

Przegląd aplikacji Kafka
Jednym z trendów w branży IT jest Big Data, gdzie firma zajmuje się dużą ilością danych klientów i uzyskuje przydatne informacje, które pomagają ich firmom i zapewniają klientom lepszą obsługę. Jednym z wyzwań jest przenoszenie i przenoszenie tak dużych ilości danych z jednego końca na drugi w celu analizy lub przetwarzania, w tym momencie Kafka (niezawodny system przesyłania wiadomości) wchodzi w grę, co pomaga w gromadzeniu i transporcie ogromnej ilości danych w czasie rzeczywistym. Kafka jest przeznaczony do rozproszonych systemów o wysokiej przepustowości i dobrze pasuje do aplikacji przetwarzających wiadomości na dużą skalę. Kafka obsługuje wiele z najlepszych obecnie aplikacji komercyjnych i przemysłowych. Istnieje zapotrzebowanie na specjalistów Kafka posiadających silne umiejętności i praktyczną wiedzę.
W tym artykule dowiemy się o Kafce, jej funkcjach, przypadkach użycia i zrozumiemy niektóre ważne aplikacje, w których jest używany.
Co to jest Kafka?
Apache Kafka został opracowany na LinkedIn, a później stał się projektem Apache typu open source. Apache Kafka to szybki, odporny na awarie, skalowalny i rozproszony system przesyłania wiadomości, który umożliwia komunikację między dwoma podmiotami, tj. Między producentami (generatorem wiadomości) a konsumentami (odbiorcą wiadomości) przy użyciu tematów opartych na wiadomości i stanowi platformę do zarządzania wszystkimi kanały danych w czasie rzeczywistym.
Funkcje, które sprawiają, że Apache Kafka jest lepszy od innych systemów przesyłania wiadomości i ma zastosowanie w systemach czasu rzeczywistego, to jego wysoka dostępność, natychmiastowe, automatyczne odzyskiwanie po awariach węzłów i obsługa dostarczania wiadomości o niskim opóźnieniu. Te cechy Apache Kafka pomagają w integracji z wielkoskalowymi systemami danych i sprawiają, że jest to idealny element komunikacji. 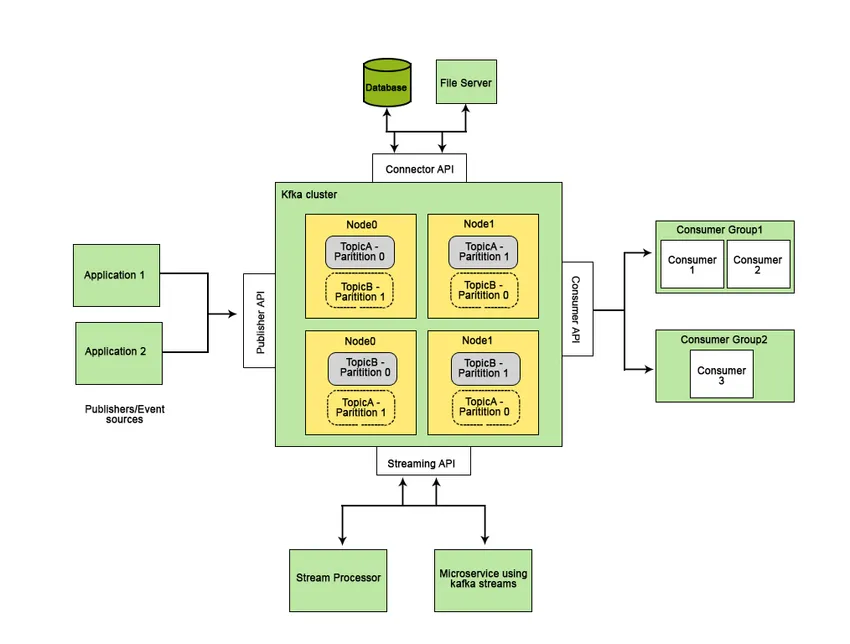
Najlepsze aplikacje Kafka
W tej części artykułu zobaczymy popularne i szeroko wdrażane przypadki użycia oraz rzeczywiste wdrożenie Kafki.
Rzeczywiste aplikacje
1. Twitter: Aktywność przetwarzania strumieniowego
Twitter to platforma społecznościowa, która wykorzystuje Storm-Kafka (narzędzie do przetwarzania strumieniowego typu open source) jako część infrastruktury przetwarzania strumieniowego, w której dane wejściowe (tweety) są wykorzystywane do agregacji, transformacji i wzbogacenia w celu dalszego wykorzystania lub śledzenia czynności związane z przetwarzaniem.
2. LinkedIn: Przetwarzanie i pomiary strumieniowe
LinkedIn używa Kafki do przesyłania strumieniowego danych i do pomiaru wskaźników operacyjnych. LinkedIn używa Kafki do dodatkowych funkcji, takich jak Newsfeed do odbierania wiadomości i przeprowadzania analizy otrzymanych danych.
3. Netflix: monitorowanie w czasie rzeczywistym i przetwarzanie strumieniowe
Netflix ma własną strukturę przetwarzania, która zrzuca dane wejściowe w AWS S3 i używa Hadoop do przeprowadzania analiz strumieni wideo, działań interfejsu użytkownika, zdarzeń w celu poprawy komfortu użytkowania, a Kafka do pobierania danych w czasie rzeczywistym za pośrednictwem interfejsów API.
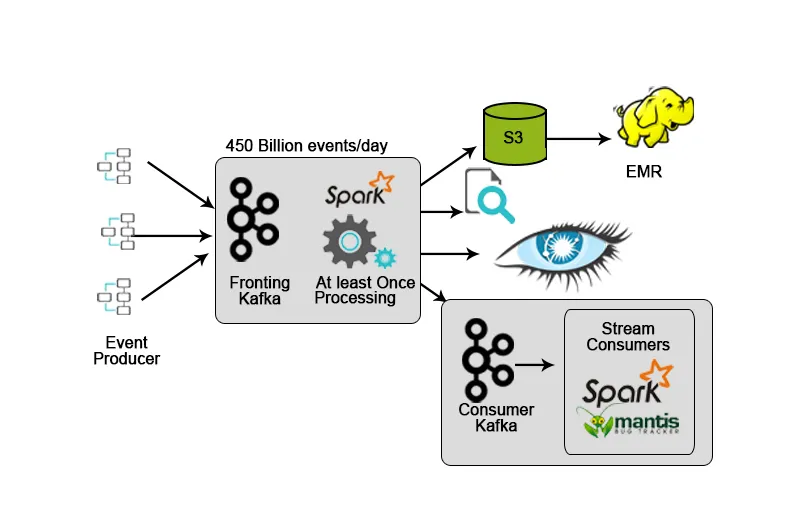
4. Hotstar: przetwarzanie strumieniowe
Hotstar wprowadził własną platformę zarządzania danymi - Bifrost, w której Kafka służy do strumieniowego przesyłania danych, monitorowania i śledzenia celów. Ze względu na jego skalowalność, dostępność i możliwości opóźnień Kafka był idealnym wyborem do obsługi danych generowanych przez platformę hotstar codziennie lub na specjalne okazje (transmisje strumieniowe na żywo z koncertów, meczów sportowych itp.), Gdzie ilość danych znacznie wzrasta.
Apache Kafka przez większość czasu jest wykorzystywany jako element budujący architekturę przesyłania danych strumieniowych. Tego rodzaju architektura jest używana w aplikacjach, takich jak zbiór dzienników produktu / serwera, analiza strumienia kliknięć i uzyskiwanie informacji z danych generowanych maszynowo.
Ale wraz z Kafką musimy używać dodatkowych zasobów lub narzędzi do przekształcania uzyskanego strumienia danych w sensowne dane, które pomagają w uzyskiwaniu wglądu, który można wykorzystać w decyzjach opartych na danych. Na przykład może być konieczne wygenerowanie wglądu w surowe dane uzyskane z urządzeń IoT lub danych uzyskanych z platform mediów społecznościowych w czasie rzeczywistym oraz wykonanie analizy lub przetwarzania i zaprezentowanie go firmie, aby podejmowała lepsze decyzje lub pomagała im w ulepszaniu wydajność ich usług.
W przypadku tego typu przypadków chcielibyśmy przesyłać nasze dane wejściowe / surowe dane do jeziora danych, w którym możemy przechowywać nasze dane i zapewnić jakość danych bez obniżania wydajności.
Inna sytuacja, w której możemy czytać dane bezpośrednio z Kafki, polega na tym, że potrzebujemy wyjątkowo niskich opóźnień między końcami, takich jak podawanie danych do aplikacji w czasie rzeczywistym.
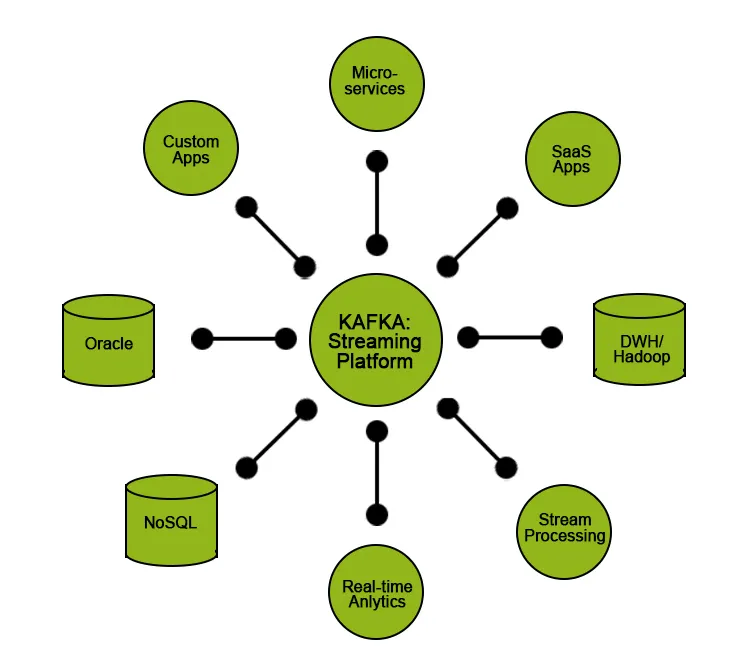
Kafka udostępnia użytkownikom pewne funkcje:
- Publikuj i subskrybuj dane.
- Przechowuj dane w kolejności, w jakiej zostały wygenerowane wydajnie.
- Przetwarzanie danych w czasie rzeczywistym / w locie.
Kafka przez większość czasu służy do:
- Wdrożenie potokowych strumieni danych w locie, które niezawodnie uzyskują dane między dwoma podmiotami w systemie.
- Wdrażanie aplikacji strumieniowych w locie, które przekształcają, przetwarzają lub przetwarzają strumienie danych.
Przypadków użycia
Poniżej znajdują się niektóre szeroko stosowane przypadki użycia aplikacji Kafka:
1. Wiadomości
Kafka działa lepiej niż inne tradycyjne systemy przesyłania wiadomości, takie jak ActiveMQ, RabbitMQ itp. Dla porównania, Kafka oferuje lepszą przepustowość, wbudowane funkcje partycjonowania, replikacji i odporności na uszkodzenia, co czyni go lepszym systemem przesyłania wiadomości dla aplikacji przetwarzających na dużą skalę .
2. Śledzenie aktywności na stronie
Działania użytkownika (wyświetlenia strony, wyszukiwania lub wszelkie wykonane działania) można śledzić i karmić w celu monitorowania lub analizy w czasie rzeczywistym za pośrednictwem Kafki lub używać Kafki do przechowywania tego rodzaju danych w Hadoop lub hurtowni danych w celu późniejszego przetwarzania lub manipulacji. Śledzenie aktywności generuje ogromną ilość danych, które należy przenieść do wybranej lokalizacji bez jakiejkolwiek utraty danych.
3. Zaloguj się Agregacja
Agregacja dziennika to proces gromadzenia / scalania fizycznych plików dziennika z różnych serwerów aplikacji w jednym repozytorium (serwer plików lub HDFS) w celu przetworzenia. Kafka oferuje dobrą wydajność, niższe opóźnienie end-to-end w porównaniu do Flume.

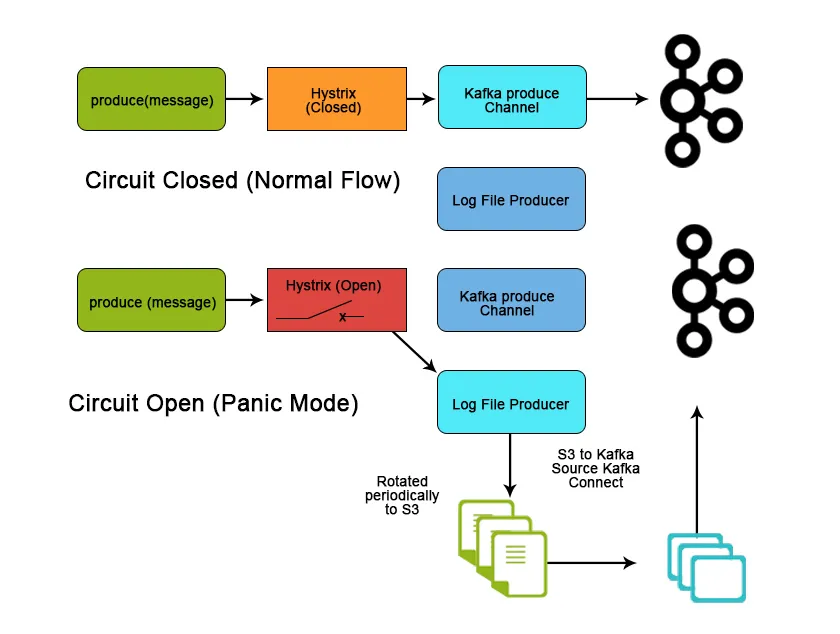
Wniosek
Kafka jest intensywnie wykorzystywany w przestrzeni dużych zbiorów danych jako sposób na szybkie pobieranie i przenoszenie dużych ilości danych ze względu na cechy wydajności i funkcje, które pomagają w osiągnięciu skalowalności, niezawodności i trwałości. W tym artykule omówiliśmy funkcje Apache Kafka, przypadki użycia i aplikację oraz to, co czyni ją lepszym narzędziem do przesyłania strumieniowego danych.
Polecane artykuły
To jest przewodnik po aplikacjach Kafka. Tutaj omawiamy, czym jest Kafka wraz z najlepszymi aplikacjami Kafki, które obejmują szeroko wdrażane przypadki użycia i niektóre rzeczywiste wdrożenia. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej-
- Co to jest Kafka?
- Jak zainstalować Kafka?
- Pytania do wywiadu Kafki
- Apache Kafka vs Flume
- 8 najlepszych urządzeń IoT, które powinieneś znać
- Kafka vs Kinesis | Różnice z infografikami
- Różne rodzaje narzędzi Kafka z komponentami
- Poznaj najważniejsze różnice między ActiveMQ a Kafką