
Co to jest Splunk
Splunk jest określane jako produkt lub narzędzie, które służy do analizy danych w dużych ilościach w świecie biznesu. Jest to bardzo potężne i wszechstronne narzędzie wyszukiwania, które zapełnia dziennik w czasie rzeczywistym, a tym samym ułatwia monitorowanie i rozwiązywanie problemów występujących w naszej aplikacji. Założycielami Splunk są Michael Baum, Rob Das i Erik Swan. Został opracowany w 2003 roku, ale Splunk cieszy się większym zainteresowaniem po wydaniu Splunk 3.0 w latach 2008-09.
Splunk działa jak indeksowanie danych, wykorzystuje je do wyszukiwania i badania, dodawania wiedzy do danych, konfigurowania monitorów i ostrzegania, raportowania i analizowania, przygotowywania pulpitów nawigacyjnych. Splunk bezpiecznie gromadzi dane, a następnie pomaga w przechowywaniu i indeksowaniu danych w scentralizowanej lokalizacji z dostępem opartym na rolach. Dlatego nie ma znaczenia, jak nieustrukturyzowane lub zróżnicowane są nasze dane, możemy łatwo monitorować, raportować i analizować nasze dane.
Koncepcje Splunk:
Splunk dodaje wiedzę do twoich danych za pomocą obiektów wiedzy (takich jak tagi, pola i zapisane wyszukiwania, raporty, pulpity nawigacyjne, alerty itp.). Te obiekty wiedzy mogą być współużytkowane i ponownie użyte: Te pojęcia obiektów wiedzy wyjaśniono poniżej:
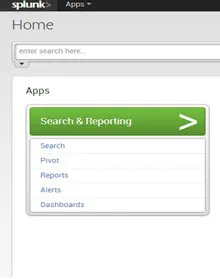
O grze Splunk Home:
Splunk Home to główne okno aplikacji i danych dostępnych z tego Splunk. Splunk Home zawiera pasek wyszukiwania i trzy panele: Aplikacje, Dane i Pomoc.
- Ten pasek wyszukiwania aplikacji jest używany przez użytkownika do uruchomienia zapytania wyszukiwania. Pasek wyszukiwania aplikacji i standardowy pasek wyszukiwania Splunk są podobne i zawierają selektor zakresu czasu.
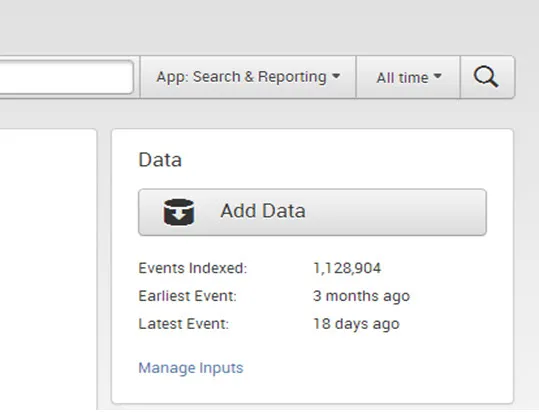
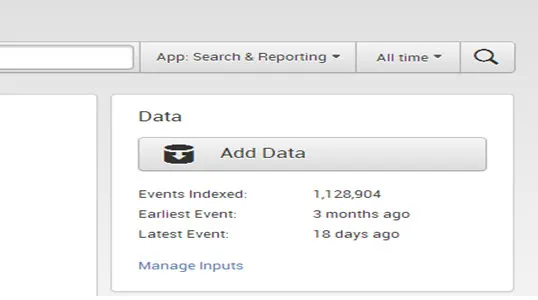
- Panel danych jest używany przez użytkownika do dodawania nowych danych i zarządzania danymi. Pokazuje, jak dawno temu dane były indeksowane najwcześniejszym i najnowszym zdarzeniem danych oraz ich objętością.
Gdy masz dane w Splunk, możesz zobaczyć krótkie podsumowanie:
- Kliknij Dodaj dane, aby wprowadzić nowe dane do Splunk.
- Kliknij Zarządzaj danymi wejściowymi, aby wyświetlić i edytować istniejące definicje danych wejściowych.
Przesyłanie danych do Splunk:
Użytkownik może przesłać inny typ danych, takich jak pliki tekstowe, pliki csv, dzienniki zdarzeń, blogi dowolne dane maszynowe do Splunk. Po przesłaniu danych Splunk natychmiast indeksuje dane i udostępnia dane do wyszukiwania. Użytkownik może przeprowadzić wyszukiwanie dowolnego typu na tych danych oraz tworzyć raporty, pulpity nawigacyjne i wykresy itp.
Krok 1. Kliknij Dodaj dane w Splunk Home.
Krok 2. Kliknij w plikach i katalogach.
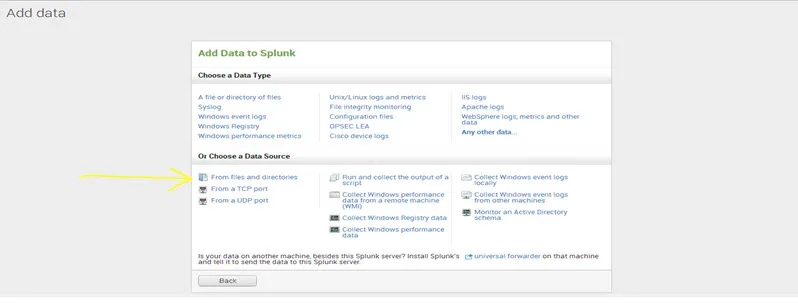
Krok 3. Istnieją dwie opcje podglądu danych przed indeksowaniem i pominięcie podglądu. Jeśli chcesz wyświetlić podgląd danych przed zaindeksowaniem, wybierz podgląd danych i przejrzyj plik, w przeciwnym razie wybierz pominięcie podglądu i naciśnij kontynuuj.
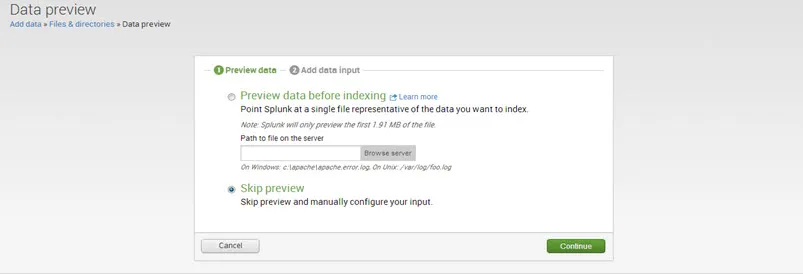
Krok 4. Wybierz opcję Prześlij i zindeksuj plik oraz wyszukaj plik danych.
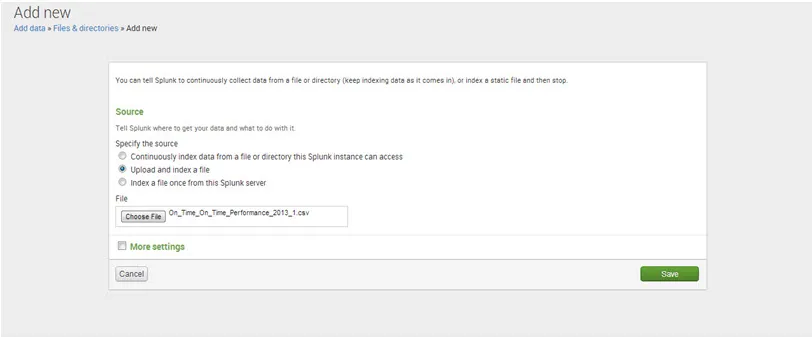
Krok 5. Więcej ustawień
- W obszarze Host ustaw wartości Set hosta na „regex on a path”, a wyrażenie regularne na „1”
- W polu Typ źródła ustaw wartość zestawu, Typ źródła to „Automatyczny”.
- W zestawie indeksów wartość ustawienia indeksu docelowego na „default”.
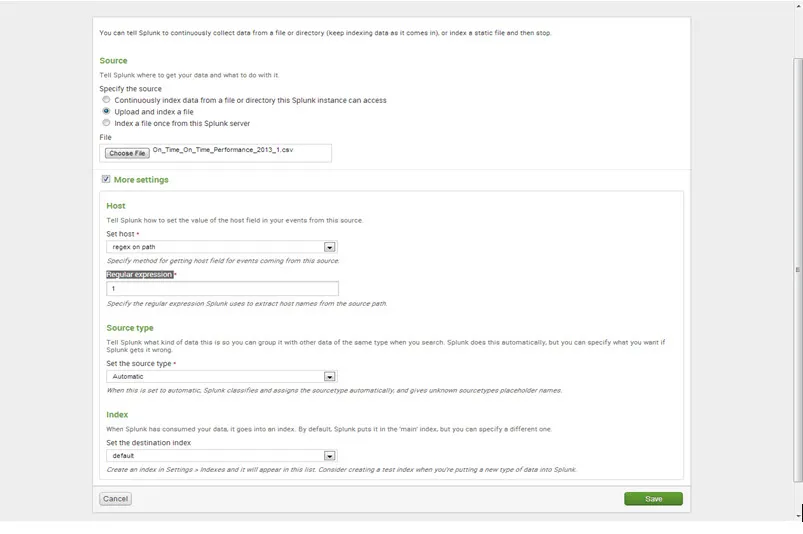
Krok 6. Kliknij przycisk Zapisz, a Splunk wyświetli dane wiadomości są indeksowane pomyślnie.
Aby rozpocząć wyszukiwanie, kliknij Rozpocznij wyszukiwanie.
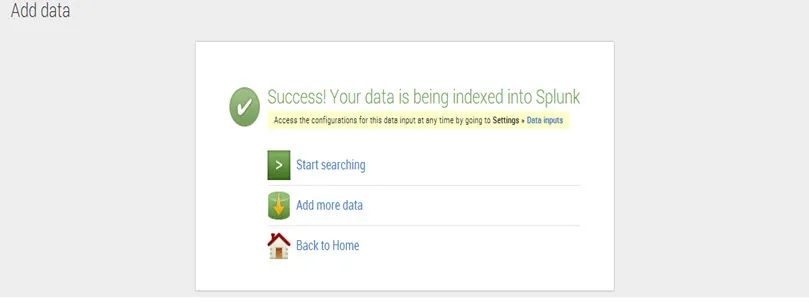
Co to jest podsumowanie danych Splunk
Aby zobaczyć więcej szczegółów na temat przesłanych danych, kliknij Podsumowanie danych.
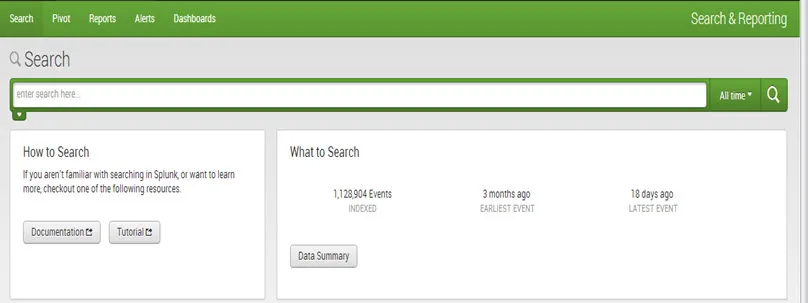
Okno dialogowe Podsumowanie danych, które wyświetla trzy zakładki: Hosty, Źródła, Typy źródeł.
Hostem zdarzenia jest zazwyczaj nazwa hosta, adres IP lub pełna nazwa domeny maszyny sieciowej.
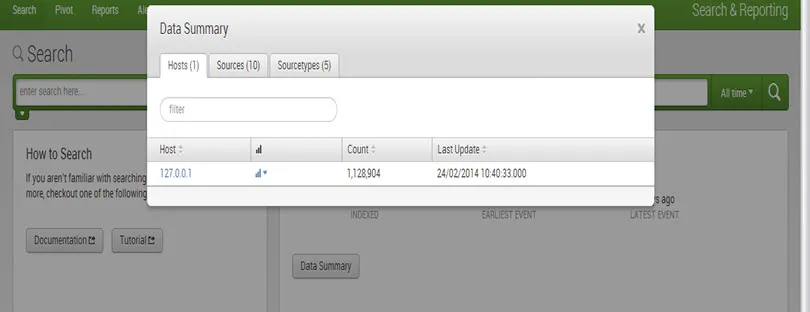
Źródłem zdarzenia jest ścieżka do pliku lub katalogu, port sieciowy lub skrypt.
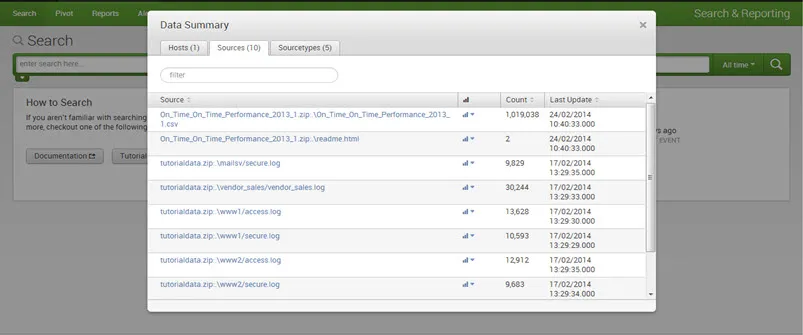
Typ zdarzenia źródłowego informuje o tym, jakie to dane, zwykle na podstawie sposobu ich sformatowania.
Szukaj / Wyszukiwanie zaawansowane:
Najczęściej używane polecenia:
Top / Rare: To polecenie zwraca górne i rzadkie wartości danego pola na pasku wyszukiwania.
Na przykład:

Wynik:
Statystyki: Polecenie stats służy do obliczeń statystycznych w zbiorze danych. Jest podobny do agregacji SQL. Istnieje więcej niż jedno polecenie do obliczeń statystycznych. Polecenia statystyki, wykresu i wykresu czasowego wykonują te same obliczenia statystyczne na danych, ale zwracają nieco inne dane wyjściowe.
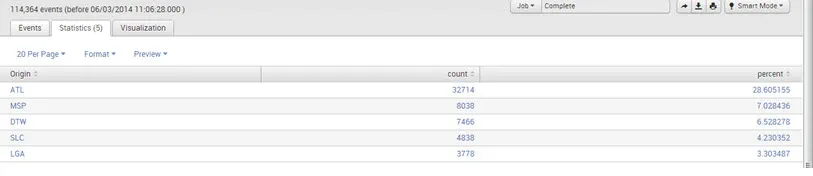
Na przykład:
- Sourcetype = ”csv” | statystyki dc (pochodzenie)

Wynik:

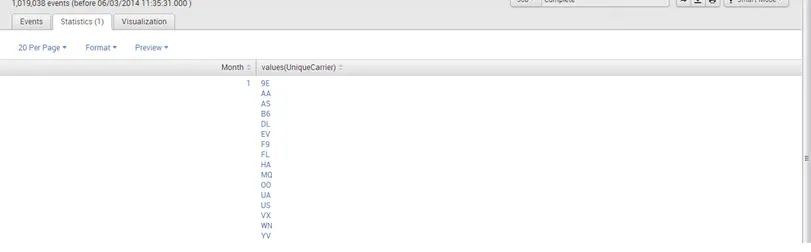
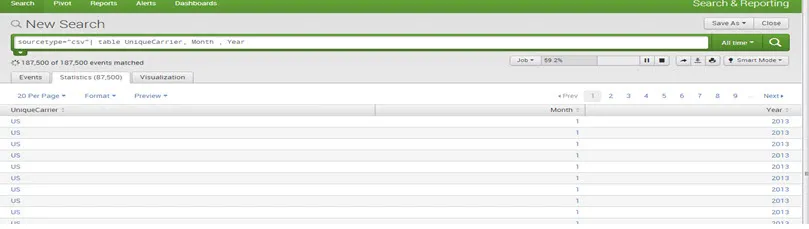
- sourcetype = ”csv” | wartości statystyk (UniqueCarrier) według miesiąca

Wynik:
Poniżej znajdują się funkcje statystyczne, których można używać z poleceniem stats.
Avg (X): Zwraca średnią wartości z pola X.
Count (X): Zwraca liczbę wystąpień pola X.
Dc (X): Zwraca liczbę różnych wartości pola X.
Max (X): Zwraca maksymalną wartość pola X.
Min (X): Zwraca minimalną wartość pola X.
Suma (X): Zwraca sumę wartości pola X.
Wartości (X): Zwraca listę wszystkich wyraźnych wartości pola X
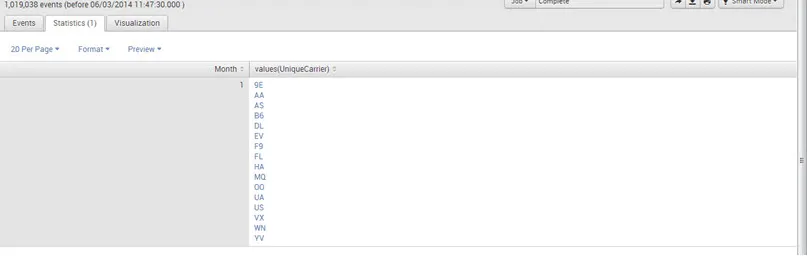
Wykres: polecenie wykresu tworzy tabelaryczne dane wyjściowe odpowiednie do tworzenia wykresów. Określasz zmienną osi x za pomocą over lub by.
Np .: sourcetype = ”csv” | wartości wykresu (UniqueCarrier) według miesiąca

Wynik:
Wykres czasowy: Polecenie timechart tworzy wykres dla zastosowanej agregacji statystycznej
do pola względem czasu jako osi x.
Np .: sourcetype = ”csv” | wartości wykresu czasowego (UniqueCarrier) według miesiąca

Wynik:
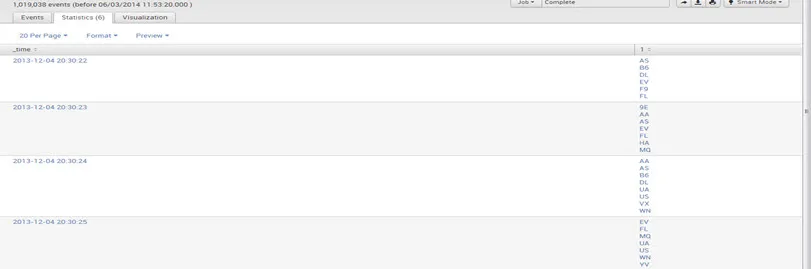
Tabela: To polecenie zwraca tabelę utworzoną z pól używanych na liście argumentów wyszukiwania
Na przykład:
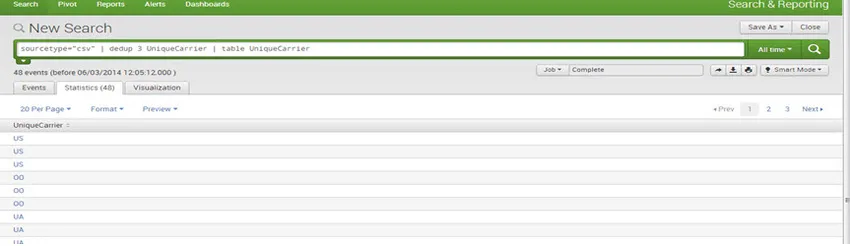
Odliczenie: usunięcie nadmiarowych danych jest punktem polecenia filtrowania deduplikacji.
Na przykład:
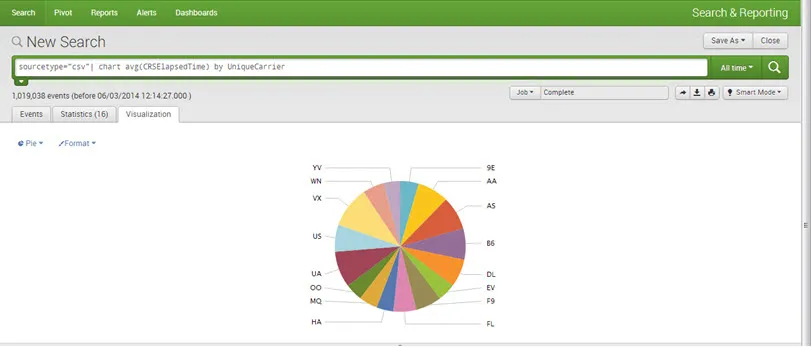
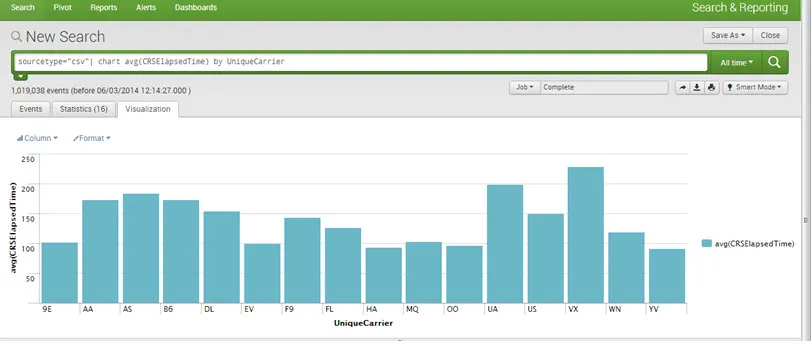
Wizualizacje:
Wykresy / raporty Możemy tworzyć raporty i wykresy dla lepszej wizualizacji i zrozumienia. Można rysować wszystkie rodzaje wykresów. Na przykład ciasto, linia, pasek i obszar itp.
Na przykład:
Pulpity nawigacyjne:
Pulpity nawigacyjne są najczęstszymi typami widoków. Każdy pulpit nawigacyjny zawiera jeden lub więcej paneli, z których każdy może zawierać wizualizacje, takie jak wykresy, tabele, listy zdarzeń i mapy. Zasadniczo pulpity nawigacyjne to zbiór wyszukiwań i raportów.
Aby utworzyć pulpit nawigacyjny, zapisz wykres / raport jako pulpit nawigacyjny.
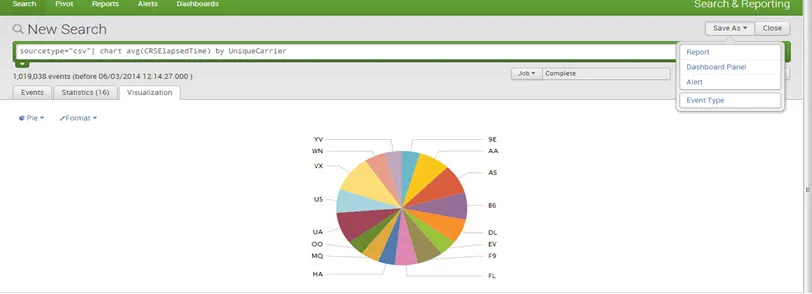 Podaj tytuł, opis i tytuł panelu i zapisz go.
Podaj tytuł, opis i tytuł panelu i zapisz go.
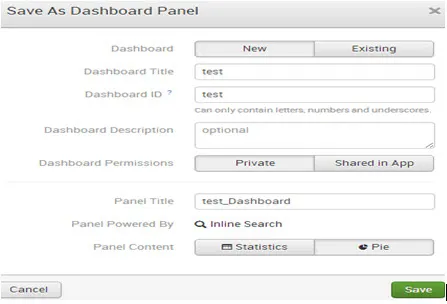
Pulpit nawigacyjny został pomyślnie utworzony. Aby rywalizować, kliknij pulpit nawigacyjny.

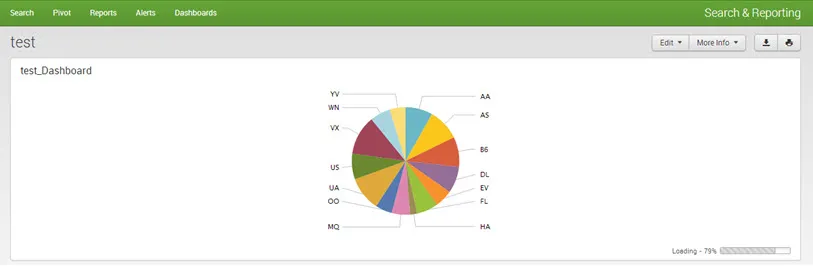
Wynik:
Wniosek - Co to jest Splunk
Splunk to platforma używana do operacji w czasie rzeczywistym. Służy do zarządzania aplikacjami, bezpieczeństwa i zarządzania wydajnością. Jest swobodnie dostępny i łatwo dostępny. Pomaga w wizualizacji danych za pomocą wykresów i wykresów. Dla początkujących może to być łatwa nauka. Jest to także jeden z głównych produktów lub narzędzi dla deweloperów DevOps i Agile.
Polecane artykuły:
To był przewodnik po Splunk. Omówiliśmy tutaj kilka podstawowych pojęć dotyczących Splunk, kroki przesyłania danych do Splunk, itp. Możesz także przeczytać następujący artykuł, aby dowiedzieć się więcej -
- Wywiad Splunk Pytania i odpowiedzi
- Różnice Splunk vs Spark
- Hadoop vs Splunk - Odkryj 7 głównych różnic