytm, znaczenie i zastosowanie drzewa decyzyjnego w eksploracji danych wraz z jego zaletami. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Uczenie maszynowe danych
- Rodzaje technik analizy danych
- Drzewo decyzyjne w R.
- Co to jest eksploracja danych?
- Przewodnik po różnych metodologiach analizy danych