

Wprowadzenie do Apache Flume
Apache Flume to Data Ingestion Framework, który zapisuje dane oparte na zdarzeniach w rozproszonym systemie plików Hadoop. Wiadomo, że Hadoop przetwarza duże zbiory danych, powstaje pytanie, w jaki sposób dane generowane z różnych serwerów sieciowych są przesyłane do systemu plików Hadoop? Odpowiedź brzmi: Apache Flume. Flume jest przeznaczony do przetwarzania dużych ilości danych w Hadoop danych opartych na zdarzeniach.
Rozważ scenariusz, w którym liczba serwerów WWW generuje pliki dziennika, które muszą zostać przesłane do systemu plików Hadoop. Flume zbiera te pliki jako zdarzenia i pobiera je do Hadoop. Chociaż Flume służy do przesyłania do Hadoop, nie ma sztywnej zasady, że miejscem docelowym musi być Hadoop. Flume jest w stanie pisać do innych frameworków, takich jak Hbase lub Solr.
Architektura Flume
Ogólnie architektura Apache Flume składa się z następujących komponentów:
- Źródło Flume
- Kanał Flume
- Umywalka Flume
- Flume Agent
- Flume Event
Rzućmy okiem na każdy składnik Flume
1. Źródło Flume
Źródło Flume jest obecne w generatorach danych, takich jak Face book lub Twitter. Źródło gromadzi dane z generatora i przekazuje je do kanału Flume w formie zdarzeń Flume. Flume obsługuje różne typy źródeł, takie jak Avro Flume Source - łączy się na porcie Avro i odbiera zdarzenia od zewnętrznego klienta Avro, Thrift Flume Source - łączy się na porcie Thrift i odbiera zdarzenia z zewnętrznych strumieni klienta Thrift, źródła katalogu buforowania i źródła Kafka Flume.
2. Kanał Flume
Sklep pośredni, który buforuje zdarzenia wysyłane przez źródło Flume, dopóki nie zostaną zużyte przez zlew, nazywa się kanałem Flume. Kanał działa jako pośredni pomost między źródłem a zlewem. Kanały kanałowe mają charakter transakcyjny.
Flume zapewnia obsługę kanału pliku i kanału pamięci. Kanał plików ma charakter trwały, co oznacza, że po zapisaniu danych w kanale nie zostaną utracone, chociaż jeśli agent uruchomi się ponownie. W pamięci zdarzenia kanału są przechowywane w pamięci, więc nie jest trwały, ale ma bardzo szybki charakter.
3. Zlewozmywak
Zlew Flume jest obecny w repozytoriach danych, takich jak HDFS, HBase. Zlew Flume pobiera zdarzenia z kanału i przechowuje je w sklepach docelowych, takich jak HDFS. Nie ma reguły, zgodnie z którą zlew powinien dostarczać zdarzenia do Sklepu, zamiast tego możemy go skonfigurować w taki sposób, aby zlew mógł dostarczać zdarzenia do innego agenta. Flume obsługuje różne zlewy, takie jak zlew HDFS, zlew Hive, zlew Thrift, zlew Avro.
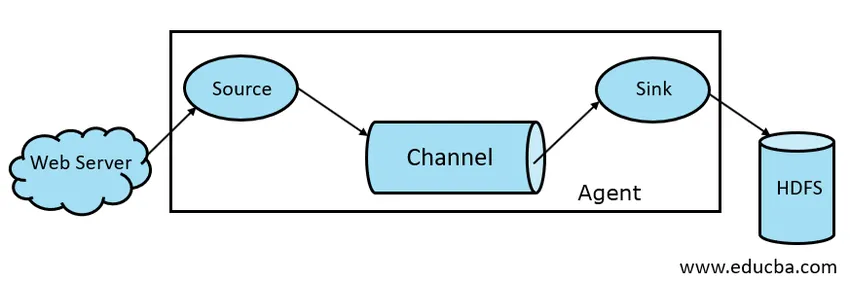
Ryc. 1.1 Podstawowa architektura Flume
4. Flume Agent
Agent Flume to długotrwały proces Java, który działa na kombinacji Source - Channel - Sink Combination. Flume może mieć więcej niż jednego agenta. Możemy uznać Flume za zbiór połączonych agentów Flume, które są dystrybuowane w naturze.
5. Wydarzenie Flume
Zdarzenie to jednostka danych transportowanych w Flume . Ogólna reprezentacja obiektu danych we Flume nazywa się Zdarzenie. Zdarzenie składa się z ładunku tablicy bajtów z opcjonalnymi nagłówkami.
Praca Flume
Agent Flume to proces Java, który składa się z Source - Channel - Sink w najprostszej formie. Źródło gromadzi dane z generatora danych w postaci zdarzeń i dostarcza je do kanału. Źródło może dostarczać do wielu kanałów zgodnie z wymaganiami. Fan out jest procesem, w którym jedno źródło będzie zapisywać na wiele kanałów, aby mogły dostarczać do wielu odbiorników.
Zdarzenie to podstawowa jednostka danych przesyłanych w Flume. Kanał buforuje dane, dopóki nie zostaną przetworzone przez Sink. Sink zbiera dane z kanału i dostarcza je do scentralizowanego magazynu danych, takiego jak HDFS lub Sink może przekazywać te zdarzenia do innego agenta Flume zgodnie z wymaganiami.
Flume obsługuje transakcje. Aby osiągnąć Rzetelność, Flume stosuje oddzielne transakcje od źródła do kanału i od kanału do zlewu. Jeśli zdarzenia nie zostaną dostarczone, transakcja zostanie wycofana, a następnie ponownie dostarczona.
Aby zrozumieć działanie Flume, weźmy przykład konfiguracji Flume, w której źródłem jest buforowanie katalogu, a sink to Hdfs. W tym przykładzie agent Flume ma najprostszą formę, tj. Topologię z pojedynczym źródłem - kanałem - zlew, która jest konfigurowana przy użyciu pliku właściwości Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
W powyższym przykładzie konfiguracji agent jest podstawą, za pomocą której definiujemy inne właściwości. source1 i sink1 i channel1 to odpowiednio nazwy źródła, ujścia i kanału, a także ich typy i lokalizacje.
Zalety Apache Flume
- Flume jest z natury skalowalny, niezawodny i odporny na uszkodzenia. Te właściwości zostały szczegółowo omówione poniżej
- Skalowalne - Flume jest skalowalny w poziomie, tzn. Możemy dodawać nowe węzły zgodnie z naszymi wymaganiami
- Niezawodny - Apache Flume obsługuje transakcje i zapewnia, że żadne dane nie zostaną utracone w procesie transmisji danych. Ma różne transakcje od źródła do kanału i od kanału do źródła.
- Flume jest konfigurowalny i zapewnia obsługę różnych źródeł i zlewów, takich jak Kafka, Avro, katalog buforowania, Thrift itp.
- We Flume pojedyncze źródło może przesyłać dane do wielu kanałów, a te kanały z kolei będą przesyłać dane do wielu odbiorników, a zatem pojedyncze źródło może przesyłać dane do wielu odbiorników. Ten mechanizm nosi nazwę Fan Out. Flume obsługuje także opcję Fan out.
- Flume zapewnia stały przepływ transmisji danych, tj. Gdy zwiększa się prędkość odczytu danych, a następnie rośnie prędkość zapisu danych.
- Chociaż Flume zazwyczaj zapisuje dane w scentralizowanym magazynie, takim jak HDFS lub Hbase, możemy skonfigurować Flume zgodnie z naszymi wymaganiami, tak aby Sink mógł zapisywać dane do innego agenta. To pokazuje elastyczność Flume
- Apache Flume ma charakter open source.
Wniosek
W tym artykule Flume omówiono szczegółowo składniki Flume i działanie Flume. Flume to elastyczna, niezawodna i skalowalna platforma do przesyłania danych do scentralizowanego sklepu, takiego jak HDFS. Jego zdolność do integracji z różnymi aplikacjami, takimi jak Kafka, Hdfs, Thrift, sprawia, że jest to opłacalna opcja do pobierania danych.
Polecane artykuły
To był przewodnik po Apache Flume. Tutaj omawiamy architekturę, działanie i zalety Apache Flume. Możesz także zapoznać się z następującymi artykułami, aby dowiedzieć się więcej -
- Co to jest Apache Flink?
- Różnica między Apache Kafka a Flume
- Architektura Big Data
- Narzędzia Hadoop
- Dowiedz się różnych zdarzeń JavaScript