
Definicja algorytmu średniej zmiany
Algorytm przesunięcia średniego podlega uczeniu bez nadzoru, które jest klasyfikowane jako algorytm grupowania. Ideologia algorytmu Mean Shift polega na tym, że iteracyjnie przypisuje punkty danych do klastrów, przesuwając się w kierunku punktu o najwyższym punkcie gęstości (Mode). Logika leżąca u podstaw przesunięcia opiera się na koncepcji szacowania gęstości jądra, zwanej KDE.
Grupowanie algorytmów średniej zmiany
Technika uczenia się bez nadzoru odkryta przez Fukunaga i Hostetlera w celu znalezienia klastrów:
- Mean Shift jest również znany jako algorytm wyszukiwania trybu, który przypisuje punkty danych do klastrów w pewien sposób, przesuwając punkty danych w kierunku regionu o wysokiej gęstości. Najwyższą gęstość punktów danych określa się jako model w regionie. Algorytm Mean Shift ma aplikacje szeroko stosowane w dziedzinie wizji komputerowej i segmentacji obrazu.
- KDE to metoda szacowania rozkładu punktów danych. Działa poprzez umieszczenie jądra w każdym punkcie danych. Jądro w matematyce jest funkcją ważenia, która zastosuje wagi dla poszczególnych punktów danych. Dodanie wszystkich poszczególnych jąder generuje prawdopodobieństwo.
Funkcja jądra jest wymagana do spełnienia następujących warunków:
- Pierwszym wymaganiem jest upewnienie się, że oszacowanie gęstości jądra jest znormalizowane.
- Drugim wymaganiem jest to, aby KDE było dobrze powiązane z symetrią przestrzeni.
Dwie popularne funkcje jądra
Poniżej znajdują się dwie popularne funkcje jądra:
- Płaskie jądro
- Jądro Gaussa
- W zależności od zastosowanego parametru jądra wynikowa funkcja gęstości jest różna. Jeśli nie podano parametru jądra, jądro Gaussa jest domyślnie wywoływane. KDE wykorzystuje koncepcję funkcji gęstości prawdopodobieństwa, która pomaga znaleźć lokalne maksima rozkładu danych. Algorytm działa tak, aby punkty danych przyciągały się wzajemnie, pozwalając punktom danych w kierunku obszaru o wysokiej gęstości.
- Punkty danych, które próbują zbliżyć się do lokalnych maksimów, będą należeć do tej samej grupy klastrów. W przeciwieństwie do algorytmu klastrowania K-Means, wynik algorytmu Mean Shift nie zależy od założeń dotyczących kształtu punktu danych i liczby klastrów. Liczba klastrów zostanie określona przez algorytm w odniesieniu do danych.
- Aby wykonać implementację algorytmu Mean Shift, korzystamy z pakietu python SKlearn.
Implementacja algorytmu średniej zmiany
Poniżej znajduje się implementacja algorytmu:
Przykład 1
Na podstawie samouczka Sklearn dotyczącego algorytmu analizy średniej zmiany klastrowej. Pierwszy fragment zaimplementuje algorytm przesunięcia średniego, aby znaleźć klastry dwuwymiarowego zestawu danych. Pakiety używane do implementacji algorytmu średniej zmiany.
Kod:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Jedną kluczową rzeczą do odnotowania jest to, że będziemy używać biblioteki make_blobs sklearn do generowania punktów danych wyśrodkowanych w 3 lokalizacjach. Aby zastosować algorytm przesunięcia średniego do generowanych punktów, musimy ustawić szerokość pasma, która reprezentuje interakcję między długością. Biblioteka Sklearn ma wbudowane funkcje do szacowania przepustowości.
Kod:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
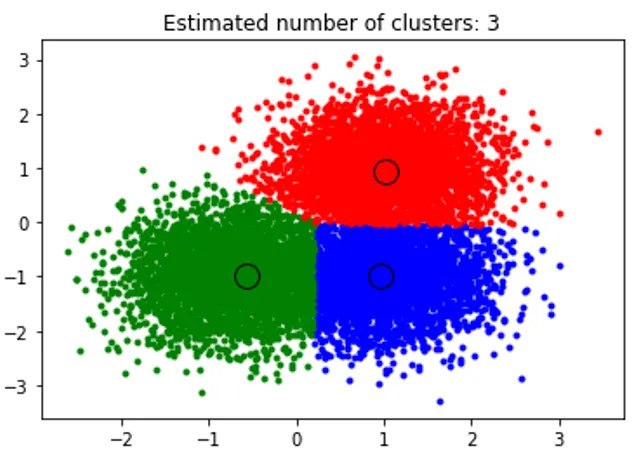
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Powyższy fragment kodu wykonuje grupowanie, a algorytm znalazł skupienia na środku każdego wygenerowanego obiektu blob. Widzimy, że z poniższego obrazu wykreślonego przez fragment kodu pokazuje algorytm przesunięcia średniego, który jest w stanie zidentyfikować liczbę klastrów potrzebnych w czasie wykonywania i obliczyć odpowiednią szerokość pasma do reprezentacji długości interakcji.
Wynik:
Przykład nr 2
Na podstawie segmentacji obrazu w obrazie komputerowym. Drugi fragment bada, w jaki sposób algorytm przesunięcia średniego używany w głębokim uczeniu się do przeprowadzania segmentacji kolorowego obrazu. Korzystamy z algorytmu średniej zmiany w celu identyfikacji klastrów przestrzennych. Wcześniejszy fragment użyliśmy zestawu danych 2D, podczas gdy w tym przykładzie będziemy badać przestrzeń 3D. Piksel obrazu będzie traktowany jako punkty danych (r, g, b). Musimy przekonwertować obraz na format tablicowy, aby każdy piksel reprezentował punkt danych na obrazie, który przechodzimy do segmentu. Grupowanie wartości kolorów w przestrzeni zwraca serię klastrów, w których piksele w klastrze będą podobne do przestrzeni RGB. Pakiety używane do implementacji algorytmu średniej zmiany:
Kod:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Poniżej fragmentu, aby przeprowadzić segmentację obrazu oryginalnego:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Wygenerowany obraz stwierdza, że takie podejście do identyfikacji kształtów obrazów i określenia klastrów przestrzennych można skutecznie wykonać bez przetwarzania obrazu.
Wynik:


Korzyści i zastosowania Algorytm średniej zmiany
Poniżej przedstawiono zalety i zastosowanie średniego algorytmu:
- Jest szeroko stosowany do rozwiązywania wizji komputerowej, gdzie jest wykorzystywany do segmentacji obrazu.
- Klastrowanie punktów danych w czasie rzeczywistym bez podawania liczby klastrów.
- Dobrze sprawdza się w segmentacji obrazów i śledzeniu wideo.
- Bardziej odporne na wartości odstające.
Zalety algorytmu średniej zmiany
Poniżej znajduje się algorytm przesunięcia średniej zalet:
- Dane wyjściowe algorytmu są niezależne od inicjalizacji.
- Procedura jest skuteczna, ponieważ ma tylko jeden parametr - przepustowość.
- Brak założeń dotyczących liczby klastrów danych i kształtu.
- Ma lepszą wydajność niż K-Means Clustering.
Wady algorytmu średniej zmiany
Poniżej znajdują się wady algorytmu średniej zmiany:
- Drogie w przypadku dużych funkcji.
- W porównaniu do grupowania K-Means jest bardzo wolny.
- Wyjście algorytmu zależy od przepustowości parametru.
- Dane wyjściowe zależą od wielkości okna.
Wniosek
Chociaż jest to proste podejście, które przede wszystkim służyło do rozwiązywania problemów związanych z segmentacją obrazu, grupowaniem. Jest stosunkowo wolniejszy niż K-Means i jest drogi pod względem obliczeniowym.
Polecane artykuły
To jest przewodnik po algorytmie Mean Shift. Tutaj omawiamy problemy związane z segmentacją obrazu, klastrowaniem, korzyściami i dwiema funkcjami jądra. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej-
- K- oznacza algorytm grupowania
- Algorytm KNN w R.
- Co to jest algorytm genetyczny?
- Metody jądra
- Metody jądra w uczeniu maszynowym
- Szczegółowy opis algorytmu C ++