

Wprowadzenie do architektury HBase
HBase jest otwartym, rozproszonym systemem przechowywania danych o kluczowej wartości i zorientowaną na kolumny bazą danych o wysokiej wydajności zapisu i wydajności odczytu losowego o niskim opóźnieniu. Korzystając z HBase, możemy przeprowadzać analizy online w czasie rzeczywistym. Architektura HBase ma dużą czytelność losową. W HBase dane są dzielone fizycznie na tak zwane regiony. Każdy region jest hostowany przez jeden serwer regionu, a jeden lub więcej regionów odpowiada za każdy serwer regionu. Architektura HBase składa się z serwerów master-slave. Klaster HBase ma jeden węzeł główny o nazwie HMaster i kilka serwerów regionalnych o nazwie HRegion Server (HRegion Server). Istnieje wiele regionów - regionów na każdym serwerze regionalnym.
Mechanizm przechowywania HDFS

W HDFS dane są przechowywane w tabeli, jak pokazano powyżej.
Każdy rząd ma klucz.
Kolumna: jest to zbiór danych, który należy do jednej rodziny kolumn i jest zawarty w wierszu.
Rodzina kolumn: Każda rodzina kolumn składa się z jednej lub więcej kolumn.
Każda tabela zawiera kolekcję rodzin kolumn. Te kolumny nie są częścią schematu.
HBase ma Dynamiczne Kolumny. Różne komórki mogą mieć różne kolumny, ponieważ nazwy kolumn są kodowane wewnątrz komórek
Kwalifikator kolumny: nazwa kolumny jest znana jako kwalifikator kolumny.
Komponenty architektury HBase
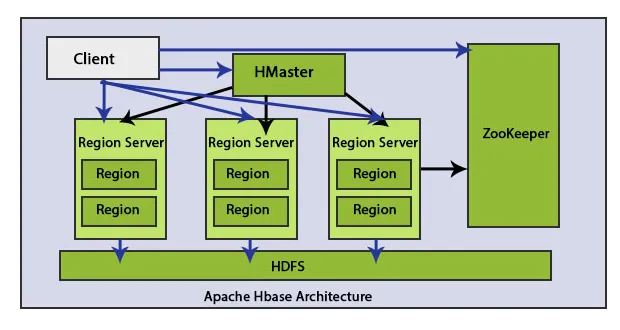
Architektura HBase składa się z głównych elementów: HMaster i Region Server. Regionalne zapisywanie danych HBase.
1. HMaster
Węzeł HMaster jest lekki i służy do przypisywania regionu do regionu serwera.
Oto niektóre główne obowiązki Hmastera:
- Wykonywanie niektórych zadań administracyjnych, w tym ładowanie, równoważenie, tworzenie danych, aktualizowanie, usuwanie itp.
Odpowiedzialny za zmiany w schemacie lub modyfikacje danych META zgodnie z kierunkiem aplikacji klienta
- HMaster obsługuje wiele prac związanych z DDL na tabelach HBase.
Niektóre metody, które udostępnia interfejs HMaster, to głównie. Metody zorientowane na dane META.
- Tabela (tworzenie, usuwanie, włączanie, wyłączanie, usuwanie tabeli)
- ColumnFamily (dodaj Column, zmodyfikuj Column)
- Region (przenieś, przypisz)
Klient komunikuje się zarówno z HMaster, jak i ZooKeeper dwukierunkowo. Kontaktuje się bezpośrednio z serwerami HRegion w celu odczytu i zapisu operacji. HMaster przypisuje regiony do serwerów w regionie i z kolei sprawdza stan serwerów regionalnych.
2. Serwer regionu
Szorstkie wyobrażenie o serwerze regionalnym możemy uzyskać na podstawie poniższego schematu.

Serwery regionalne to działające węzły, które obsługują żądania klientów dotyczące odczytu, zapisu, aktualizacji i usuwania. Serwer regionalny jest lekki, działa we wszystkich węzłach klastra Hadoop. Głównym zadaniem serwera regionu jest zapisywanie danych w obszarach i wykonywanie żądań klientów. Innym ważnym zadaniem serwera regionu HBase jest użycie metody automatycznego dzielenia w celu równoważenia obciążenia poprzez dynamiczne rozpowszechnianie tabeli HBase, gdy staje się ona zbyt duża po wstawieniu danych.
HMaster może kontaktować się z wieloma serwerami HRegion i wykonywać następujące funkcje:
- Zarządzanie i regiony hostingu
- Automatycznie dziel regiony
- Obsługa wniosków o czytanie i pisanie
- Bezpośrednia komunikacja z klientem
3. HDFS
HDFS oznacza rozproszony system plików Hadoop. Przechowuje każdy plik w kilku blokach i replikuje bloki w klastrze Hadoop, aby zachować odporność na uszkodzenia. HDFS zapewnia wysoką odporność na uszkodzenia i działa z materiałami o niskich kosztach. Dzięki zastosowaniu taniego sprzętu do dodawania węzłów do klastra oraz przetwarzania i zapisywania, klient uzyska lepsze wyniki niż istniejący sprzęt. HDFS kontaktuje się z komponentami HBase i zapisuje wiele danych w sposób rozproszony.
4. Zookeeper
Zookeeper to projekt typu open source. HMaster i HRegionServers rejestrują się w ZooKeeper.
Zapewnia różne usługi, takie jak utrzymywanie informacji o konfiguracji, nazywanie, zapewnianie synchronizacji rozproszonej itp. Synchronizacja rozproszona to proces zapewniania usług koordynacji między węzłami w celu uzyskania dostępu do uruchomionych aplikacji. Ma efemeryczne węzły, które reprezentują serwery regionalne. Serwery główne używają tych węzłów do wyszukiwania dostępnych serwerów.
Te węzły służą również do śledzenia partycji sieciowych i awarii serwera. Zookeeper to medium interakcji między serwerem regionu klienta. Jeśli klient chce komunikować się z serwerem regionu, to pośrednik jest pośrednikiem między nimi.
Jak inicjuje się wyszukiwanie w architekturze HBase
Jak wiadomo, lokalizacja stołu META jest zapisywana przez Zookeepera. Za każdym razem, gdy klient zbliża się lub pisze prośby o HBase, procedura jest następująca.
Klient dowiaduje się od ZooKeeper, jak umieścić je na stole META. Następnie klient żąda odpowiedniego klucza wiersza od tabeli META, aby uzyskać dostęp do lokalizacji serwera regionu. Dzięki położeniu tabeli META klient buforuje te informacje. Klient nie będzie odnosił się do tabeli META, dopóki obszar nie zostanie przeniesiony lub przesunięty. Następnie serwer META zostanie ponownie poproszony, a pamięć podręczna zostanie zaktualizowana. Jak zawsze klienci nie tracą czasu na znalezienie lokalizacji serwera regionalnego na serwerze META, dzięki czemu oszczędza czas i przyspiesza proces wyszukiwania.
cechy
Dzięki Hadoop łatwo jest zintegrować źródło i miejsce docelowe.
Obsługiwana jest pamięć rozproszona, taka jak HDFS.
Ma funkcję dostępu swobodnego, wykorzystując wewnętrzną tabelę mieszania do przechowywania danych w celu szybszego wyszukiwania plików HDFS.
Zalety architektury HBase
- Mogą one przechowywać duże zestawy danych
- Możemy udostępnić bazę danych
- Ekonomiczne od gigabajtów do petabajtów
- Wysoka dostępność dzięki replikacji i awariom
Wady architektury HBase
- Struktura SQL nie obsługuje
- Nie obsługuje transakcji
- Tylko z kluczem posortowanym
- Problemy z pamięcią klastra
Wniosek
HBase jest jedną z rozproszonych, zorientowanych kolumnowo baz danych NonSql w apache. W porównaniu z Hadoop lub Hive, HBase działa lepiej, jeśli chodzi o pobieranie mniejszej liczby rekordów. W tym artykule omówiliśmy architekturę HBase i jej ważne komponenty.
Polecane artykuły
To był przewodnik po architekturze HBase. Tutaj omówiliśmy koncepcję, komponenty, funkcje, zalety i wady. Możesz także przejrzeć nasze inne Sugerowane artykuły, aby dowiedzieć się więcej -
- Co to jest technologia Big Data?
- HDFS vs HBase Który z nich jest lepszy
- Co to jest język asemblera?
- Wprowadzenie do HTML