
Przegląd modelowania regresji liniowej
Kiedy zaczynasz uczyć się o algorytmach uczenia maszynowego, zaczynasz uczyć się o różnych sposobach algorytmów ML, tj. Uczeniu nadzorowanym, nienadzorowanym, pół-nadzorowanym i wzmacniającym. W tym artykule zajmiemy się nadzorowanym uczeniem się i jednym z podstawowych, ale potężnych algorytmów: regresją liniową.

Dlatego uczenie nadzorowane to uczenie się, w którym uczymy maszynę, aby rozumiała związek między wartościami wejściowymi i wyjściowymi podanymi w zestawie danych szkoleniowych, a następnie używa tego samego modelu do przewidywania wartości wyjściowych dla zestawu danych testowych. Zasadniczo, jeśli mamy już dane wyjściowe lub etykiety w naszym zestawie danych szkoleniowych i jesteśmy pewni, że dane wyjściowe mają sens odpowiadający danym wejściowym, wówczas korzystamy z nauki nadzorowanej. Nadzorowane algorytmy uczenia się dzielą się na regresję i klasyfikację.
Algorytmy regresji są używane, gdy zauważysz, że dane wyjściowe są zmienną ciągłą, podczas gdy algorytmy klasyfikacji są używane, gdy dane wyjściowe są podzielone na sekcje, takie jak pozytywny / negatywny, dobry / średni / zły itp. Mamy różne algorytmy do przeprowadzania regresji lub klasyfikacji działania z algorytmem regresji liniowej będącym podstawowym algorytmem regresji.
Przechodząc do tej regresji, zanim przejdę do algorytmu, pozwól mi ustawić dla ciebie bazę. Mam nadzieję, że w szkole pamiętasz pojęcie równania liniowego. Pozwól mi krótko o tym opowiedzieć. Otrzymałeś dwa punkty na płaszczyźnie XY, tzn. Powiedzmy (x1, y1) i (x2, y2), gdzie y1 jest wyjściem x1, a y2 jest wynikiem x2, wówczas równanie linii przechodzące przez punkty to (y- y1) = m (x-x1) gdzie m jest nachyleniem linii. Teraz, po znalezieniu równania liniowego, jeśli otrzymasz punkt powiedzmy (x3, y3), to z łatwością będziesz w stanie przewidzieć, czy punkt leży na linii, czy odległość punktu od linii. To była podstawowa regresja, którą zrobiłem w szkole, nawet nie zdając sobie sprawy, że będzie to miało tak duże znaczenie w uczeniu maszynowym. Na ogół robimy w tym celu, starając się zidentyfikować linię lub krzywą równania, która może pasować odpowiednio do wejścia i wyjścia zestawu danych pociągu, a następnie użyć tego samego równania do przewidzenia wartości wyjściowej zestawu danych testowych. Spowodowałoby to ciągłą pożądaną wartość.
Definicja regresji liniowej
Regresja liniowa istnieje od bardzo dawna (około 200 lat). Jest to model liniowy, tzn. Zakłada liniową zależność między zmiennymi wejściowymi (x) a pojedynczą zmienną wyjściową (y). Tutaj y jest obliczane przez liniową kombinację zmiennych wejściowych.
Mamy dwa rodzaje regresji liniowej
Prosta regresja liniowa
Gdy występuje jedna zmienna wejściowa, tzn. Równanie liniowe to c
traktowane jako y = mx + c, wówczas jest to prosta regresja liniowa.
Wielokrotna regresja liniowa
Gdy istnieje wiele zmiennych wejściowych, tj. Równanie liniowe jest uważane za y = ax 1 + bx 2 +… nx n, wówczas jest to wielokrotna regresja liniowa. Różne techniki są wykorzystywane do przygotowania lub wyuczenia równania regresji z danych, a najbardziej popularna z nich to Zwykłe Najmniejsze Kwadraty. Model zbudowany przy użyciu wspomnianej metody jest nazywany regresją liniową metodą najmniejszych kwadratów lub regresją najmniejszych kwadratów. Model jest stosowany, gdy wartości wejściowe i wyjściowa, które mają zostać określone, są wartościami liczbowymi. Gdy jest tylko jedno wejście i jedno wyjście, wówczas utworzone równanie jest równaniem liniowym, tj
y = B0x+B1
gdzie współczynniki linii należy określić przy użyciu metod statystycznych.
Modele prostej regresji liniowej są bardzo rzadkie w ML, ponieważ ogólnie będziemy mieć różne czynniki wejściowe w celu ustalenia wyniku. Gdy istnieje wiele wartości wejściowych i jedna wartość wyjściowa, powstaje równanie równania płaszczyzny lub hiperpłaszczyzny.
y = ax 1 +bx 2 +…nx n
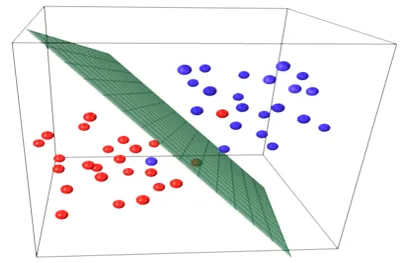
Podstawową ideą w modelu regresji jest uzyskanie równania liniowego, które najlepiej pasuje do danych. Linia najlepszego dopasowania to ta, w której całkowity błąd prognozowania dla wszystkich punktów danych uważanych za możliwie małe. Błąd to odległość między punktem na płaszczyźnie a linią regresji.
Przykład
Zacznijmy od przykładu prostej regresji liniowej.

Związek między wzrostem a wagą osoby jest wprost proporcjonalny. Przeprowadzono badanie na ochotnikach, aby określić wzrost i idealną wagę osoby, a wartości zostały zapisane. Będzie to uważane za nasz zestaw danych treningowych. Na podstawie danych treningowych obliczane jest równanie linii regresji, które da minimalny błąd. To równanie liniowe jest następnie wykorzystywane do prognozowania nowych danych. Oznacza to, że jeśli podamy wzrost osoby, to odpowiedni model powinien być przewidziany przez opracowany przez nas model z błędem minimalnym lub zerowym.
Y(pred) = b0 + b1*x
Wartości b0 i b1 należy wybrać tak, aby zminimalizować błąd. Jeśli suma błędu do kwadratu zostanie przyjęta jako metryka do oceny modelu, wówczas celem jest uzyskanie linii, która najlepiej zmniejsza błąd.
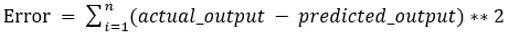
Wyrównujemy błąd, aby wartości dodatnie i ujemne się nie znosiły. Dla modelu z jednym predyktorem:
Obliczanie przecięcia (b0) w równaniu liniowym wykonuje się przez:
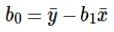
Obliczenia współczynnika dla wartości wejściowej x dokonuje się przez:
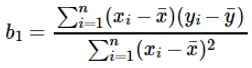
Zrozumienie współczynnika b 1 :
- Jeżeli b 1 > 0, to x (wejście) i y (wyjście) są wprost proporcjonalne. Oznacza to, że wzrost x zwiększy y, np. Wzrost, wzrost masy.
- Jeżeli b 1 <0, to x (predyktor) iy (cel) są odwrotnie proporcjonalne. Oznacza to, że wzrost x zmniejszy y, taki jak prędkość wzrostu pojazdu, czas jest zmniejszany.
Zrozumienie współczynnika b 0 :
- B 0 przyjmuje wartość rezydualną dla modelu i zapewnia, że przewidywanie nie jest stronnicze. Jeśli nie mamy terminu B 0, równanie liniowe (y = B 1 x) jest zmuszone do przejścia przez początek, tzn. Wartości wejściowe i wyjściowe wprowadzone do modelu dają wynik równy 0. Ale to nigdy nie będzie tak, jeśli mamy 0 na wejściu, wówczas B 0 będzie średnią ze wszystkich przewidywanych wartości, gdy x = 0. Ustawienie wszystkich wartości predykcyjnych na 0 w przypadku x = 0 spowoduje utratę danych i często jest niemożliwe.
Oprócz wyżej wymienionych współczynników model ten można również obliczyć za pomocą równań normalnych. W kolejnym artykule omówię dalej stosowanie równań normalnych i projektowanie prostego / wieloliniowego modelu regresji.
Polecane artykuły
Jest to przewodnik po modelowaniu regresji liniowej. Tutaj omawiamy definicję, typy regresji liniowej, która obejmuje prostą i wielokrotną regresję liniową wraz z kilkoma przykładami. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Regresja liniowa w R.
- Regresja liniowa w programie Excel
- Modelowanie predykcyjne
- Jak utworzyć GLM w R?
- Porównanie regresji liniowej z regresją logistyczną