

Kariera w Hadoop - Wprowadzenie
Hadoop nie jest zwykłą strukturą w świecie Big Data. Ma szeroki ekosystem z parasolem powiązanych technologii. Z tego samego powodu kariera w Hadoop jest obiecująca. Jeśli dobrze rozumiesz podstawy Hadoop, będzie to podstawa wspaniałej kariery w Hadoop.
Edukacja do kariery w Hadoop
Podobnie jak wiele nowych technologii danych, Hadoop nie wymaga żadnego konkretnego wykształcenia. Około połowa programistów Hadoop pochodzi z środowisk innych niż informatyka, takich jak statystyka czy fizyka. Jest więc jasne, że tło nie jest przeszkodą w wejściu do świata Hadoop, pod warunkiem, że jesteś gotowy do nauki podstaw. Istnieją dobre kursy online obejmujące Hadoop - ten z eduCBA jest najlepszym przykładem - master-apache-Hadoop
Ponadto, jeśli chcesz głębiej przejść do określonego obszaru zarządzania klastrami Hadoop lub modelowania danych w materiałach Hive na każdy konkretny temat dostępny jako kursy online i podręczniki. Przez większość czasu klastry Hadoop będą konfigurowane w dostawcy usług w chmurze, takim jak AWS lub Azure. Zapoznanie się z dowolnym wybranym dostawcą chmury bardzo pomoże. Usługa Hadoop od AWS nazywa się EMR.
Popularna specjalizacja obejmuje:
- Spark - skalowalny silnik przetwarzania danych w pamięci
- HBase - brak bazy danych SQL na HDFS
- Wiązka - przetwarzanie danych pierwszego podejścia
- Pig - skryptowanie transformacji danych (ETL)
- Hive - hurtownia danych
- Mahout, Spark MLlib - skalowalne uczenie maszynowe w Hadoop
- Apache Drill - silnik SQL na Hadoop
- Flume, Sqoop - Usługi przetwarzania danych
- Solr & Lucene - Wyszukiwanie i indeksowanie
Ścieżka kariery w Hadoop
Zgodnie z wynikami Stack Overflow Survey 2017, Hadoop jest liderem w najpopularniejszym i najbardziej lubianym frameworku w przestrzeni Big Data (Survey Link). Jest to możliwe tylko dlatego, że ludzie z innej perspektywy IT uznali Hadoop za potencjalną ścieżkę kariery i chcą się zmienić.
Bez względu na twoją obecną rolę w roli IT, łatwo będzie dostosować się do kariery w świecie Hadoop. Niektóre popularne przykłady -
- Software Developer (programista) -> Hadoop Data Developer, który zajmuje się różnymi pakietami SDK abstrakcji Hadoop i czerpie wartość z danych.
- Analityk danych -> Więc jesteś biegły w SQL. Ogromna szansa w Hadoop do pracy na silnikach SQL takich jak Hive lub Impala
- Business Analyst -> Organizacje próbujące stać się bardziej rentowne przy użyciu masowo gromadzonych danych, a rola analityka biznesowego jest w tym kluczowa.
- Deweloper ETL -> Jeśli pracujesz jako tradycyjny programista ETL, możesz łatwo przejść do ETL Hadoop za pomocą narzędzi takich jak Spark.
- Testerzy -> W świecie Hadoop istnieje ogromne zapotrzebowanie na testerów. Dzięki zrozumieniu podstaw Hadoop i profilowania danych, każdy tester może przejść do tej roli.
- Zawody BI / DW -> Można łatwo przełączyć na architekturę danych Hadoop na modelowanie danych.
- Starsi specjaliści IT -> Dzięki dogłębnemu zrozumieniu domeny i istniejących wyzwań w świecie danych, starszy specjalista może zostać konsultantem, zdobywając wiedzę o tym, jak Hadoop próbuje rozwiązać te wyzwania.
- Istnieją ogólne role, takie jak inżynierowie danych lub inżynierowie Big Data, którzy są odpowiedzialni za wdrażanie rozwiązań głównie w oparciu o dostawców usług w chmurze. Zdobycie wiedzy o składnikach danych zapewnianych przez chmurę będzie stanowić obiecującą rolę.
Stanowiska pracy
Ekosystem Hadoop oferuje różnorodne ścieżki kariery
- MapReduce Developer - Zasadniczo rola programisty Java, która również rozumie, w jaki sposób systemy Hadoop działają wewnętrznie. Dostępna jest abstrakcja w rodzaju Hive lub Pig. Zadania MapReduce są niezbędne dla systemów o wysokiej wydajności. Programiści MapReduce rozumieją system wchodzący i wychodzący i płacą naprawdę wysoką kwotę.
- Administratorzy Hadoop - są to osoby odpowiedzialne za utrzymywanie klastra Hadoop w dobrej kondycji i wydajności. Może to obejmować typowe zadania administratora, takie jak regularne kontrole kondycji systemu, ale większość zadań potrzebnych do zrozumienia architektury systemu Hadoop.
- Devops - Wdróż nowe komponenty systemu i inne zmiany związane z programowaniem w klastrze Hadoop. Odpowiedzialność za tę rolę jest bardzo zróżnicowana i zależy od kultury organizacji.
- Deweloper danych - przetwarzanie danych na platformie Hadoop. Ta jedna z najpopularniejszych ról w ekosystemie Hadoop: osoby z SQL lub tła analitycznego najlepiej pasują do tych ról. Przeważnie pracuj nad abstrakcją Hadoop na wysokim poziomie, taką jak Hive lub Pig.
- Administrator bezpieczeństwa danych - Dane są najcenniejszymi zasobami, a ich zabezpieczenie jest najważniejsze. Administratorzy bezpieczeństwa zapewniają standardowe zasady branżowe i najlepsze praktyki w celu ochrony danych, z ograniczeniem zrozumienia systemu
- Wizualizator danych - Obsługa narzędzi wizualizacji nowej generacji, które umożliwiają dynamiczne dzielenie i agregowanie danych z buforowaniem danych w pamięci
- Deweloper ETL - przekształcaj dane w celu poprawy jakości danych lub zgodnie z logiką biznesową za pomocą narzędzi ekosystemu Hadoop. Proces ETL może być przesyłaniem strumieniowym lub wsadowym.
- Architekt systemu - Projektuj wydajne systemy, biorąc pod uwagę dostępność i trwałość danych w opłacalny sposób. Zależy w dużej mierze od dostawcy sprzętu.
- Architekt danych - Oprócz tradycyjnego logicznego / fizycznego projektowania danych, wiele rzeczy takich jak kodowanie kolumn, denormalizacja, projektowanie partycjonowania itp. Będzie odpowiedzialnością architekta danych.
Polecane kursy
- Szkolenie online XML i Java
- Kursy Node.JS
- Szkolenie Silverlight
- Program Ember.JS
Wynagrodzenie
Średnia pensja programisty w USA wynosi 90 956 USD rocznie, podczas gdy średnia pensja programisty Hadoop jest znacznie wyższa - 118 234 USD rocznie (według Indeed.com - rzeczywiście.com)
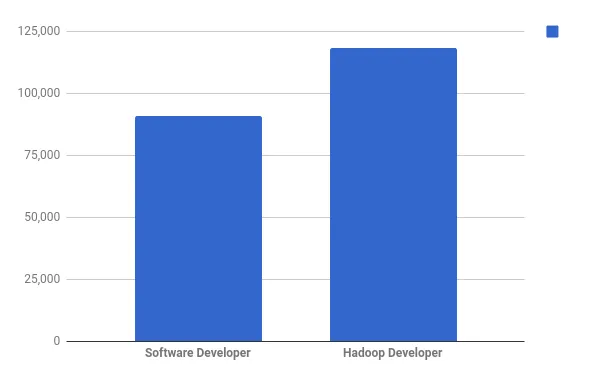
Wynagrodzenia programisty Hadoop w najlepszych firmach w USA (zob .: istotnie.com)
| jabłko | 147 573 USD rocznie |
| Wipro | 110 553 USD rocznie |
| HERO.jobs | 158 715 USD rocznie |
| MBCAA | 133 422 USD rocznie |
| Ventures Unlimited Inc | 130 000 USD rocznie |
| Nityo Infotech Services Pvt. Sp. z o.o. | 128 633 USD rocznie |
| GWIAZDA PÓŁNOCNA | 126 370 USD rocznie |
| Technologia PRI | 121 396 USD rocznie |
| NITYO INFOTECH | 116 909 USD rocznie |
| HortonWorks, Inc | 110 710 USD rocznie |
Perspektywy kariery
Ekosystem Hadoop bardzo się rozbiera, aby sprostać zmianie potrzeb biznesowych. Ponieważ generowane dane rosną wykładniczo, a coraz więcej organizacji kieruje się danymi, znaczenie systemu Hadoop będzie coraz większe.
Niektóre z ważnych trendów:
- Przejdź od przetwarzania wsadowego do pierwszego przetwarzania strumieniowego przy użyciu Spark i Beam
- Więcej modelu uczenia maszynowego w czasie rzeczywistym zastosowanego do danych w czasie rzeczywistym przy użyciu Spark ML
- Silniki SQL oddzielone od przechowywania danych, takie jak Presto na S3, do analizy ad hoc na jeziorze danych.
- Kolumnowe bazy danych MPP, takie jak AWS Redshift, zapewniające szybki dostęp do danych
Ponieważ podstawowym aspektem przetwarzania dużych zbiorów danych są odporne na awarie rozproszone i skalowalne w poziomie systemy, które jest dobrze wdrożone przez Hadoop, Hadoop pozostanie wiodącym ekosystemem przetwarzania danych.
Polecany artykuł
To był przewodnik po Karierze w Hadoop. Omówiliśmy wprowadzenie, edukację, ścieżkę kariery w Hadoop, wynagrodzenie i perspektywę kariery w Hadoop. możesz również zapoznać się z następującym artykułem, aby dowiedzieć się więcej -
- Azure Paas vs Iaas i ich przydatne zalety
- Znajdź różnice między Java a Node JS
- Najlepsze porady ekspertów dotyczące kariery w komputerach mainframe
- Kariery w SQL
- Przydatne kariery jako inżynier oprogramowania
- Administrator Hadoop | Ścieżki umiejętności i kariery