
Wprowadzenie do modeli uczenia maszynowego
Przegląd różnych modeli uczenia maszynowego stosowanych w praktyce. Zgodnie z definicją model uczenia maszynowego jest konfiguracją matematyczną uzyskaną po zastosowaniu określonych metod uczenia maszynowego. Korzystając z szerokiej gamy interfejsów API, budowanie modelu uczenia maszynowego jest obecnie bardzo proste dzięki mniejszej liczbie linii kodów. Ale prawdziwa umiejętność specjalisty w dziedzinie danych stosowanych polega na wybraniu odpowiedniego modelu na podstawie zgłoszenia problemu i weryfikacji krzyżowej zamiast losowego wyrzucania danych do fantazyjnych algorytmów. W tym artykule omówimy różne modele uczenia maszynowego i sposoby ich skutecznego wykorzystania w zależności od rodzaju problemów, które rozwiązują.
Rodzaje modeli uczenia maszynowego
Na podstawie rodzaju zadań możemy sklasyfikować modele uczenia maszynowego według następujących typów:
- Modele klasyfikacyjne
- Modele regresji
- Grupowanie
- Redukcja wymiarów
- Głębokie uczenie się itp.
1) Klasyfikacja
W odniesieniu do uczenia maszynowego klasyfikacja jest zadaniem przewidywania typu lub klasy obiektu w ramach skończonej liczby opcji. Zmienna wyjściowa do klasyfikacji jest zawsze zmienną kategoryczną. Na przykład przewidywanie wiadomości e-mail jako spam lub nie jest standardowym zadaniem binarnej klasyfikacji. Teraz zanotujmy kilka ważnych modeli problemów z klasyfikacją.
- Algorytm najbliższych sąsiadów K - prosty, ale wyczerpujący obliczeniowo.
- Naive Bayes - Na podstawie twierdzenia Bayesa.
- Regresja logistyczna - model liniowy do klasyfikacji binarnej.
- SVM - może być używany do klasyfikacji binarnych / wieloklasowych.
- Drzewo decyzyjne - klasyfikator oparty na „ If Else ”, bardziej odporny na wartości odstające.
- Zespoły - połączenie wielu modeli uczenia maszynowego ze sobą w celu uzyskania lepszych wyników.
2) Regresja
W maszynie regresja uczenia się jest zbiorem problemów, w których zmienna wyjściowa może przyjmować ciągłe wartości. Na przykład prognozowanie ceny linii lotniczych można uznać za standardowe zadanie regresji. Zwróćmy uwagę na kilka ważnych modeli regresji stosowanych w praktyce.
- Regresja liniowa - najprostszy model linii bazowej dla zadania regresji, działa dobrze tylko wtedy, gdy dane można rozdzielić liniowo i bardzo mało lub nie ma wielokoliniowości.
- Regresja Lasso - regresja liniowa z regularyzacją L2.
- Regresja grzbietowa - regresja liniowa z regularyzacją L1.
- Regresja SVM
- Regresja drzewa decyzyjnego itp.
3) Klastrowanie
Krótko mówiąc, grupowanie podobnych obiektów polega na grupowaniu. Modele uczenia maszynowego pomagają automatycznie identyfikować podobne obiekty bez ręcznej interwencji. Nie możemy budować skutecznych nadzorowanych modeli uczenia maszynowego (modeli, które należy szkolić przy użyciu ręcznie wyselekcjonowanych lub oznakowanych danych) bez jednorodnych danych. Klastrowanie pomaga nam to osiągnąć w mądrzejszy sposób. Oto niektóre z najczęściej używanych modeli klastrowania:
- K oznacza - Prosty, ale cierpi z powodu dużej wariancji.
- K oznacza ++ - Zmodyfikowana wersja K oznacza.
- K medoidy.
- Grupowanie aglomeracyjne - hierarchiczny model grupowania.
- DBSCAN - algorytm grupowania oparty na gęstości itp.
4) Redukcja wymiarów
Wymiarowanie to liczba zmiennych predykcyjnych używanych do przewidywania zmiennej niezależnej lub celu. Często w zestawach danych świata rzeczywistego liczba zmiennych jest zbyt wysoka. Zbyt wiele zmiennych powoduje również przekleństwo nadmiernego dopasowania do modeli. W praktyce wśród tak dużej liczby zmiennych nie wszystkie zmienne przyczyniają się w równym stopniu do celu, aw wielu przypadkach możemy faktycznie zachować wariancje przy mniejszej liczbie zmiennych. Wymieńmy niektóre często używane modele redukcji wymiarów.
- PCA - Tworzy mniejszą liczbę nowych zmiennych z dużej liczby predyktorów. Nowe zmienne są od siebie niezależne, ale mniej interpretowalne.
- TSNE - zapewnia osadzanie niższych wymiarów punktów danych o wyższych wymiarach.
- SVD - Dekompozycja pojedynczej wartości służy do dekompozycji macierzy na mniejsze części w celu wydajnego obliczenia.
5) Głębokie uczenie się
Głębokie uczenie się jest podzbiorem uczenia maszynowego, który dotyczy sieci neuronowych. W oparciu o architekturę sieci neuronowych wypiszmy ważne modele głębokiego uczenia:
- Perceptron wielowarstwowy
- Convolution Neural Networks
- Nawracające sieci neuronowe
- Maszyna Boltzmann
- Autoencodery itp.
Który model jest najlepszy?
Powyżej wzięliśmy pomysły na wiele modeli uczenia maszynowego. Teraz przychodzi nam na myśl oczywiste pytanie: „Który model jest najlepszy?” Zależy to od aktualnego problemu i innych powiązanych atrybutów, takich jak wartości odstające, ilość dostępnych danych, jakość danych, inżynieria funkcji itp. W praktyce zawsze lepiej jest zacząć od najprostszego modelu właściwego dla problemu i zwiększyć złożoność stopniowo poprzez odpowiednie dostrajanie parametrów i walidację krzyżową. W świecie nauk o danych istnieje przysłowie: „Walidacja krzyżowa jest bardziej godna zaufania niż wiedza dziedzinowa”.
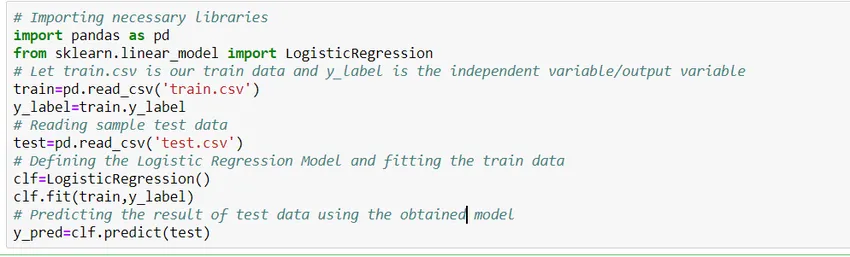
Jak zbudować model?
Zobaczmy, jak zbudować prosty model regresji logistycznej przy użyciu biblioteki Scikit Learn w Pythonie. Dla uproszczenia zakładamy, że problemem jest standardowy model klasyfikacji, a „train.csv” oznacza pociąg, a „test.csv” odpowiednio dane dotyczące pociągu i testu.
Wniosek
W tym artykule omówiliśmy ważne modele uczenia maszynowego wykorzystywane do celów praktycznych i jak zbudować prosty model uczenia maszynowego w Pythonie. Wybór odpowiedniego modelu dla konkretnego przypadku użycia jest bardzo ważny, aby uzyskać właściwy wynik zadania uczenia maszynowego. Aby porównać wydajność między różnymi modelami, dla poszczególnych problemów biznesowych definiuje się wskaźniki oceny lub kluczowe wskaźniki wydajności, a po zastosowaniu statystycznego sprawdzania wydajności wybiera się najlepszy model do produkcji.
Polecane artykuły
Jest to przewodnik po modelach uczenia maszynowego. Tutaj omawiamy 5 najlepszych typów modeli uczenia maszynowego wraz z jego definicją. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Metody uczenia maszynowego
- Rodzaje uczenia maszynowego
- Algorytmy uczenia maszynowego
- Co to jest uczenie maszynowe?
- Uczenie maszynowe hiperparametrów
- KPI w Power BI
- Hierarchiczny algorytm grupowania
- Hierarchiczne grupowanie | Grupowanie aglomeracyjne i dzielące