

Co to jest algorytm MapReduce?
Algorytm MapReduce jest inspirowany głównie modelem programowania funkcjonalnego. Służy do przetwarzania i generowania dużych danych. Te zestawy danych mogą być uruchamiane jednocześnie i dystrybuowane w klastrze. Program MapReduce składa się głównie z procedury mapowania i metody redukcji w celu wykonania operacji podsumowania, takiej jak zliczanie lub uzyskiwanie niektórych wyników. System MapReduce działa na serwerach rozproszonych, które działają równolegle i zarządzają całą komunikacją między różnymi systemami. Model jest specjalną strategią strategii dzielenia, łączenia i łączenia, która pomaga w analizie danych. Mapowanie jest wykonywane przez klasę Mappera i zmniejsza zadanie wykonywane przez klasę Reducer.
Zrozumienie algorytmu MapReduce
Algorytm MapReduce działa głównie w trzech krokach:
- Funkcja mapy
- Funkcja odtwarzania losowego
- Zmniejsz funkcję
Omówmy każdą funkcję i jej obowiązki.
1. Funkcja mapy
To pierwszy krok algorytmu MapReduce. Pobiera zestawy danych i rozdziela je na mniejsze zadania podrzędne. Odbywa się to w dwóch etapach, dzielenie i mapowanie. Dzielenie pobiera wejściowy zestaw danych i dzieli zestaw danych, a mapowanie bierze te podzbiory danych i wykonuje wymagane działanie. Wynikiem tej funkcji jest para klucz-wartość.
2. Funkcja odtwarzania losowego
Jest to również znane jako funkcja łączenia i obejmuje scalanie i sortowanie. Scalanie łączy wszystkie pary klucz-wartość. Wszystkie będą miały te same klucze. Sortowanie pobiera dane wejściowe z kroku scalania i sortuje wszystkie pary klucz-wartość za pomocą kluczy. Ten krok powróci również do par klucz-wartość. Dane wyjściowe zostaną posortowane.
3. Zmniejsz funkcję
To jest ostatni krok tego algorytmu. Pobiera losowe pary klucz-wartość i zmniejsza operację.
W jaki sposób algorytmy MapReduce ułatwiają pracę?
Systemy relacyjnych baz danych mają scentralizowany serwer, który pomaga w przechowywaniu i przetwarzaniu danych. Były to zwykle systemy scentralizowane. Gdy na zdjęciu pojawia się wiele plików, przetwarzanie jest uciążliwe i tworzy wąskie gardło podczas przetwarzania wielu plików. MapReduce mapuje zestaw danych i konwertuje zestaw danych, w którym wszystkie dane są podzielone na krotki, a zadanie redukcji pobierze dane wyjściowe z tego kroku i połączy te krotki danych w mniejsze zestawy. Działa w różnych fazach i tworzy pary klucz-wartość, które można rozdzielić na różne systemy.
Co możesz zrobić z algorytmami MapReduce?
MapReduce może być używany z różnymi aplikacjami. Może być stosowany do wyszukiwania rozproszonego opartego na wzorcach, sortowania rozproszonego, odwrócenia wykresu linku, statystyk dziennika dostępu do sieci. Może również pomóc w tworzeniu i pracy nad wieloma klastrami, siatkami komputerów stacjonarnych i wolontariackimi środowiskami komputerowymi. Można również tworzyć dynamiczne środowiska chmurowe, środowiska mobilne, a także środowiska obliczeniowe o wysokiej wydajności. Google wykorzystało MapReduce, który regeneruje Indeks Google World Wide Web. Korzystając z niego, stare programy ad hoc są aktualizowane i przeprowadzają różnego rodzaju analizy. Zintegrował również wyniki wyszukiwania na żywo bez odbudowywania pełnego indeksu. Wszystkie wejścia i wyjścia są przechowywane w rozproszonym systemie plików. Dane przejściowe są przechowywane na dysku lokalnym.
Praca z algorytmem MapReduce
Aby pracować z algorytmem MapReduce, musisz znać cały proces jego działania. Zebrane dane przechodzą przez następujące kroki:
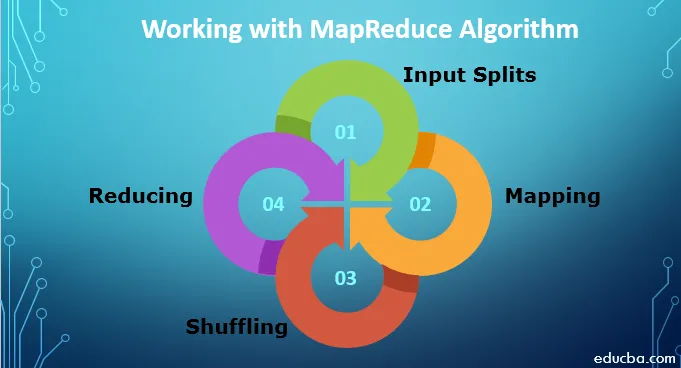
1. Podziały wejściowe: Wszelkie dane wejściowe, które przychodzą do zadania MapReduce, są dzielone na równe części zwane podziałami wejściowymi. Jest to fragment danych wejściowych, który może być wykorzystany przez dowolnego twórcę map.
2. Mapowanie: Po podzieleniu danych na części przechodzi przez fazę mapowania w programie do zmniejszania map. Te podzielone dane są przekazywane do funkcji mapowania, która generuje różne wartości wyjściowe.
3. Losowanie: Po zakończeniu mapowania dane są wysyłane do tej fazy. Jego zadaniem jest połączenie wymaganych zapisów z poprzedniej fazy.
4. Redukcja: W tej fazie dane wyjściowe z fazy tasowania są agregowane. W tej fazie wszystkie wartości są tasowane i łączone przez agregację, dzięki czemu zwraca jedną wartość wyjściową. Tworzy podsumowanie pełnego zestawu danych.
Zalety algorytmu MapReduce
Aplikacje korzystające z MapReduce mają następujące zalety:
- Zapewniono im zbieżność i dobrą wydajność uogólnienia.
- Dane można przetwarzać za pomocą aplikacji intensywnie wykorzystujących dane.
- Zapewnia wysoką skalowalność.
- Liczenie wystąpień każdego słowa jest łatwe i ma ogromną kolekcję dokumentów.
- Do wyszukiwania wielu narzędzi do analizy danych można użyć ogólnego narzędzia.
- Oferuje czas równoważenia obciążenia w dużych klastrach.
- Pomaga również w wydobywaniu kontekstów lokalizacji użytkownika, sytuacji itp.
- Może szybko uzyskać dostęp do dużych próbek respondentów.
Dlaczego warto korzystać z algorytmu MapReduce?
MapReduce to aplikacja służąca do przetwarzania ogromnych zbiorów danych. Te zestawy danych mogą być przetwarzane równolegle. MapReduce może potencjalnie tworzyć duże zestawy danych i dużą liczbę węzłów. Te duże zestawy danych są przechowywane na HDFS, co ułatwia analizę danych. Może przetwarzać wszelkiego rodzaju dane, takie jak strukturyzowane, nieustrukturyzowane lub częściowo ustrukturyzowane.
Dlaczego potrzebujemy algorytmu MapReduce?
MapReduce szybko rośnie i pomaga w obliczeniach równoległych. Pomaga w określeniu ceny produktów i pomaga osiągnąć najwyższe zyski. Pomaga również w przewidywaniu i zalecaniu analizy. Pozwala programistom uruchamiać modele na różnych zestawach danych i wykorzystuje zaawansowane techniki statystyczne i techniki uczenia maszynowego, które pomagają w przewidywaniu danych. Filtruje i wysyła dane do różnych węzłów w klastrze i działa zgodnie z funkcją mapowania i reduktora.
W jaki sposób ta technologia pomoże ci w rozwoju kariery?
Hadoop jest obecnie jednym z najbardziej poszukiwanych miejsc pracy. Przyspiesza tempo i szansę, która rośnie bardzo szybko w tej dziedzinie. W tej dziedzinie nastąpi jeszcze boom. Specjaliści IT pracujący w Javie mają plus, ponieważ są najbardziej poszukiwanymi osobami. Ponadto, programiści, architekci danych, hurtownicy danych i specjaliści BI mogą zdobyć ogromne wynagrodzenie, ucząc się tej technologii.
Wniosek
MapReduce jest podstawą frameworka Hadoop. Ucząc się tego, z pewnością wejdziesz na rynek analizy danych. Możesz się go dokładnie nauczyć i dowiedzieć się, jak przetwarzane są duże zestawy danych i jak ta technologia przynosi zmiany w przetwarzaniu i przechowywaniu danych.
Polecane artykuły
Jest to przewodnik po algorytmach MapReduce. Tutaj omawiamy koncepcję, zrozumienie, pracę, potrzebę, zalety i rozwój kariery. Możesz także przejrzeć nasze inne Sugerowane artykuły, aby dowiedzieć się więcej -
- MapReduce Pytania do wywiadu
- Co to jest MapReduce w Hadoop?
- Jak działa MapReduce?
- Co to jest MapReduce?
- Różnice między Hadoop a MapReduce
- Różne operacje związane z krotkami