

Co to jest funkcja Hive?
Jak wiemy dzisiaj, Hadoop jest jedną z wszechstronnych technologii w zakresie dużych zbiorów danych. Hadoop ma zdolność radzenia sobie z dużym zbiorem danych, ale ponieważ wzrost danych jest proporcjonalny, pisanie programów zmniejszających mapę staje się trudne. Aby wykonywać zapytania SQL, obecne w HDFS, jedna z takich technologii została wprowadzona przez Hadoop o nazwie Apache Hive, uruchomiona przez Facebook. Hive jest bardzo wykorzystywane przez analityka danych. Są one wdrażane dla trzech funkcji, a mianowicie: podsumowania danych, analizy danych w plikach rozproszonych i zapytań o dane. Hive zapewnia zapytania podobne do SQL zwane HQL - język wysokich zapytań obsługuje DML, funkcje zdefiniowane przez użytkownika. Kompilator Hive konwertuje wewnętrznie to zapytanie na zadania zmniejszające mapę, co upraszcza pracę Hadoop w pisaniu złożonych programów. Możemy znaleźć gałąź w aplikacjach takich jak hurtownie danych, wizualizacja danych i analiza ad hoc, Google Analytics. Kluczową zaletą jest to, że korzystają z wiedzy SQL, która jest podstawową umiejętnością wdrażaną przez badaczy danych i specjalistów od oprogramowania.
Różne funkcje ula w szczegółach
Hive obsługuje różne typy danych, których nie ma w innych systemach baz danych. zawiera mapę, tablicę i strukturę. Hive ma wbudowane funkcje do wykonywania kilku funkcji matematycznych i arytmetycznych do specjalnego celu. Funkcje w gałęzi można podzielić na następujące typy. Są to funkcje wbudowane i funkcje zdefiniowane przez użytkownika.
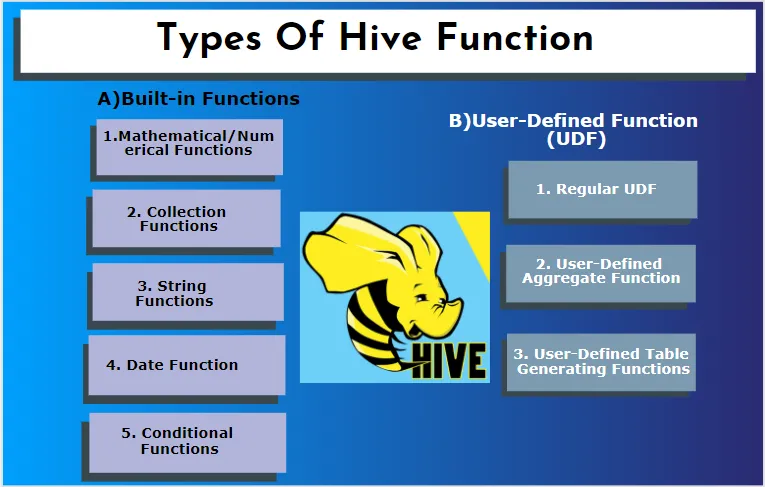
A) Wbudowane funkcje
Funkcje te wyodrębniają dane z tabel gałęzi i przetwarzają obliczenia. Niektóre z wbudowanych funkcji to:
1. Funkcje matematyczne / numeryczne
Funkcje te są używane głównie do obliczeń matematycznych. Te funkcje są używane w zapytaniach SQL.
| Nazwa funkcji | Przykład | Opis |
| ABS (podwójne x) | Hive> wybierz ABS (-200) z tmp; | Zwróci wartość bezwzględną liczby. |
| CEIL (podwójny x) | Hive> wybierz CEIL (8.5) z tmp; | Pobiera najmniejszą liczbę całkowitą większą lub równą wartości x. |
| Rand (), rand (int seed) | Hive> wybierz Rand () z tmp;
Rand (0–9) | Zwraca liczbę losową, w zależności od wartości początkowej generowane liczby losowe byłyby deterministyczne. |
| Pow (podwójne x, podwójne y) | Hive> wybierz Pow (5, 2) z tmp; | Zwraca wartość x podniesioną do potęgi y. |
| PODŁOGA (podwójne y) | Hive> wybierz FLOOR (11.8) z tmp; | Zwraca maksymalną liczbę całkowitą mniejszą lub równą, aby dać wartość y. |
| Termin ważności (podwójny a) | Hive> wybierz Exp (30) z tmp; | Zwróci wartość wykładnika wynoszącą 30. wartości algorytmu naturalnego. |
| PMOD (int a, int b) | Hive> wybierz PMOD (2, 4) z tmp; | Daje dodatni moduł liczby. |
2. Funkcje kolekcji
Zrzucanie wszystkich elementów razem i zwracanie pojedynczych elementów zależy od dołączonego typu danych.
| Nazwa funkcji | Przykład | Opis |
| Wartości map (mapa) | Hive> wybierz Wartości mapy („cześć”, 45) | Pobiera nieuporządkowane elementy tablicy. |
| Rozmiar (mapa) | Hive> wybierz rozmiar (mapa) | Zwraca liczbę elementów na mapie typu danych. |
| Array_contains (Array b) | Hive> select array_contains (a (10)) | Zwraca wartość PRAWDA, jeśli tablica zawiera wartość. |
| Sort_array (Array a) | Hive> wybierz sort_array ((10, 3, 6, 1, 7)) | Sortuje tablicę wejściową w porządku rosnącym zgodnie z naturalnym uporządkowaniem elementów tablicy i zwraca wartość. |
3. Funkcje ciągów
Przy użyciu funkcji łańcuchowych analiza danych jest przeprowadzana doskonale.
| Podział (ciąg s, ciąg pat) | Hive> wybierz wyjście split ('educba ~ hive ~ Hadoop, ' ~ '): („educba”, „hive”, „Hadoop”) | Dzieli ciąg znaków na wyrażenia pat i zwraca tablicę. |
| load (string s, int Len, string pad) | Hive> wybierz ładowanie („EDUCBA”, 6, „H”) | Zwraca łańcuchy z odpowiednią wyściółką o długości łańcucha. (znak padu). |
| Długość (ciąg str) | Hive> wybierz długość („educba”) | Ta funkcja zwraca długość łańcucha. |
| Rtrim (ciąg a) | Hive> wybierz rtrim („TEMAT”);
Wyjście: „Temat” | Zwraca wynik przez przycięcie spacji z prawego końca. |
| Concat (ciąg m, ciąg n) | Hive> select concat ('data', 'ware') Wynik: Dataware | Powoduje powstanie łańcucha poprzez połączenie dwóch łańcuchów, może to zająć dowolną liczbę danych wejściowych. |
| Rewers (ciągi) | Hive> wybierz wstecz („Mobile”) | Zwraca wynik odwróconego ciągu. |
4. Funkcja daty
Konieczne jest posiadanie formatu danych w gałęzi, aby uniknąć błędu zerowego w danych wyjściowych. Konieczna jest kompatybilność daty, aby móc korzystać z funkcji daty wprowadzonych w gałęzi.
| Unix_timestamp (data ciągu, wzór ciągu) | Hive> wybierz znacznik czasu Unix_ („2019-06-08”, „rrrr-mm-dd”); Wynik: 124576 400 zajęty czas: 0, 146 sekund | Ta funkcja zwraca datę do określonego formatu i zwraca sekundy między datą a czasem uniksowym. |
| Unix_timestamp (data ciągu) | Hive> wybierz znacznik czasu Unix_ („2019-06-08 09:20:10”, „rrrr-mm-dd”); | Zwraca datę w formacie „rrrr-MM-dd GG: mm: ss” do znacznika czasu Unix. |
| Godzina (data ciągu) | Hive> wybierz godzinę ('2019-06-08 09:20:10'); Wynik: 09 godzin | Zwraca godzinę znacznika czasu |
5. Funkcje warunkowe
| Jeśli (test boolowski, wartość T prawda, t fałsz) | Hive> wybierz JEŻELI (1 = 1, „PRAWDA”, „FAŁSZ”) jako IF_CONDITION_TEST; | Sprawdza warunek, czy wartość true zwraca 1, a false zwraca 0. |
| Nie ma wartości null (b) | Hive> Wybierz nie ma wartości null (null); | Pobiera to niepuste instrukcje. jeśli null zwraca false. |
| Koalescencja (wartość1, wartość2) | Przykład: gałąź> wybierz łączenie (Null, null, 4, null, 6). zwraca 4. | Pobiera najpierw wartości inne niż null z listy wartości. |
B) Funkcja zdefiniowana przez użytkownika (UDF)
Hive korzysta z funkcji specyficznych dla użytkownika zgodnie z wymaganiami klienta zapisanymi w programowaniu Java. Jest implementowany przez dwa interfejsy, mianowicie prosty interfejs API i złożony interfejs API. Są wywoływane z zapytania gałęzi. Trzy rodzaje UDF:
1. Zwykły UDF
Działa na stole z jednym rzędem. Jest tworzony przez utworzenie klasy java, a następnie spakowanie ich do pliku .jar. Następnym krokiem jest sprawdzenie za pomocą ścieżki klasy ula. następnie w końcu wykonując je w zapytaniu gałęzi.
2. Funkcja agregująca zdefiniowana przez użytkownika
Używają funkcji agregujących, takich jak avg / mean, implementując pięć metod init (), iterate (), częściowe (), merge (), terminate ().
3. Funkcje generowania tabeli zdefiniowanej przez użytkownika
Działa z pojedynczym wierszem w tabeli i daje wiele wierszy.
Wniosek
Podsumowując, nauczyliśmy się, jak pracować na platformie gałęzi z wbudowanymi funkcjami i funkcjami zdefiniowanymi przez użytkownika szczegółowo w tym artykule. Większość organizacji ma programistę i programistę SQL do pracy nad procesem po stronie serwera, ale gałąź apache jest potężnym narzędziem, które pomaga im korzystać ze środowiska Hadoop bez wcześniejszej wiedzy na temat programów i zmniejszania map. Hive pomaga nowym użytkownikom rozpocząć i analizować dane bez żadnych barier.
Polecane artykuły
To jest przewodnik po funkcji Hive. Tutaj omawiamy koncepcję, dwa różne typy funkcji i podfunkcji w gałęzi. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Najważniejsze funkcje łańcucha w gałęzi
- Hive Pytania podczas wywiadu
- Co to jest Oracle RMAN?
- Co to jest model wodospadu?
- Wprowadzenie do architektury gałęzi
- Hive Order By