
Wprowadzenie do hierarchicznego grupowania
- Niedawno jeden z naszych klientów poprosił nasz zespół o przedstawienie listy segmentów z kolejnością ważności wśród klientów, aby nakierować ich na franchising jednego z ich nowo wprowadzonych produktów. Najwyraźniej samo segmentowanie klientów za pomocą częściowego grupowania (k-średnie, c-rozmyte) nie wyda kolejności, w której pojawia się hierarchiczna klastracja.
- Hierarchiczne grupowanie polega na rozdzielaniu danych na różne grupy w oparciu o pewne miary podobieństwa znane jako klastry, które zasadniczo mają na celu budowanie hierarchii między klastrami. Jest to w zasadzie nauka bez nadzoru, a wybór atrybutów do pomiaru podobieństwa zależy od aplikacji.
Klaster hierarchii danych
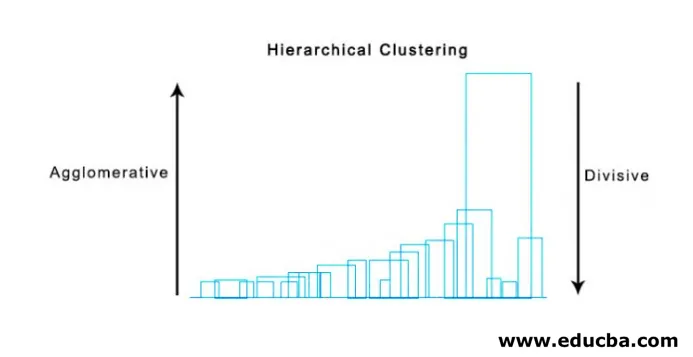
- Grupowanie aglomeracyjne
- Grupowanie dzielące
Weźmy przykład danych, ocen uzyskanych przez 5 uczniów, aby pogrupować je w nadchodzącym konkursie.
| Student | Znaki |
| ZA | 10 |
| b | 7 |
| do | 28 |
| re | 20 |
| mi | 35s |
1. Grupowanie aglomeracyjne
- Na początek bierzemy pod uwagę wagę każdego pojedynczego punktu / elementu jako skupienia i kontynuujemy łączenie podobnych punktów / elementów, aby utworzyć nowy klaster na nowym poziomie, dopóki nie zostaniemy z pojedynczym skupieniem, co jest podejściem oddolnym.
- Pojedyncze połączenie i pełne połączenie to dwa popularne przykłady grupowania aglomeracyjnego. Inne niż Średnie powiązanie i Centroid. W pojedynczym połączeniu łączymy na każdym etapie dwa skupiska, których dwóch najbliższych członków ma najmniejszą odległość. W pełnym połączeniu łączymy się w elementach o najmniejszej odległości, które zapewniają najmniejszą maksymalną odległość parami.
- Macierz zbliżeniowa, jest rdzeniem do wykonywania hierarchicznego grupowania, które podaje odległość między każdym z punktów.
- Stwórzmy macierz zbliżeniową dla naszych danych podanych w tabeli, ponieważ obliczamy odległość między każdym punktem z innymi punktami, będzie to macierz asymetryczna kształtu n × n, w naszym przypadku macierzy 5 × 5.
Popularną metodą obliczania odległości są:
- Odległość euklidesowa (do kwadratu)
dist((x, y), (a, b)) = √(x - a)² + (y - b)²
- Odległość na Manhattanie
dist((x, y), (a, b)) =|x−c|+|y−d|
Najczęściej stosowana jest odległość euklidesowa, użyjemy tego samego tutaj i przejdziemy ze złożonym wiązaniem.
| Student (klastry) | ZA | b | do | re | mi |
| ZA | 0 | 3) | 18 | 10 | 25 |
| b | 3) | 0 | 21 | 13 | 28 |
| do | 18 | 21 | 0 | 8 | 7 |
| re | 10 | 13 | 8 | 0 | 15 |
| mi | 25 | 28 | 7 | 15 | 0 |
Elementy ukośne macierzy zbliżeniowej będą zawsze wynosić 0, ponieważ odległość między punktem o tym samym punkcie będzie zawsze wynosić 0, dlatego elementy ukośne są wyłączone z uwzględnienia przy grupowaniu.
Tutaj, w iteracji 1, najmniejsza odległość wynosi 3, dlatego łączymy A i B, aby utworzyć klaster, ponownie tworząc nową macierz bliskości z gromadą (A, B), przyjmując punkt skupienia (A, B) jako 10, tj. Maksymalnie ( 7, 10) tak powstałaby macierz zbliżeniowa
| Klastry | (A, B) | do | re | mi |
| (A, B) | 0 | 18 | 10 | 25 |
| do | 18 | 0 | 8 | 7 |
| re | 10 | 8 | 0 | 15 |
| mi | 25 | 7 | 15 | 0 |
W iteracji 2, 7 jest minimalną odległością, dlatego łączymy C i E tworząc nową klaster (C, E), powtarzamy proces postępujący w iteracji 1, aż skończymy z pojedynczą gromadą, tutaj zatrzymujemy się na iteracji 4.
Cały proces przedstawiono na poniższym rysunku:
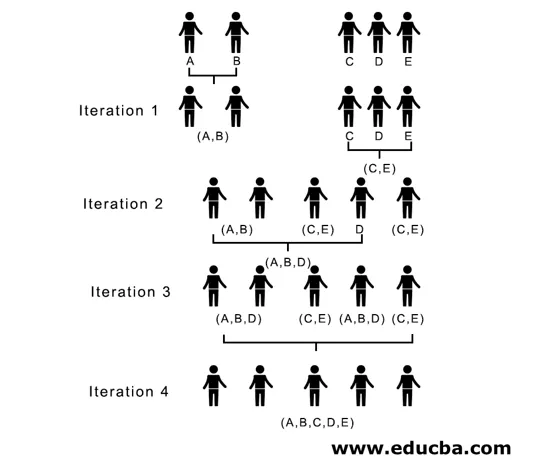
(A, B, D) i (D, E) to 2 gromady utworzone w iteracji 3, przy ostatniej iteracji widzimy, że mamy jedną gromadę.
2. Grupowanie dzielące
Na początek bierzemy pod uwagę wszystkie punkty jako jedną grupę i dzielimy je najdalszą odległością, aż zakończymy się pojedynczymi punktami jako pojedynczymi klastrami (niekoniecznie możemy zatrzymać się w środku, zależy od minimalnej liczby elementów, które chcemy w każdej grupie) na każdym kroku. Jest to przeciwieństwo grupowania aglomeracyjnego i jest podejściem odgórnym. Grupowanie dzielące to sposób, w jaki powtarzające się k oznacza grupowanie.
Wybór między skupieniem aglomeracyjnym i dzielącym jest ponownie zależny od aplikacji, ale kilka punktów, które należy wziąć pod uwagę to:
- Dzielenie jest bardziej złożone niż grupowanie aglomeracyjne.
- Klastrowanie dzielące jest bardziej wydajne, jeśli nie wygenerujemy pełnej hierarchii do poszczególnych punktów danych.
- Grupowanie aglomeracyjne podejmuje decyzję, biorąc pod uwagę lokalne wzorce, nie uwzględniając początkowo globalnych wzorców, których nie można odwrócić.
Wizualizacja hierarchicznego grupowania
Super pomocną metodą wizualizacji hierarchicznego grupowania, która pomaga w biznesie, jest Dendogram. Dendogramy są strukturami przypominającymi drzewa, które rejestrują sekwencję scalania i podziału, w których linia pionowa reprezentuje odległość między klastrami, odległość między liniami pionowymi i odległość między klastrami jest wprost proporcjonalna, tj. Im większa odległość, tym bardziej gromady mogą być różne.
Możemy użyć dendogramu, aby zdecydować o liczbie klastrów, po prostu narysuj linię, która przecina się z najdłuższą pionową linią na dendogramie, liczba przeciętych linii pionowych będzie liczbą klastrów do rozważenia.
Poniżej znajduje się przykładowy dendogram.
Istnieją dość proste i bezpośrednie pakiety Pythona i jego funkcje do wykonywania hierarchicznego grupowania i drukowania dendogramów.
- Hierarchia z Scipy.
- Cluster.hierarchy.dendogram do wizualizacji.
Typowe scenariusze, w których używana jest hierarchiczna klastrowanie
- Podział klientów na marketing produktów lub usług.
- Planowanie miasta w celu określenia miejsc do budowy konstrukcji / usług / budynku.
- Na przykład analiza sieci społecznościowych identyfikuje wszystkich fanów MS Dhoni, którzy reklamują jego biografię.
Zalety hierarchicznego grupowania
Zalety podano poniżej:
- W przypadku częściowego grupowania, takiego jak k-średnie, liczba klastrów powinna być znana przed grupowaniem, co nie jest możliwe w praktycznych zastosowaniach, podczas gdy w hierarchicznym grupowaniu nie jest wymagana wcześniejsza znajomość liczby klastrów.
- Hierarchiczne grupowanie generuje hierarchię, tj. Strukturę bardziej pouczającą niż nieustrukturyzowany zestaw płaskich klastrów zwracany przez częściowe grupowanie.
- Hierarchiczne grupowanie jest łatwe do wdrożenia.
- Ujawnia wyniki w większości scenariuszy.
Wniosek
Rodzaj klastrowania robi dużą różnicę podczas prezentacji danych, klastrowanie hierarchiczne jest bardziej pouczające i łatwe do analizy jest bardziej preferowane niż klastrowanie częściowe. I często wiąże się to z mapami ciepła. Nie należy zapominać, że atrybuty wybrane do obliczenia podobieństwa lub odmienności wpływają głównie na klastry i hierarchię.
Polecane artykuły
Jest to przewodnik po klastrowaniu hierarchicznym. Tutaj omawiamy wprowadzenie, zalety klastrowania hierarchicznego i typowe scenariusze, w których stosuje się klastrowanie hierarchiczne. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Algorytm grupowania
- Grupowanie w uczenie maszynowe
- Hierarchiczne grupowanie w R.
- Metody grupowania
- Jak usunąć hierarchię w Tableau?