

Wprowadzenie do techniki głębokiego uczenia się
Technika głębokiego uczenia oparta jest na sztucznych sieciach neuronowych, które działają jak ludzki mózg. Naśladuje sposób myślenia i działania ludzkiego mózgu. W tym modelu system uczy się i dokonuje klasyfikacji na podstawie obrazów, tekstu lub dźwięku. Modele głębokiego uczenia są szkolone na podstawie danych o dużych etykietach i danych wielowarstwowych, aby osiągnąć wysoką dokładność wyniku nawet bardziej niż na poziomie ludzkim. Samochód bez kierowcy stosuje tę technologię do identyfikacji znaku stop, pieszego itp. W ruchu. Elektroniczne gadżety, takie jak telefony komórkowe, głośniki, telewizor, komputery itp., Mają funkcję sterowania głosowego dzięki funkcji głębokiego uczenia. Ta technika jest nowa i skuteczna dla konsumentów i organizacji.
Działanie głębokiego uczenia się
Metody głębokiego uczenia wykorzystują sieci neuronowe. Są więc często nazywane głębokimi sieciami neuronowymi. Głębokie lub ukryte sieci neuronowe mają wiele ukrytych warstw głębokich sieci. Głębokie uczenie się uczy sztucznej inteligencji przewidywania wyników za pomocą określonych danych wejściowych lub ukrytych warstw sieciowych. Sieci te są szkolone przez duże zbiory danych i uczą się funkcji na podstawie samych danych. Zarówno uczenie nadzorowane, jak i nienadzorowane działa w szkoleniu danych i generowaniu funkcji.
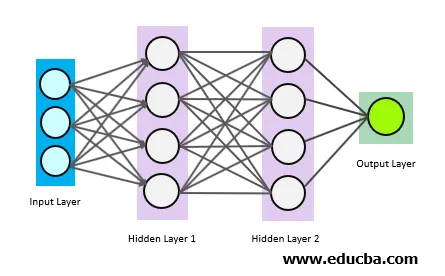
Powyższe okręgi to połączone ze sobą neurony. Istnieją 3 rodzaje neuronów:
- Warstwa wejściowa
- Ukryte warstwy
- Warstwa wyjściowa
Warstwa wejściowa pobiera dane wejściowe i przekazuje dane wejściowe do pierwszej ukrytej warstwy. Obliczenia matematyczne są wykonywane na danych wejściowych. Na koniec warstwa wyjściowa podaje wyniki.
CNN lub konwencjonalne sieci neuronowe, jedna z najpopularniejszych sieci neuronowych, łączy funkcje poznane z danych wejściowych i używa warstw splotowych 2D, aby nadawać się do przetwarzania danych 2D, takich jak obrazy. Tak więc CNN ogranicza użycie ręcznego wyciągania funkcji w tym przypadku. To bezpośrednio wyodrębnia wymagane funkcje z obrazów do klasyfikacji. Ze względu na tę funkcję automatyzacji CNN jest najbardziej dokładnym i niezawodnym algorytmem w uczeniu maszynowym. Każda CNN uczy się cech obrazów z ukrytej warstwy, a te ukryte warstwy zwiększają złożoność wyuczonych obrazów.
Ważną częścią jest szkolenie AI lub sieci neuronowych. Aby to zrobić, przekazujemy dane wejściowe z zestawu danych i na koniec porównujemy dane wyjściowe za pomocą danych wyjściowych zestawu danych. Jeśli AI nie jest przeszkolona, wyjście może być nieprawidłowe.
Aby dowiedzieć się, jak błędne jest wyjście AI z rzeczywistego wyjścia, potrzebujemy funkcji do obliczeń. Funkcja nazywa się funkcją kosztu. Jeśli funkcja kosztu wynosi zero, to zarówno wyjściowa, jak i rzeczywista wydajność AI są takie same. Aby zmniejszyć wartość funkcji kosztu, zmieniamy wagi między neuronami. Dla wygodnego podejścia można zastosować technikę o nazwie Zejście gradientu. GD zmniejsza wagę neuronów do minimum po każdej iteracji. Ten proces jest wykonywany automatycznie.
Technika głębokiego uczenia się
Algorytmy głębokiego uczenia przebiegają przez kilka warstw ukrytych warstw lub sieci neuronowych. Dlatego uczą się głęboko o obrazach w celu dokładnego przewidywania. Każda warstwa uczy się i wykrywa elementy niskiego poziomu, takie jak krawędzie, a następnie nowa warstwa łączy się z funkcjami wcześniejszej warstwy w celu lepszej reprezentacji. Na przykład warstwa środkowa może wykryć dowolną krawędź obiektu, a warstwa ukryta wykryje pełny obiekt lub obraz.
Ta technika jest skuteczna w przypadku dużych i złożonych danych. Jeśli dane są małe lub niekompletne, DL staje się niezdolny do pracy z nowymi danymi.
Istnieją następujące sieci głębokiego uczenia:
- Bezobsługowa wstępnie przeszkolona sieć : Jest to podstawowy model z 3 warstwami: warstwą wejściową, ukrytą i wyjściową. Sieć jest szkolona w zakresie rekonstrukcji danych wejściowych, a następnie ukryte warstwy uczą się na podstawie danych wejściowych w celu gromadzenia informacji, a na koniec funkcje są wydobywane z obrazu.
- Konwencjonalna sieć neuronowa : Standardowo sieć neuronowa ma wewnątrz splot do wykrywania krawędzi i dokładnego rozpoznawania obiektów.
- Recurrent Neural Network : W tej technice dane wyjściowe z poprzedniego stopnia są wykorzystywane jako dane wejściowe dla następnego lub bieżącego stopnia. RNN przechowuje informacje w węzłach kontekstu, aby poznać dane wejściowe i wygenerować dane wyjściowe. Na przykład, aby uzupełnić zdanie, potrzebujemy słów. tzn. aby przewidzieć następne słowo, wymagane są poprzednie słowa, o których należy pamiętać. RNN w zasadzie rozwiązuje ten rodzaj problemu.
- Rekurencyjne sieci neuronowe : Jest to model hierarchiczny, w którym dane wejściowe mają strukturę drzewiastą. Ten rodzaj sieci jest tworzony przez zastosowanie tego samego zestawu wag w zespole danych wejściowych.
Głębokie uczenie się ma wiele zastosowań w dziedzinie finansów, wizji komputerowej, rozpoznawania dźwięku i mowy, analizy obrazu medycznego, technik projektowania leków itp.
Jak tworzyć modele głębokiego uczenia się?
Algorytmy głębokiego uczenia są tworzone przez łączenie warstw między nimi. Pierwszym krokiem powyżej jest warstwa wejściowa, a następnie ukryte warstwy i warstwa wyjściowa. Każda warstwa składa się z połączonych neuronów. Sieć zużywa dużą ilość danych wejściowych do obsługi ich przez wiele warstw.
Aby utworzyć model głębokiego uczenia, potrzebne są następujące kroki:
- Zrozumienie problemu
- Zidentyfikuj dane
- Wybierz algorytm
- Trenuj model
- Przetestuj model
Nauka odbywa się w dwóch etapach
- Zastosuj nieliniową transformację danych wejściowych i utwórz model statystyczny jako dane wyjściowe.
- Model został ulepszony metodą pochodną.
Te dwie fazy operacji są nazywane iteracją. Sieci neuronowe powtarzają dwa kroki, aż do uzyskania pożądanej wydajności i dokładności.
1. Szkolenie sieci: Aby wyszkolić sieć danych, zbieramy dużą liczbę danych i projektujemy model, który pozna funkcje. Ale proces ten przebiega wolniej w przypadku bardzo dużej liczby danych.
2. Transfer Learning: Transfer Learning poprawia wstępnie wyszkolony model, a następnie wykonuje nowe zadanie. W tym procesie czas obliczania ulega skróceniu.
3. Wyodrębnianie cech: po wytrenowaniu wszystkich warstw na temat cech obiektu, cechy są wyodrębniane z niego, a wynik jest przewidywany z dokładnością.
Wniosek
Deep Learning to podzbiór ML, a ML to podzbiór AI. Wszystkie trzy technologie i modele mają ogromny wpływ na rzeczywiste życie. Podmioty gospodarcze, komercyjni giganci wdrażają modele głębokiego uczenia w celu uzyskania doskonałych i porównywalnych wyników dla automatyzacji inspirowanej ludzkim mózgiem.
Polecane artykuły
Jest to przewodnik po technice głębokiego uczenia się. Tutaj omawiamy, jak tworzyć modele głębokiego uczenia wraz z dwiema fazami operacji. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Co to jest głębokie uczenie się
- Kariera w głębokim nauczaniu
- 13 Przydatne pogłębione uczenie się Wywiady Pytania i odpowiedzi
- Uczenie maszynowe hiperparametrów