

Różnica między Apache Nifi a Apache Spark
Do długiego czasu, kiedy trzeba było wykonać ciężką pracę, ludzie polegali na koniach do ciągnięcia ciężkich ładunków, utrzymywania prędkości lub cokolwiek innego pomiędzy. Jednak nie wszystkie konie nadawały się do każdego zadania. Podobnie jest dzisiaj z technologią. Wraz z pojawieniem się nowych technologii każdego dnia niezwykle ważne staje się poznanie ich prawdziwych zastosowań. Dwie takie technologie to Apache Nifi i Apache Spark, a my zajmiemy się nimi w tym poście.
Apache Spark to framework open source do przetwarzania klastrów, którego celem jest zapewnienie interfejsu do programowania całego zestawu klastrów z domyślną odpornością na błędy i równoległością danych. Wykorzystuje RDD (Resilient Distributed Datasets) i przetwarza dane w postaci dyskretnych strumieni, które są dalej wykorzystywane do celów analitycznych.
Apache Nifi (krótka forma NiagaraFiles) to kolejny projekt oprogramowania, którego celem jest zautomatyzowanie przepływu danych między systemami oprogramowania. Projekt oparty jest na modelu programowania przepływowego, który zapewnia funkcje obejmujące obsługę klastrów. Jest to łatwy w użyciu, niezawodny i potężny system do przetwarzania i dystrybucji danych. Obsługuje skalowalne ukierunkowane wykresy dla routingu danych, mediacji systemowej i logiki transformacji. Omówmy porównania obu tematów.
Bezpośrednie porównanie Apache Nifi vs Apache Spark (infografiki)
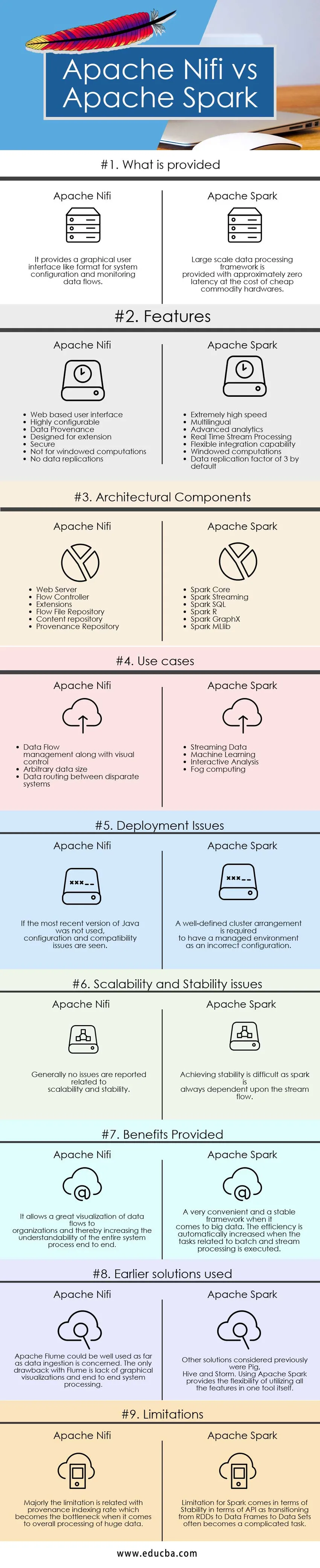
Poniżej znajduje się porównanie 9 najlepszych między Apache Nifi a Apache Spark
Kluczowe różnice między Apache Nifi a Apache Spark
Różnice między Apache Nifi i Apache Spark wyjaśniono w punktach przedstawionych poniżej:
- Apache Nifi to narzędzie do przetwarzania danych, które służy do dostarczania łatwego w użyciu, wydajnego i niezawodnego systemu, dzięki czemu przetwarzanie i dystrybucja danych między zasobami staje się łatwe, podczas gdy Apache Spark jest niezwykle szybką technologią przetwarzania w klastrze, która została zaprojektowana w celu szybszego obliczenia przez efektywnie wykorzystując interaktywne zapytania, w zarządzaniu pamięcią i możliwościach przetwarzania strumieniowego.
- Apache Nifi działa w trybie autonomicznym i trybie klastrowym, podczas gdy Apache Spark działa dobrze w trybie lokalnym lub autonomicznym, Mesos, Yarn i innych rodzajach trybów klastra dużych zbiorów danych.
- Funkcje Apache Nifi obejmują gwarantowane dostarczanie danych, wydajne buforowanie danych, kolejkowanie priorytetowe, QoS specyficzne dla przepływu, dostarczanie danych, odzyskiwanie bufora rolki, wizualne polecenia i sterowanie, szablony przepływu, zabezpieczenia, równoległe przesyłanie strumieniowe, podczas gdy funkcje iskry apache obejmują błyskawiczne szybkie możliwość szybkiego przetwarzania, wielojęzyczność, przetwarzanie w pamięci, efektywne wykorzystanie systemów sprzętowych towarów, zaawansowana analityka, wydajna integracja.
- Apache Nifi umożliwia lepszą czytelność i ogólne zrozumienie systemu, zapewniając możliwości wizualizacji oraz funkcje przeciągania i upuszczania. Przepływem danych można łatwo zarządzać i zarządzać przy użyciu konwencjonalnych technik i procesów, natomiast w przypadku Apache Spark do wyświetlania tego rodzaju wizualizacji potrzebny jest system zarządzania klastrami, taki jak Ambari. Apache Spark sam w sobie nie zapewnia możliwości wizualizacji i jest dobry tylko w zakresie programowania. Jest to zdecydowanie bardzo wygodny i stabilny system do przetwarzania ogromnych ilości danych.
- Ograniczenie związane z Apache Nifi wiąże się z jego zaletą. Jedyną funkcją przeciągnij i upuść jest ograniczenie niemożności skalowania i zapewnienia niezawodności, jeśli chodzi o integrację z innymi komponentami i narzędziami, podczas gdy w przypadku Apache Spark podstawowe ograniczenie wiąże się z użyciem szerokiego sprzętu towarowego i zarządzaniem nimi staje się czasem nudnym zadaniem. Inne zgłaszane ograniczenie wiąże się z jego funkcjami przesyłania strumieniowego związanymi ze strumieniem dyskretnym i strumieniem okienkowym lub wsadowym, w którym przekształcenie RDD w ramkę danych i zestawy danych stanowi czasami przyczynę niestabilności.
Tabela porównawcza Apache Nifi vs Apache Spark
| Podstawa porównania | Apache Nifi | Apache Spark |
| Co jest dostarczone | Zapewnia graficzny interfejs użytkownika, taki jak format konfiguracji systemu i monitorowania przepływów danych. | Ramy przetwarzania danych na dużą skalę zapewniają około zerowe opóźnienie kosztem taniego sprzętu. |
| cechy |
|
|
| Elementy architektoniczne |
|
|
| Przypadków użycia |
|
|
| Problemy z wdrażaniem | Jeśli nie była używana najnowsza wersja Java, widoczne są problemy z konfiguracją i zgodnością | Dobrze zdefiniowane ustawienie klastra jest wymagane, aby środowisko zarządzane było niepoprawne |
| Problemy ze skalowalnością i stabilnością | Zasadniczo nie zgłaszano problemów związanych ze skalowalnością i stabilnością | Osiągnięcie stabilności jest trudne, ponieważ iskra zawsze zależy od przepływu strumienia. |
| Świadczenia zapewnione | Umożliwia doskonałą wizualizację przepływów danych do organizacji, a tym samym zwiększa zrozumiałość całego procesu systemowego od końca do końca | Bardzo wygodny i stabilny framework, jeśli chodzi o duże zbiory danych. Wydajność jest automatycznie zwiększana, gdy wykonywane są zadania związane z przetwarzaniem wsadowym i strumieniowym. |
| Wcześniej zastosowane rozwiązania | Apache Flume może być dobrze wykorzystany w zakresie pobierania danych. Jedyną wadą Flume'a jest brak wizualizacji graficznych i kompleksowe przetwarzanie systemu | Inne rozważane wcześniej rozwiązania to Pig, Hive i Storm. Korzystanie z Apache Spark zapewnia elastyczność korzystania ze wszystkich funkcji w jednym narzędziu. |
| Ograniczenia | Ograniczenie to dotyczy przede wszystkim wskaźnika indeksowania pochodzenia, który staje się wąskim gardłem, jeśli chodzi o ogólne przetwarzanie ogromnych danych | Ograniczeniem dla Spark jest stabilność w zakresie API, ponieważ przechodzenie z RDD do ramek danych do zestawów danych często staje się skomplikowanym zadaniem. |
Wniosek - Apache Nifi vs. Apache Spark
Na zakończenie postu można powiedzieć, że Apache Spark to ciężki koń bojowy, podczas gdy Apache Nifi to zwinny koń wyścigowy. Oba mają swoje zalety i ograniczenia, które można stosować w odpowiednich obszarach. Musisz wybrać odpowiednie narzędzie dla swojej firmy. Bądź na bieżąco z naszym blogiem, aby uzyskać więcej artykułów związanych z nowszymi technologiami dużych zbiorów danych.
Polecany artykuł
Jest to przewodnik po Apache Nifi vs Apache Spark, ich znaczeniu, porównaniu między głowami, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Apache Hadoop vs Apache Spark | 10 najlepszych porównań, które musisz znać!
- Apache Storm vs Apache Spark - poznaj 15 przydatnych różnic
- 7 ważnych rzeczy na temat Apache Spark (przewodnik)
- 15 najlepszych rzeczy, które musisz wiedzieć o MapReduce vs. Spark