

Wprowadzenie do mieszania w DBMS
Kiedy mówimy o ogromnej strukturze bazy danych i ich złożoności, wyszukiwanie wszystkich indeksów staje się bardzo nieefektywne, a dotarcie do pożądanych danych staje się bardzo niejasne i złożona możliwość. Korzystając z techniki mieszania, można osiągnąć te stany i można przypisać bezpośredni wskaźnik, aby znać dokładną i bezpośrednią lokalizację na dysku dla konkretnego rekordu, bez korzystania ze złożonej struktury indeksu. Dane w przypadku techniki mieszania są przechowywane w postaci bloków danych, których adres jest generowany przez wykorzystanie funkcji znanej zwykle jako funkcja mieszająca. Lokalizacja w pamięci, w której się ona znajduje i gdzie przechowywane są rekordy, jest znana jako bloki danych lub segment danych.
Typy mieszania w DBMS
W DBMS są zazwyczaj dwa rodzaje technik haszujących:
1. Hashowanie statyczne
2. Dynamiczne mieszanie
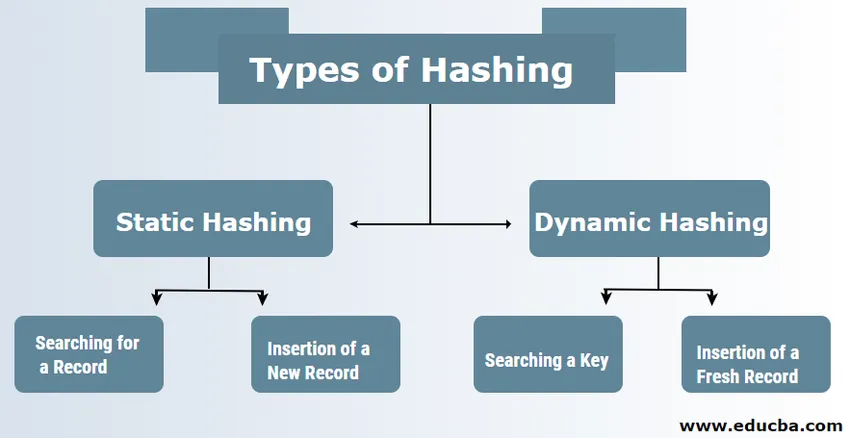
1) Hashowanie statyczne
W przypadku mieszania statycznego utworzony zestaw danych i adres segmentu są takie same. Oznacza to, że jeśli spróbujemy wygenerować adres dla ID_UŻYTKOWNIKA = 113, korzystając z modułu funkcji skrótu 5, to zawsze daje nam wypadkową jako 3 z tym samym wyglądającym adresem segmentu. W takim przypadku adres podanego wiadra nie ulegnie zmianie. Dlatego liczba łyżek pozostaje stała podczas całej operacji.
Działanie mieszania statycznego
za. Wyszukiwanie rekordu: Jeśli istnieje potrzeba znalezienia rekordu, wówczas do wyszukiwania adresu i ścieżki segmentu danych z przechowywanymi danymi używana jest ta sama funkcja mieszająca.
b. Wstawienie nowego rekordu: Jeżeli nowy i nowy rekord zostanie umieszczony w tabeli, wówczas generowany jest adres dla nowego rekordu na podstawie klucza mieszającego, który przechowuje rekord w tej lokalizacji.
- Usuwanie rekordu: Aby usunąć rekord, najpierw należy pobrać rekord, który można usunąć. Po wykonaniu tego zadania rekordy należy usunąć dla tego adresu pamięci.
- Aktualizacja rekordu: Aby zaktualizować rekord, najpierw przeszukujemy go, korzystając z funkcji opartej na haszowaniu, a gdy to nastąpi, można powiedzieć, że nasz rekord danych jest w zaktualizowanym stanie. Aby wstawić nowy rekord do pliku, a adres wygenerowany z funkcji opartej na haszowaniu i zasobniku danych jest niepusty lub jeśli dane są już obecne pod podanym adresem. Tę sytuację, która powstaje szczególnie w przypadku mieszania statycznego, można lepiej nazwać przepełnieniem łyżki, dlatego istnieją pewne sposoby rozwiązania tego problemu, takie jak:
(i) Open Hashing: Jeśli funkcja haszująca generuje adres, dla którego dane można zobaczyć już w stanie zapisanym, w takim przypadku automatycznie zostanie przydzielony następny poziom segmentu. Ten mechanizm można nazwać techniką sondowania liniowego.
Na przykład, jeśli R3 jest nowym adresem, który należy podać, funkcja oparta na haszowaniu wygeneruje adres jako liczbę 102 dla adresu R3. Wygenerowany adres jest w pełnym stanie, a zatem system ma szukać nowego segmentu danych, który ma wartość 113, i przypisać R3 do tego segmentu danych.
(ii) Zamknięte mieszanie: Kiedy wiadra są całkowicie pełne, nowy koszyk jest następnie przydzielany dla konkretnego wyniku mieszania, który jest łączony zaraz po tym, który został wcześniej zakończony, i dlatego metoda ta nazywana jest techniką łączenia łańcuchów przepełnienia.
Na przykład R3 jest nowym adresem, który należy umieścić w nowej tabeli, do wygenerowania adresu używana jest funkcja skrótu 110. Ten segment z kolei jest pełny i dlatego nie może odbierać nowych danych, dlatego nowy segment jest umieszczany na końcu po 100.
2) Dynamiczne mieszanie
Tego rodzaju metoda oparta na haszowaniu może być stosowana do rozwiązywania podstawowych problemów związanych z haszowaniem opartym na ładunkach statycznych, takich jak przepełnienie segmentu, ponieważ segmenty danych mogą się powiększać i zmniejszać wraz z rozmiarem, ponieważ jest to technika bardziej zoptymalizowana pod względem miejsca, dlatego jest nazywana rozszerzalną metoda oparta na haszowaniu. W tej metodzie haszowanie jest dynamiczne, co oznacza, że czynność wstawiania lub usuwania jest dozwolona bez pogarszania wydajności.
za. Wyszukiwanie klucza: Oblicz adres mieszany wymaganego klucza i sprawdź liczbę bitów używanych w przypadku katalogu znanego jako i. Następnie te, które są najmniej znaczące z bitów I, są pobierane z katalogu, który daje wyobrażenie o indeksie z katalogu. Korzystając z tej wartości indeksu, przejdź do katalogu, aby znaleźć adres segmentu, aby wyszukać obecne rekordy.
b. Wstawienie nowego rekordu: Najpierw musisz wykonać dokładnie tę samą procedurę pobierania, która musi znaleźć się gdzieś w wiadrze. Wyszukaj miejsce w tym wiadrze, a następnie umieść w nim rekordy. Jeśli utworzony segment jest kompletny i pełny, segment zostanie podzielony, a rekordy zostaną ponownie rozpowszechnione.
Na przykład dwa ostatnie bity cyfr 2 i 4 to 00. Więc pójdą do segmentu B0 i tak dalej, zgodnie z funkcją modułu. Klucz 9 ma adres 10001, który musi być obecny w pierwszym segmencie, ale zostanie podzielony i przejdzie do nowego segmentu B1 i będzie to trwało, dopóki wszystkie segmenty i klucze nie zostaną dynamicznie zakodowane. Funkcja skrótu jest używana w taki sposób, że funkcja skrótu służy do wyboru kolumny i jej wartości do wygenerowania adresu. Maksymalna liczba razy funkcja hash korzysta z klucza podstawowego, który z kolei służy do generowania adresów bloku danych. Jest to prosta funkcja matematyczna, w której klucz podstawowy można również traktować jako adres bloku danych, co oznacza, że każdy wiersz o tym samym adresie co adres klucza podstawowego zostanie zapisany w bloku danych.
Polecane artykuły
Jest to przewodnik po haszowaniu w DBMS. Tutaj omawiamy wprowadzenie i różne typy haszowania w DBMS, które obejmują haszowanie statyczne i haszowanie dynamiczne wraz z przykładami. Możesz także zapoznać się z następującymi artykułami, aby dowiedzieć się więcej -
- Modele danych w DBMS
- Zalety DBMS
- Narzędzie do integracji danych
- Co to jest RDBMS?