

Różnica między MapReduce a Spark
Map Reduce to platforma typu open source do zapisywania danych w HDFS i przetwarzania ustrukturyzowanych i nieustrukturyzowanych danych obecnych w HDFS. Map Reduce ogranicza się do przetwarzania wsadowego, a na innym Spark może przetwarzać dowolny rodzaj przetwarzania. SPARK to niezależny silnik przetwarzania do przetwarzania w czasie rzeczywistym, który można zainstalować w dowolnym systemie plików rozproszonych, takim jak Hadoop. SPARK zapewnia wydajność 10 razy większą niż Map Reduce na dysku i 100 razy szybszą niż Map Reduce w sieci w pamięci.
Need For SPARK
- Iterative Analytics: Redukcja mapy nie jest tak skuteczna jak SPARK do rozwiązywania problemów wymagających iteracyjnej analizy, ponieważ musi przejść na dysk dla każdej iteracji.
- Interaktywna analiza: redukcja mapy jest często używana do uruchamiania zapytań ad-hoc, w przypadku których musi ona dotrzeć do pamięci na dysku, która znowu nie jest tak wydajna jak SPARK, ponieważ ta ostatnia odwołuje się do szybszej pamięci.
- Nie nadaje się do OLTP: ponieważ działa na frameworku zorientowanym na partie, nie nadaje się do dużej liczby krótkich transakcji.
- Nieodpowiednie dla wykresu: Biblioteka wykresów Apache przetwarza wykres, co zwiększa złożoność mapy.
- Nie nadaje się do trywialnych operacji: w przypadku operacji takich jak filtr i sprzężenia konieczne może być przepisanie zadań, które stają się bardziej złożone z powodu wzorca klucz-wartość.
Bezpośrednie porównanie między MapReduce a Spark (infografiki)
Poniżej znajduje się 15 najlepszych różnic między MapReduce i Spark

Kluczowe różnice między MapReduce a Spark
Poniżej znajdują się listy punktów, opisz kluczowe różnice między MapReduce i Spark:
- Spark jest odpowiedni do pracy w czasie rzeczywistym, ponieważ przetwarza za pomocą pamięci, natomiast MapReduce ogranicza się do przetwarzania wsadowego.
- Spark ma RDD (Resilient Distributed Dataset), co daje nam operatorów wysokiego poziomu, ale w Map Red potrzebujemy kodować każdą operację, co czyni ją stosunkowo trudną.
- Spark może przetwarzać wykresy i obsługuje narzędzie Uczenie maszynowe.
- Poniżej znajduje się różnica między ekosystemem MapReduce a Spark.
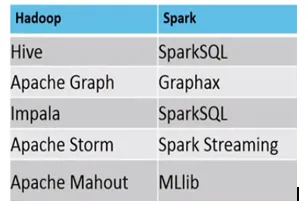
Przykład, w którym odpowiednie są MapReduce vs. Spark, jest następujący
Spark: wykrywanie oszustw związanych z kartami kredytowymi
MapReduce: sporządzanie regularnych raportów wymagających podejmowania decyzji.
MapReduce vs. Spark Tabela porównawcza
| Podstawa porównania | MapReduce | Iskra |
| Struktura | Struktura open source do zapisywania danych w HDFS i przetwarzania danych strukturalnych i nieustrukturyzowanych obecnych w HDFS. | Struktura open source do szybszego przetwarzania danych ogólnego przeznaczenia |
| Prędkość | Map-Reduce przetwarza dane (odczytuje i zapisuje) z dysku, dzięki czemu wyciek jest powolny w porównaniu do Spark. | Spark jest co najmniej 10 razy szybszy na dysku i 100 razy szybszy w pamięci niż w Map Reduce. |
| Trudność | Musimy kodować / obsługiwać każdy proces. | Dzięki dostępności RDD (Resilient Distributed Dataset) programowanie jest łatwe. |
| Czas rzeczywisty | Nie nadaje się do transakcji OLTP tylko w trybie wsadowym | Może obsługiwać przetwarzanie w czasie rzeczywistym. Korzystanie ze strumieniowania SPARK. |
| Czas oczekiwania | Wysokopoziomowe ramy obliczeniowe opóźnień | Niskopoziomowe środowisko obliczeniowe opóźnień. |
| Odporność na awarie | Demony nadrzędne sprawdzają bicie serca demonów podrzędnych, aw przypadku awarii demonów podrzędnych demony nadrzędne ponownie rozkładają wszystkie oczekujące i trwające operacje na inne urządzenia podrzędne. | RDD zapewniają SPARK odporność na uszkodzenia. Odnoszą się do zestawu danych obecnych w pamięci zewnętrznej, takich jak (HDFS, HBase) i działają równolegle. |
| Planista | W Map Reduce korzystamy z zewnętrznego harmonogramu, takiego jak Oozie. | Ponieważ SPARK działa z obliczeniami w pamięci, działa jak własny harmonogram. |
| Koszt | Mapa Reduce jest stosunkowo tańsza w porównaniu do SPARK. | Ponieważ działa w pamięci, wymaga dużo pamięci RAM, co czyni go stosunkowo droższym. |
| Platforma opracowana na | Map Reduce został opracowany przy użyciu Java. | SPARK został opracowany przy użyciu Scali. |
| Obsługiwany język | Map Reduce w zasadzie obsługuje C, C ++, Ruby, Groovy, Perl, Python. | Spark obsługuje Scala, Java, Python, R, SQL. |
| Wsparcie SQL | Map Reduce uruchamia zapytania za pomocą Hive Query Language. | Spark ma swój własny język zapytań znany jako Spark SQL. |
| Skalowalność | W Map Reduce możemy dodać do n liczby węzłów. Największy klaster Hadoop ma 14000 węzłów. | W Spark również możemy dodać n liczbę węzłów. Największy klaster Spark ma 8000 węzłów. |
| Nauczanie maszynowe | Map Reduce obsługuje narzędzie Apache Mahout do uczenia maszynowego. | Spark obsługuje narzędzie MLlib do uczenia maszynowego. |
| Buforowanie | Redukcja mapy nie jest w stanie buforować danych w pamięci, więc nie jest tak szybka jak w przypadku Spark. | Spark buforuje dane w pamięci do dalszych iteracji, dzięki czemu jest bardzo szybki w porównaniu z Map Reduce. |
| Bezpieczeństwo | Map Reduce obsługuje więcej projektów i funkcji bezpieczeństwa w porównaniu do Spark | Bezpieczeństwo Spark nie jest jeszcze dojrzałe jak w Map Reduce |
Wniosek - MapReduce vs Spark
Jak wynika z powyższej Różnicy między MapReduce i Spark, jest całkiem jasne, że SPARK jest znacznie bardziej zaawansowanym silnikiem obliczeniowym w porównaniu do Map Reduce. Spark jest kompatybilny z każdym rodzajem formatu pliku, a także znacznie szybszy niż Map Reduce. Iskra dodatkowo ma również możliwości przetwarzania wykresów i uczenia maszynowego.
Z jednej strony Map Reduce ogranicza się do przetwarzania wsadowego, a z drugiej strony Spark może przetwarzać dowolny rodzaj przetwarzania (wsadowy, interaktywny, iteracyjny, streaming, wykres). Ze względu na dużą kompatybilność Spark jest ulubieńcem Data Scientist, dlatego zastępuje Map Reduce i szybko rośnie. Ale nadal musimy przechowywać dane w HDFS, a także czasami potrzebujemy HBase. Musimy więc uruchomić zarówno Spark, jak i Hadoop, aby uzyskać to, co najlepsze.
Polecane artykuły:
Jest to przewodnik po MapReduce vs Spark, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- 7 ważnych rzeczy na temat Apache Spark (przewodnik)
- Hadoop vs Apache Spark - ciekawe rzeczy, które musisz wiedzieć
- Apache Hadoop vs Apache Spark | 10 najlepszych porównań, które musisz znać!
- Jak działa MapReduce?
- Zbieżność technologii i analityki biznesowej