
Wprowadzenie do Hive Group Autor
Grupuj według, jak sama nazwa wskazuje, zgrupuje rekord, który spełnia określone kryteria. W tym artykule przyjrzymy się grupie według HIVE. W starszych RDBMS, takich jak MySQL, SQL itp., Grupowanie według jest jedną z najstarszych używanych klauzul. Teraz znalazł swoje miejsce w podobny sposób w przechowywaniu danych w oparciu o pliki, znanym jako HIVE.
Wiemy, że Hive przekroczył wiele starszych RDBMS w zakresie obsługi ogromnych danych, nie wydając ani grosza na sprzedawców w celu utrzymania baz danych i serwerów. Musimy tylko skonfigurować HDFS do obsługi gałęzi. Ogólnie rzecz biorąc, przechodzimy do tabel, ponieważ użytkownik końcowy może interpretować na podstawie jego struktury i może wyszukiwać, ponieważ pliki będą dla nich niezdarne. Musieliśmy to jednak zrobić, płacąc dostawcom za dostarczenie serwerów i utrzymanie danych w formacie tabel. Więc Hive zapewnia ekonomiczny mechanizm, w którym wykorzystuje zalety systemów opartych na plikach (sposób, w jaki ul zapisuje swoje dane), a także tabel (struktura tabeli, z której użytkownicy końcowi mogą się wypytywać).
Grupuj według
Grupuj według używa zdefiniowanych kolumn z tabeli Hive do grupowania danych. Załóżmy, że masz tabelę z danymi spisu z każdego miasta ze wszystkich stanów, w których nazwa miasta i nazwa stanu jest jedną z kolumn. Teraz w zapytaniu, jeśli pogrupujemy według stanów, wówczas wszystkie dane z różnych miast danego stanu zostaną zgrupowane razem i można łatwo zobrazować dane lepiej teraz przed zastosowaniem grupy.
Składnia Hive Group Według
Ogólna składnia grupy według klauzul jest następująca:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
lub w przypadku prostszych zapytań,
from Group By
Select department, count(*) from the university.college Group By department;
Tutaj dział odnosi się do jednej z kolumn tabeli kolegium, która jest obecna w bazie danych uniwersytetu, a jego wartość jest różna w takich działach, jak sztuka, matematyka, inżynieria itp. Teraz zobaczmy przykład pokazujący grupę.
Utworzyłem przykładową tabelę deck_of_cards, aby zademonstrować grupę. Jego instrukcja tworzenia tabeli wygląda następująco:
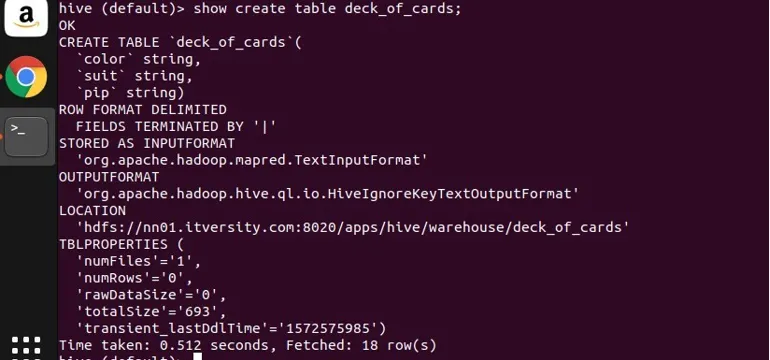
widać z góry, że ma trzy kolumny kolorów, kolor i pip. Pozwól mi napisać zapytanie, aby pogrupować dane według koloru i uzyskać ich liczbę.
select color, count(*) from deck_of_cards group by color;
Hive w zasadzie bierze powyższe zapytanie, aby przekonwertować je do programu zmniejszającego mapę, generując odpowiedni kod Java i plik jar, a następnie wykonuje. Ten proces może zająć trochę czasu, ale zdecydowanie może obsłużyć duże zbiory danych w porównaniu do tradycyjnego RDBMS. Zobacz poniższy zrzut ekranu ze szczegółowym dziennikiem wykonania powyższego zapytania.
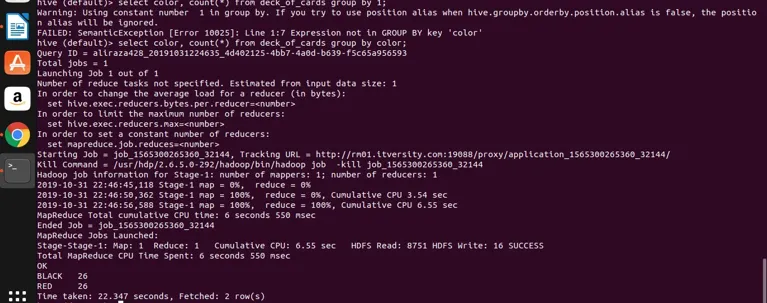
widać, że CZARNY ma 26, a CZERWONY ma 26.
zastosujmy teraz grupowanie w dwóch kolumnach (kolor i kolor oraz uzyskiwanie liczby grup) i zobaczmy wynik poniżej.
Select color, suit, count(*) from deck_of_cards group by color, suit
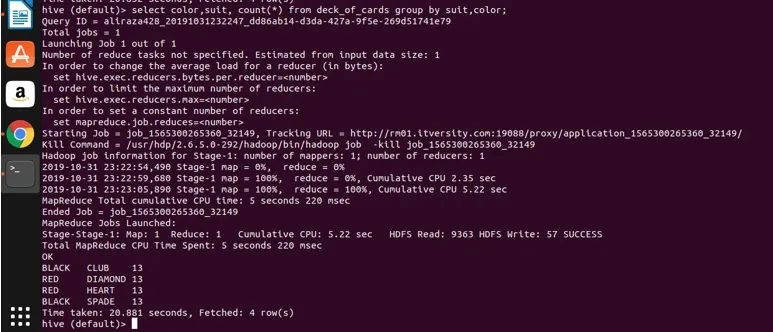
Zasadniczo istnieją cztery odrębne grupy powyżej klubu, pik, które mają kolor czarny i diament, a serce w kolorze czerwonym.
Przechowywanie wyniku z grupy według przyczyny w innej tabeli
Hive, podobnie jak każdy inny RDBMS, udostępnia funkcję wstawiania danych za pomocą instrukcji tworzenia tabeli. Spójrzmy na zapisywanie wyniku z wybranego wyrażenia używającego grupy by w innej tabeli. Pozwól mi użyć powyższego zapytania, w którym użyłem dwóch kolumn w grupie według.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
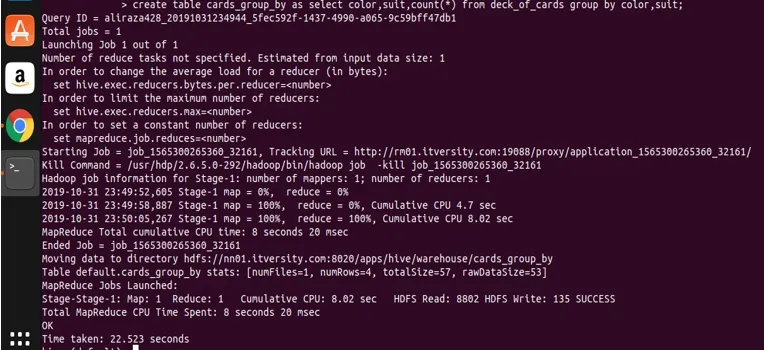
teraz zapytajmy utworzoną tabelę, aby zobaczyć i sprawdzić dane.

Ograniczmy teraz wynik grupy za pomocą klauzuli have. Jak pokazano w składni ogólnej, możemy zastosować ograniczenia w grupie, używając opcji have. Korzystam z tabeli ordser_items, a jej struktura jest następująca z instrukcji opis.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
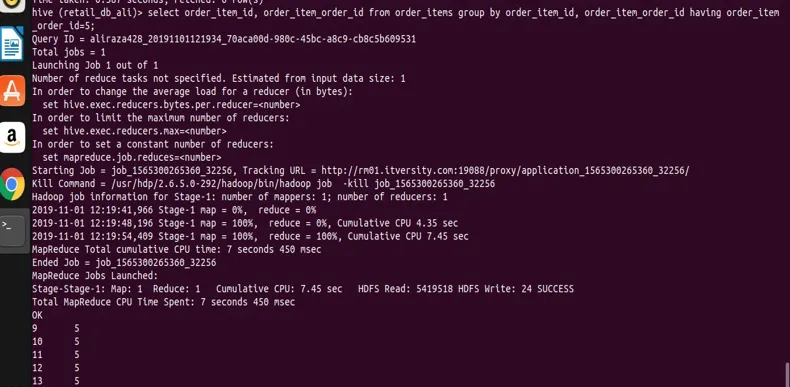
z wyniku widać zrzut ekranu, że mamy rekordy tylko o wartości order_item_order_id 5.
Grupuj według oświadczenia o sprawie
Teraz spójrzmy na nieco złożone zapytania dotyczące instrukcji CASE z grupą według. Zastosujemy to do tabeli order_items. Zobaczymy poniżej, że możemy podzielić na kategorie kolumny, w których nie możemy bezpośrednio zastosować grupy według klauzuli.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
wykonajmy to w gałęzi dla uzyskania wyników
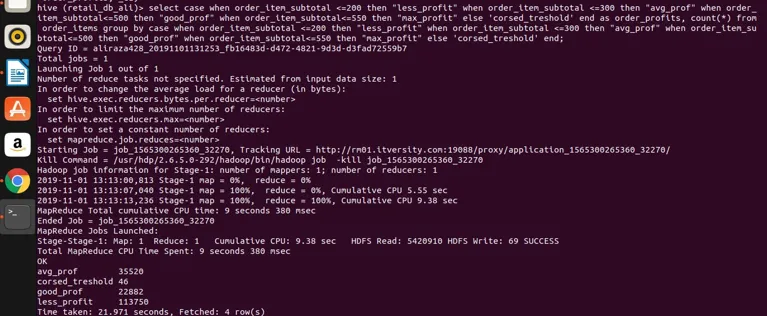
Wniosek - Hive Group Autor
więc możemy zobaczyć, że pogrupowaliśmy sumę_pozycji_zamówienia w cztery różne kategorie (jeśli zauważysz, że suma_pozycji_zamówienia jest kolumną nie agregującą i nie można na niej zastosować bezpośredniej grupy), zgrupowaliśmy je razem i otrzymaliśmy ich liczby wartości spełniające zakres zdefiniowany w wyrażeniu select. Tutaj prosta reguła, jeśli kolumna nie agreguje, a nasze wyrażenie select jest złożone, to cokolwiek w wyrażeniu select, które powinno być również obecne w grupie wyrażeniem klauzulowym. Widzieliśmy więc, jak słynną grupę klauzul RDBMS można również zastosować w gałęzi bez żadnych ograniczeń. Można go zastosować do prostych wyrażeń wyboru. Agreguj i filtruj wyrażenia, łącz wyrażenia i złożone wyrażenia CASE.
Polecane artykuły
To jest przewodnik po Hive Group By. Tutaj omawiamy grupę według składni, przykładów grupy gałęzi według z różnymi warunkami i implementacją. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Dołącza do ula
- Co to jest ul?
- Architektura ula
- Funkcja gałęzi
- Hive Order By
- Instalacja ula
- Top 6 rodzajów połączeń w MySQL z przykładami