
Co to jest regresja liniowa w R?
Regresja liniowa jest najpopularniejszym i najczęściej stosowanym algorytmem w dziedzinie statystyki i uczenia maszynowego. Regresja liniowa to technika modelowania mająca na celu zrozumienie zależności między zmiennymi wejściowymi i wyjściowymi. Tutaj zmienne muszą być liczbowe. Regresja liniowa wynika z faktu, że zmienna wyjściowa jest liniową kombinacją zmiennych wejściowych. Dane wyjściowe są zwykle reprezentowane przez „y”, podczas gdy dane wejściowe są reprezentowane przez „x”.
Regresję liniową w R można podzielić na dwa sposoby
-
Konieczna jest regresja liniowa
Jest to regresja, w której zmienna wyjściowa jest funkcją pojedynczej zmiennej wejściowej. Reprezentacja prostej regresji liniowej:
y = c0 + c1 * x1
-
Wielokrotna regresja liniowa
Jest to regresja, w której zmienna wyjściowa jest funkcją zmiennej wielokrotnego wprowadzania.
y = c0 + c1 * x1 + c2 * x2
W obu powyższych przypadkach c0, c1, c2 są współczynnikami reprezentującymi wagi regresji.
Regresja liniowa w R.
R jest bardzo potężnym narzędziem statystycznym. Zobaczmy więc, jak można przeprowadzić regresję liniową w R i jak interpretować jej wartości wyjściowe.
Przygotujmy zestaw danych, aby teraz przeprowadzić dogłębną regresję liniową.
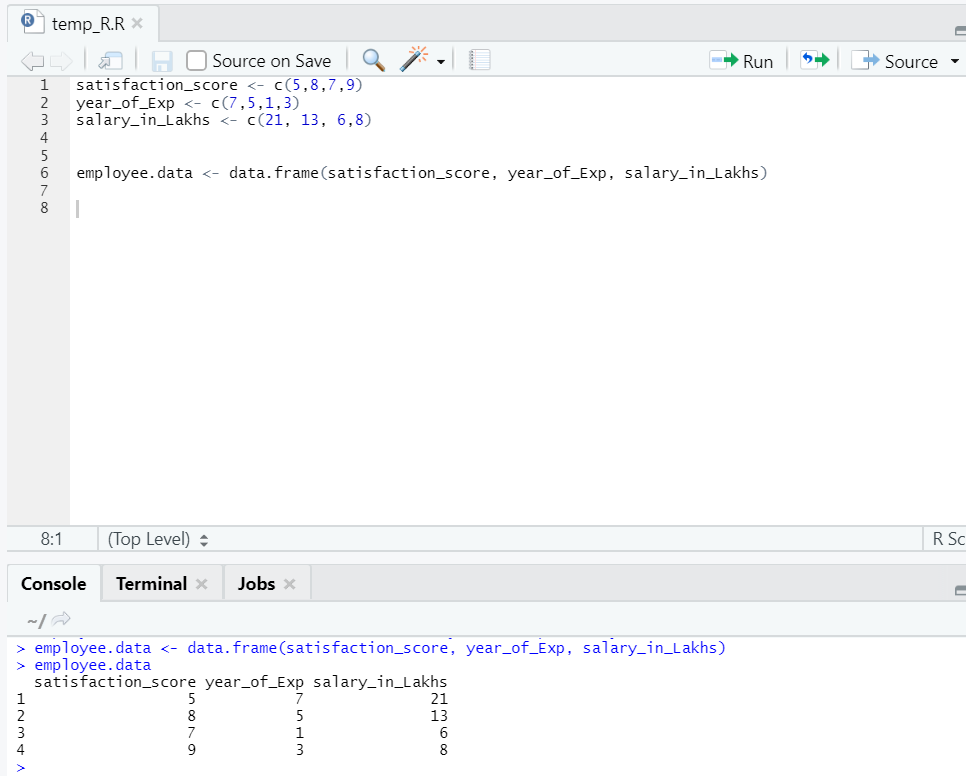
Teraz mamy zestaw danych, w którym „score_score” i „year_of_Exp” są zmienną niezależną. „Salary_in_lakhs” jest zmienną wyjściową.
Odnosząc się do powyższego zestawu danych, problemem, który chcemy rozwiązać tutaj poprzez regresję liniową, jest:
Oszacowanie wynagrodzenia pracownika na podstawie jego roku doświadczenia i oceny satysfakcji w jego firmie.
Kod R regresji liniowej:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Wyjście powyższego kodu będzie:
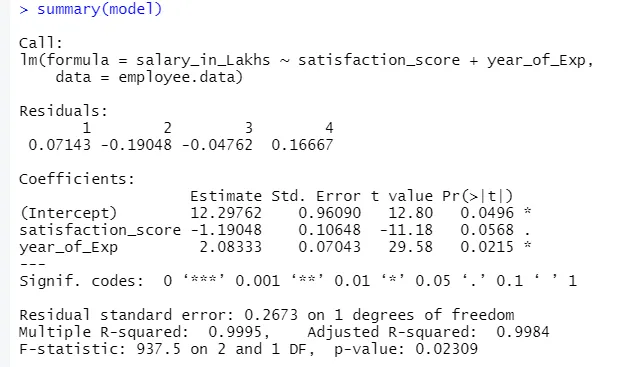
Formuła regresji staje się
T = 12, 29–1, 19 * wynik_satysfakcjonujący + 2, 08 × 2 * rok_eksp
W przypadku, gdy jeden ma wiele danych wejściowych do modelu.
Zatem kod R może być:
model <- lm (salary_in_Lakhs ~., data = worker.data)
Jeśli jednak ktoś chce wybrać zmienną spośród wielu zmiennych wejściowych, istnieje wiele technik takich jak „Eliminacja wsteczna”, „Wybór do przodu” itp.
Interpretacja regresji liniowej w R.
Poniżej znajdują się niektóre interpretacje regresji liniowej wr, które są następujące:
1. Pozostałości
Odnosi się to do różnicy między rzeczywistą odpowiedzią a przewidywaną odpowiedzią modelu. Tak więc dla każdego punktu będzie jedna rzeczywista odpowiedź i jedna przewidywana odpowiedź. Stąd resztek będzie tyle samo, ile obserwacji. W naszym przypadku mamy cztery obserwacje, stąd cztery resztki.

2. Współczynniki
Idąc dalej, znajdziemy sekcję współczynników, która przedstawia przecięcie i nachylenie. Jeśli chce się przewidzieć wynagrodzenie pracownika na podstawie jego doświadczenia i oceny satysfakcji, należy opracować modelową formułę opartą na zboczu i przechwytywaniu. Ta formuła pomoże ci w przewidywaniu zarobków. Przechwytywanie i nachylenie pomagają analitykowi opracować najlepszy model, który jest odpowiedni dla punktów danych.
Nachylenie: przedstawia nachylenie linii.
Przechwyć: miejsce, w którym linia przecina oś.
Rozumiemy, jak formułowanie formuł odbywa się na podstawie nachylenia i przechwytywania.
Powiedzmy, że punkt przecięcia wynosi 3, a nachylenie wynosi 5.
Tak więc formuła to y = 3 + 5x . Oznacza to, że jeśli x zwiększy się o jednostkę, y zwiększy się o 5.
a. Współczynnik - oszacowanie
W tym punkcie przecięcie oznacza średnią wartość zmiennej wyjściowej, gdy wszystkie dane wejściowe stają się zerowe. Zatem w naszym przypadku wynagrodzenie w lakhs wyniesie 12, 29 lakhs jako średnia, biorąc pod uwagę wynik zadowolenia i doświadczenie wynosi zero. Tutaj nachylenie reprezentuje zmianę w zmiennej wyjściowej ze zmianą jednostki w zmiennej wejściowej.
b. Współczynnik - błąd standardowy
Błąd standardowy jest oszacowaniem błędu, który możemy uzyskać, obliczając różnicę między rzeczywistą a przewidywaną wartością naszej zmiennej odpowiedzi. To z kolei mówi o zaufaniu do powiązanych zmiennych wejściowych i wyjściowych.
c. Współczynnik - wartość t
Ta wartość daje pewność odrzucenia hipotezy zerowej. Im większa wartość od zera, tym większa pewność odrzucenia hipotezy zerowej i ustalenia zależności między zmienną wyjściową a zmienną wejściową. W naszym przypadku również wartość jest zera.
d Współczynnik - Pr (> t)
Ten akronim zasadniczo przedstawia wartość p. Im bliżej zera, tym łatwiej możemy odrzucić hipotezę zerową. Linia, którą widzimy w naszym przypadku, ta wartość jest bliska zeru, możemy powiedzieć, że istnieje związek między pakietem wynagrodzeń, wynikiem satysfakcji i rokiem doświadczeń.

Pozostały błąd standardowy
To pokazuje błąd w przewidywaniu zmiennej odpowiedzi. Im jest niższy, tym wyższa jest dokładność modelu.
Wiele R-kwadrat, Skorygowany R-kwadrat
R-kwadrat jest bardzo ważną miarą statystyczną w zrozumieniu, jak blisko dane zostały dopasowane do modelu. Stąd w naszym przypadku, jak dobrze nasz model regresji liniowej reprezentuje zestaw danych.
Wartość R-kwadrat zawsze leży między 0 a 1. Formuła jest:

Im wartość jest bliższa 1, tym lepiej model opisuje zestawy danych i ich wariancję.
Jednak gdy więcej niż jedna zmienna wejściowa pojawia się na obrazie, preferowana jest skorygowana wartość R do kwadratu.
Statystyka F.
Jest to mocna miara do określenia związku między zmienną wejściową a zmienną odpowiedzi. Im większa wartość niż 1, tym większa jest pewność relacji między zmienną wejściową i wyjściową.
W naszym przypadku jest to „937, 5”, co jest względnie większe, biorąc pod uwagę rozmiar danych. Dlatego odrzucenie hipotezy zerowej staje się łatwiejsze.
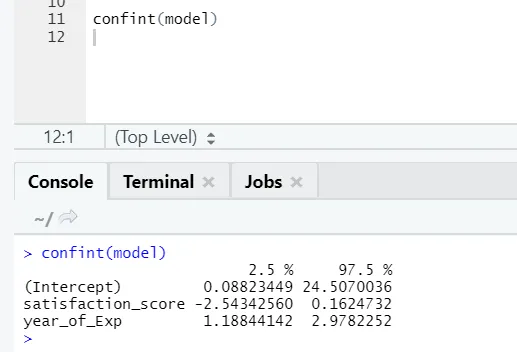
Jeśli ktoś chce zobaczyć przedział ufności dla współczynników modelu, oto jak to zrobić: -
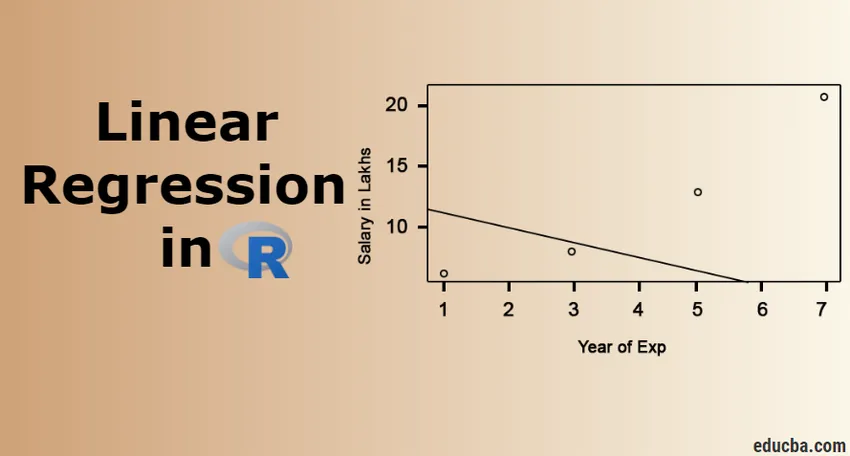
Wizualizacja regresji
Kod R:
wykres (salary_in_Lakhs ~ satysfakcja_score + year_of_Exp, data = pracownik.data)
abline (model)
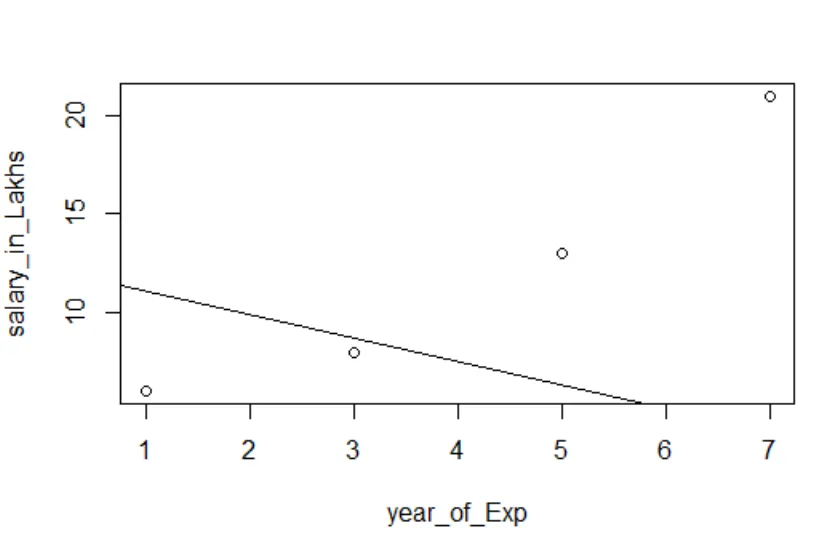
Zawsze lepiej jest zebrać coraz więcej punktów, zanim dopasujesz się do modelu.
Wniosek - regresja liniowa w R.
Regresja liniowa jest prostym, łatwym do dopasowania, łatwym do zrozumienia, a jednocześnie bardzo wydajnym modelem. Widzieliśmy, jak można przeprowadzić regresję liniową na R. Próbowaliśmy także interpretować wyniki, co może pomóc w optymalizacji modelu. Kiedy ktoś zaznajomi się z prostą regresją liniową, powinien wypróbować wiele regresji liniowych. Oprócz tego, ponieważ regresja liniowa jest wrażliwa na wartości odstające, należy przyjrzeć się jej, zanim przejdziemy bezpośrednio do dopasowania do regresji liniowej.
Polecane artykuły
To jest przewodnik po regresji liniowej w R. Tutaj omówiliśmy, czym jest regresja liniowa w R? kategoryzacja, wizualizacja i interpretacja R. Możesz również przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Modelowanie predykcyjne
- Regresja logistyczna w R.
- Drzewo decyzyjne w R.
- R Pytania do wywiadu
- Najważniejsze różnice w regresji a klasyfikacja
- Przewodnik po drzewie decyzyjnym w uczeniu maszynowym
- Regresja liniowa a regresja logistyczna | Najważniejsze różnice