

Wprowadzenie do analizy regresji liniowej
Często mylące jest poznanie pojęcia, które jest nawet częścią naszego codziennego życia. Ale to nie jest problem, możemy pomóc i rozwinąć się, aby uczyć się z naszych codziennych czynności, po prostu analizując rzeczy i nie bojąc się zadawać pytań. Dlaczego cena wpływa na popyt na towary, dlaczego zmiana stopy procentowej wpływa na podaż pieniądza. Na to wszystko można odpowiedzieć prostym podejściem znanym jako regresja liniowa. Jedyną złożonością, jaką odczuwa się przy analizie regresji liniowej, jest identyfikacja zmiennych zależnych i niezależnych.
Musimy znaleźć to, co na to wpływa, a połowa problemu została rozwiązana. Musimy sprawdzić, czy to cena czy popyt wpływają na siebie nawzajem. Gdy dowiemy się, która jest zmienną niezależną i zmienną zależną, możemy przejść do naszej analizy. Dostępnych jest wiele rodzajów analizy regresji. Ta analiza zależy od dostępnych nam zmiennych.
3 typy analizy regresji
Te trzy analizy regresji mają maksymalne przypadki użycia w świecie rzeczywistym, w przeciwnym razie istnieje ponad 15 rodzajów analizy regresji. Rodzaje analizy regresji, które będziemy omawiać, to:
- Analiza regresji liniowej
- Analiza wielu regresji liniowych
- Regresja logistyczna
W tym artykule skupimy się na analizie prostej regresji liniowej. Ta analiza pomaga nam zidentyfikować związek między czynnikiem niezależnym a czynnikiem zależnym. Mówiąc prościej, model regresji pomaga nam stwierdzić, w jaki sposób zmiany czynnika niezależnego wpływają na czynnik zależny. Ten model pomaga nam na wiele sposobów, takich jak:
- Jest to prosty i skuteczny model statystyczny
- Pomoże nam w tworzeniu prognoz i prognoz
- Pomoże nam to podjąć lepszą decyzję biznesową
- Pomoże nam to przeanalizować wyniki i poprawić błędy
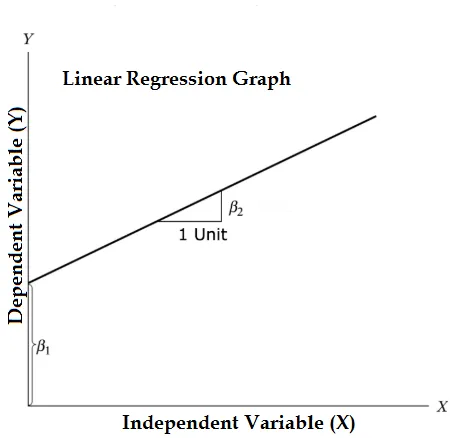
Równanie regresji liniowej i podziel go na odpowiednie części
Y = β1 + β2X + ϵ
- Gdzie β1 w terminologii matematycznej znanej jako intercept i β2 w terminologii matematycznej znanej jako nachylenie. Są one również znane jako współczynniki regresji. ϵ jest terminem błędu, jest częścią Y, której model regresji nie jest w stanie wyjaśnić.
- Y jest zmienną zależną (inne terminy, które są używane zamiennie dla zmiennych zależnych to zmienna odpowiedzi, regresja i zmienna mierzona, zmienna obserwowana, zmienna odpowiadająca, zmienna wyjaśniona, zmienna wyniku, zmienna eksperymentalna i / lub zmienna wyjściowa).
- X jest zmienną niezależną (regresory, zmienna kontrolowana, zmienna zmanipulowana, zmienna objaśniająca, zmienna ekspozycji i / lub zmienna wejściowa).
Problem: Aby zrozumieć, czym jest analiza regresji liniowej, bierzemy zestaw danych „Samochody”, który jest domyślnie dostępny w katalogach R. W tym zestawie danych znajduje się 50 obserwacji (w zasadzie wierszy) i 2 zmienne (kolumny). Nazwy kolumn to „Dist” i „Speed”. Tutaj musimy zobaczyć wpływ na zmienne odległości wynikające ze zmiany zmiennych prędkości. Aby zobaczyć strukturę danych, możemy uruchomić kod Str (zestaw danych). Ten kod pomaga nam zrozumieć strukturę zestawu danych. Te funkcje pomagają nam podejmować lepsze decyzje, ponieważ mamy lepszy obraz struktury zbiorów danych. Ten kod pomaga nam zidentyfikować typ zestawów danych.
Kod:

Podobnie, aby sprawdzić punkty kontrolne statystyk zestawu danych, możemy użyć kodu Podsumowanie (samochody). Ten kod określa średni, medianę zakresu zestawu danych w czasie rzeczywistym, z którego badacz może korzystać podczas rozwiązywania problemu.
Wynik:
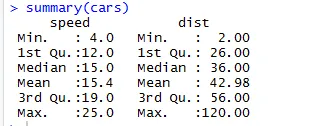
Tutaj możemy zobaczyć wyniki statystyczne każdej zmiennej, którą mamy w naszym zestawie danych.
Graficzna reprezentacja zestawów danych
Rodzaje prezentacji graficznej, które zostaną tutaj omówione, i dlaczego:
- Wykres rozrzutu: Za pomocą wykresu możemy zobaczyć, w jakim kierunku zmierza nasz model regresji liniowej, czy istnieją mocne dowody na potwierdzenie naszego modelu, czy nie.
- Fabuła: Pomaga nam znaleźć wartości odstające.
- Wykres gęstości: Pomóż nam zrozumieć rozkład zmiennej niezależnej, w naszym przypadku zmienną niezależną jest „Prędkość”.
Zalety reprezentacji graficznej
Oto następujące zalety:
- Łatwy do zrozumienia
- Pomaga nam podjąć szybką decyzję
- Analiza porównawcza
- Mniej wysiłku i czasu
1. Wykres rozrzutu: Pomoże w wizualizacji wszelkich zależności między zmienną niezależną a zmienną zależną.
Kod:

Wynik:
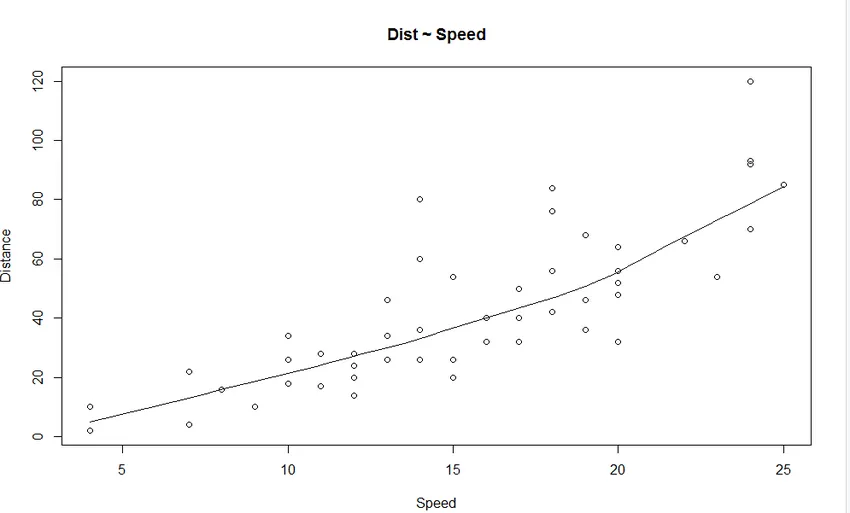
Z wykresu widać liniowo rosnącą zależność między zmienną zależną (Odległość) a zmienną niezależną (Prędkość).
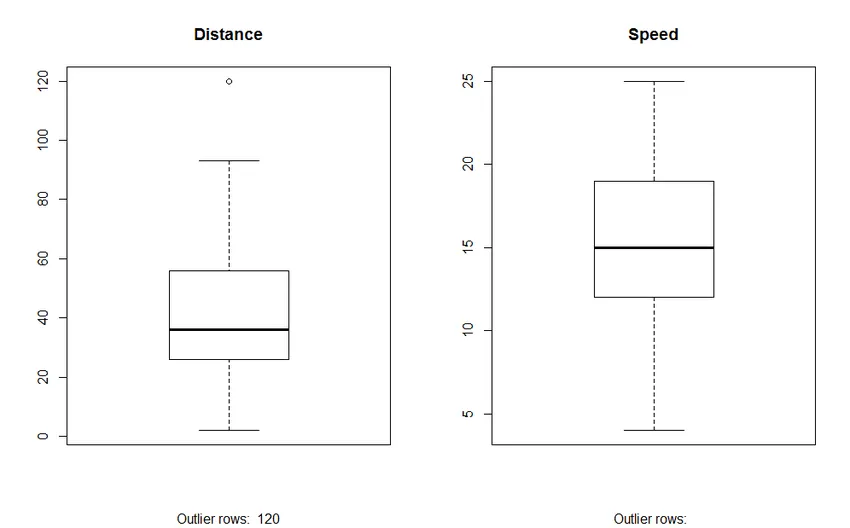
2. Wykres pola: Wykres pola pomaga nam zidentyfikować wartości odstające w zestawach danych. Zalety korzystania z wykresu pudełkowego to:
- Graficzne wyświetlanie położenia i rozprzestrzeniania się zmiennych.
- Pomaga nam zrozumieć skośność i symetrię danych.
Kod:

Wynik:
3. Wykres gęstości (w celu sprawdzenia normalności rozkładu)
Kod:
 Wynik:
Wynik:
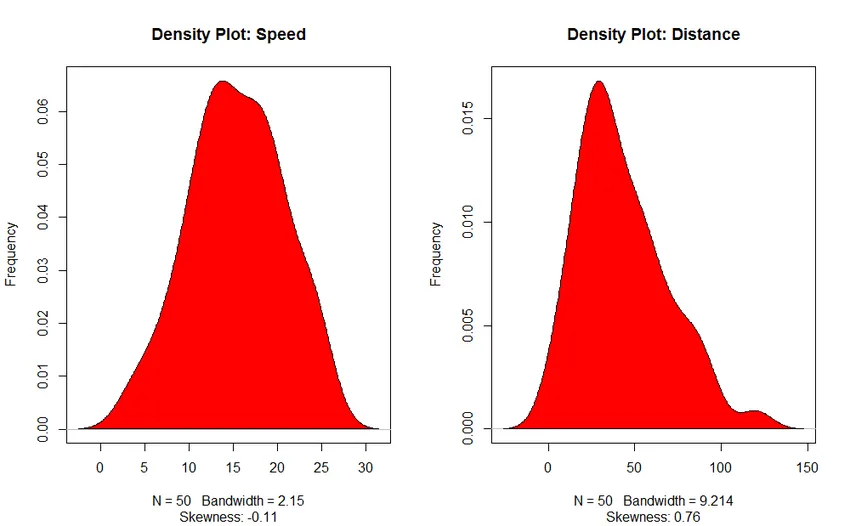
Analiza korelacji
Ta analiza pomaga nam znaleźć związek między zmiennymi. Istnieje głównie sześć rodzajów analizy korelacji.
- Korelacja dodatnia (od 0, 01 do 0, 99)
- Korelacja ujemna (od -0, 99 do -0, 01)
- Brak powiązań
- Idealna korelacja
- Silna korelacja (wartość bliższa ± 0, 99)
- Słaba korelacja (wartość bliższa 0)
Wykres rozproszenia pomaga nam zidentyfikować, jakie typy zestawów danych korelacji mają wśród nich, a kodem do znalezienia korelacji jest

Wynik:
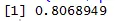
Tutaj mamy silną pozytywną korelację między prędkością a odległością, co oznacza, że mają bezpośredni związek między nimi.
Model regresji liniowej
Jest to podstawowy element analizy, wcześniej próbowaliśmy i testowaliśmy, czy zbiór danych, który mamy, jest wystarczająco logiczny, aby przeprowadzić taką analizę, czy nie. Funkcja, której planujemy użyć to lm (). Ta funkcja zawiera dwa elementy, które są formułą i danymi. Przed przypisaniem tej zmiennej, która jest zależna lub niezależna, musimy być bardzo pewni, ponieważ od tego zależy cała nasza formuła.
Formuła wygląda następująco
Regresja liniowa <- lm (zmienna zależna ~ zmienna niezależna, dane = ramka daty)
Kod:

Wynik:
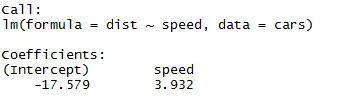
Jak możemy przypomnieć z powyższego segmentu artykułu, równanie regresji liniowej jest następujące:
Y = β1 + β2X + ϵ
Teraz w tym równaniu dopasujemy informacje, które otrzymaliśmy z powyższego kodu.
dyst = -17, 579 + 3, 932 ∗ prędkości
Samo znalezienie równania regresji liniowej nie jest wystarczające, musimy również sprawdzić jego statystyczną istotność. W tym celu musimy przekazać kod „Podsumowanie” w naszym modelu regresji liniowej.
Kod:

Wynik:

Istnieje wiele sposobów sprawdzania istotności statystycznej modelu, tutaj stosujemy metodę wartości P. Możemy uznać model za statystycznie dopasowany, gdy wartość P jest mniejsza niż z góry określony poziom istotności statystycznej, który idealnie wynosi 0, 05. W naszej tabeli podsumowań (regresja_liniowa) widzimy, że wartość P jest poniżej poziomu 0, 05, więc możemy stwierdzić, że nasz model jest statystycznie istotny. Gdy już będziemy mieć pewność co do naszego modelu, możemy użyć naszego zestawu danych do przewidywania rzeczy.
Polecane artykuły
Jest to przewodnik po analizie regresji liniowej. Omawiamy tutaj trzy typy analizy regresji liniowej, graficzną reprezentację zestawów danych z zaletami i modelami regresji liniowej. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej-
- Formuła regresji
- Testy regresji
- Regresja liniowa w R.
- Rodzaje technik analizy danych
- Co to jest analiza regresji?
- Najważniejsze różnice w regresji a klasyfikacja
- Top 6 różnic regresji liniowej a regresja logistyczna