
Wprowadzenie do plików R CSV
Pliki CSV są szeroko stosowane do przechowywania informacji w formacie tabelarycznym, a każdy wiersz jest rekordem danych. Aby czytać, zapisywać lub manipulować danymi w R, musimy mieć przy sobie niektóre dane. Dane można znaleźć w Internecie lub z różnych źródeł, takich jak ankiety. Za pomocą R można czytać, zapisywać i edytować dane przechowywane w środowisku zewnętrznym. R może odczytywać i zapisywać dane z różnych formatów, takich jak XML, CSV i Excel. W tym artykule zobaczymy, jak można używać R do odczytu, zapisu i wykonywania różnych operacji na plikach CSV.
Tworzenie pliku CSV w R
W tej sekcji zobaczymy, jak można utworzyć ramkę danych i wyeksportować ją do pliku CSV w R. W pierwszej części utworzymy ramkę danych, która składa się ze zmiennych pracownika i odpowiedniego wynagrodzenia.
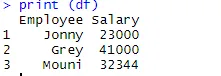
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
Po utworzeniu ramki danych nadszedł czas, aby użyć funkcji eksportu R, aby utworzyć plik CSV w R. Aby wyeksportować ramkę danych do CSV, możemy użyć poniższego kodu.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
W powyższym wierszu kodu podaliśmy katalog ścieżek dla naszej sławy danych i zapisaliśmy ramkę danych w formacie CSV. W powyższym przypadku plik CSV został zapisany na moim osobistym pulpicie. Ten konkretny plik zostanie wykorzystany w naszym samouczku do wykonywania wielu operacji.
Odczytywanie plików CSV w R.
Podczas przeprowadzania analiz za pomocą R w wielu przypadkach jesteśmy zobowiązani do odczytu danych z pliku CSV. R jest bardzo niezawodny podczas odczytu plików CSV. W powyższym przykładzie utworzyliśmy plik, który wykorzystamy do odczytu za pomocą polecenia read.csv. Poniżej znajduje się przykład, aby to zrobić w R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Powyższe polecenie odczytuje plik Employee.csv, który jest dostępny na pulpicie i wyświetla go w R. studio. Komenda nagłówka oznacza, że nagłówek jest udostępniony dla zestawu danych, a komenda sep oznacza, że dane są oddzielone przecinkami.
Zapisz pliki CSV w języku R.
Zapis do pliku CSV jest jedną z najbardziej przydatnych funkcji dostępnych w R dla analityka danych. Można to wykorzystać do zapisania edytowanego pliku CSV w nowym pliku CSV w celu analizy danych. Komenda Write.csv służy do zapisywania pliku w CSV.
W poniższym kodzie df w ramce danych, w której dostępne są nasze dane, append służy do określenia, że nowy plik jest tworzony zamiast dodawania lub zastępowania w starym pliku. Dołącz false sugeruje utworzenie nowego pliku CSV. Sep reprezentuje pole oddzielone przecinkiem.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
Operacje CSV
Operacje CSV są wymagane do kontroli danych po ich załadowaniu do systemu. R ma kilka wbudowanych funkcji do weryfikacji i inspekcji danych. Te operacje dostarczają kompletnych informacji dotyczących zestawu danych.
Jednym z najczęściej używanych poleceń jest podsumowanie.
> summary(df)
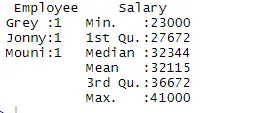
Polecenie podsumowania zapewnia nam statystyki według kolumn. Zmienna numeryczna jest opisana w sposób statystyczny, który obejmuje wyniki statystyczne, takie jak średnia, min, mediana i maks. W powyższym przykładzie dwie zmienne, które są pracownikiem i wynagrodzeniem, są posegregowane, a statystyki dla zmiennej liczbowej, którą jest wynagrodzenie, są pokazane.
Polecenie View () służy do otwierania zestawu danych na innej karcie i weryfikacji go ręcznie.
> View(df)

Funkcja Str dostarczy użytkownikom więcej informacji na temat kolumny zestawu danych. W poniższym przykładzie możemy zobaczyć, że zmienna Employee ma Factor jako typ danych, a zmienna Salary ma int (integer) jako typ danych.
> str(df)

W wielu przypadkach będziemy musieli zobaczyć całkowitą liczbę dostępnych wierszy w przypadku dużego zestawu danych, dla którego możemy użyć polecenia nrow (). Zobacz przykład poniżej.
> # to show the total number of rows in the dataset
> nrow(df)

W podobny sposób, aby wyświetlić całkowitą liczbę kolumn, możemy użyć polecenia ncol ()
> ncol(df)

R pozwala nam wyświetlić żądaną liczbę wierszy za pomocą poniższego polecenia. Gdy ich liczba wierszy n jest dostępna w zestawie danych, możemy określić zakres wierszy, które mają być wyświetlane.
> # to display first 2 rows of the data
> df(1:2, )

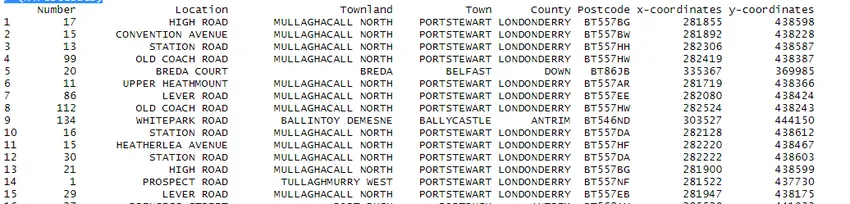
Operacja danych wykonywana jest na dużym zbiorze danych. Dla ilustracji pobrałem zestaw danych o otwartym kodzie pocztowym NI z Internetu.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
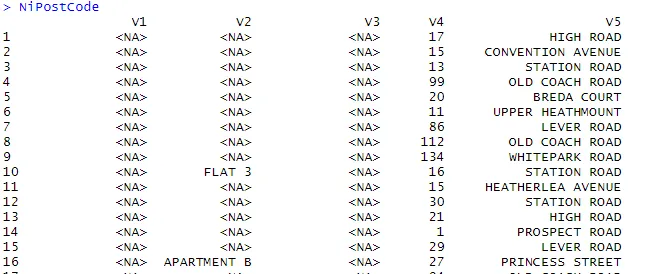
W powyższym zestawie danych widać, że brakuje nazw nagłówków i istnieje wiele wartości null. Zestaw danych wymaga czyszczenia, aby był gotowy do analizy. W następnym kroku nagłówki będą odpowiednio nazwami.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Teraz policzmy liczbę brakujących wartości w ramce danych, a następnie odpowiednio je usuń.
> # count of all missing values
> table(is.na (NiPostCode))

Z powyższego polecenia możemy zobaczyć, że całkowita liczba odstępów lub NA w ramce danych jest bliska 5445148. Usunięcie wszystkich wartości zerowych spowoduje utratę ogromnej ilości danych, dlatego dobrze jest usunąć kolumny, w których więcej niż połowa 50% danych brakuje.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Wniosek
W tym samouczku widzieliśmy, jak można tworzyć, czytać i dołączać pliki CSV za pomocą operacji w R. Nauczyliśmy się, jak tworzyć nowy zestaw danych w R, a następnie importować go do formatu CSV. Ponadto zaobserwowaliśmy wiele operacji, takich jak zmiana nazwy nagłówka i zliczanie liczby wierszy i kolumn.
Polecane artykuły
Jest to przewodnik po plikach R CSV. Tutaj omawiamy tworzenie, czytanie i zapisywanie pliku CSV w R z Operacjami CSV. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- JSON vs CSV
- Proces eksploracji danych
- Kariera w analizie danych
- Excel vs CSV