

Różnica między Apache Hive a Apache HBase -
Historia Apache Hive rozpoczyna się w 2007 roku, kiedy programista inny niż Java musi się zmagać podczas korzystania z Hadoop MapReduce. Badacze i deweloperzy przewidzieli, że jutro będzie era Big Data. Gromadziły się już różne formaty danych, takie jak strukturyzowane, półstrukturalne i nieustrukturyzowane. Nawet Facebook borykał się z większą ilością przetwarzania danych. Naukowcy z Facebooka wprowadzili Apache Hive do przetwarzania danych w klastrze Hadoop. Facebook był pierwszą firmą, która wymyśliła Apache Hive.
Historia Apache HBase zaczyna się w 2006 roku, kiedy startup Powerset z San Francisco próbował zbudować wyszukiwarkę języka naturalnego w Internecie. HBase to implementacja Bigtable firmy Google. Czy kiedykolwiek zdaliśmy sobie sprawę, dlaczego istnieje potrzeba opracowania kolejnej architektury pamięci? System zarządzania relacyjnymi bazami danych istnieje już od wczesnych lat siedemdziesiątych. Istnieje wiele przypadków użycia, dla których relacyjne bazy danych mają sens, ale w przypadku niektórych konkretnych problemów model relacyjny nie pasuje zbyt dobrze.
Pozwól, że wyjaśnię bardziej szczegółowo Apache Hive i Apache HBase.
Różnice między Apache Hive i Apache HBase
Apache Hive to projekt Apache typu open source zbudowany na platformie Hadoop do wyszukiwania, podsumowywania i analizowania dużych zestawów danych przy użyciu interfejsu podobnego do SQL. Apache Hive zapewnia język podobny do SQL o nazwie HiveQL, który w przejrzysty sposób konwertuje zapytania do MapReduce w celu wykonania na dużych zestawach danych przechowywanych w Hadoop Distributed File System (HDFS). Apache Hive to komponent klastra Hadoop, który jest zwykle wdrażany przez analityków danych. Rój Apache służy do przetwarzania wsadowego dużych zadań ETL. Apache Hive obsługuje również wsadowe zapytania SQL na bardzo dużych zestawach danych. Apache Hive zwiększa elastyczność projektowania schematu, a także serializację danych i deserializację. Apache Hive nie obsługuje przetwarzania transakcji online (OLTP), ponieważ gałąź nie obsługuje zapytań w czasie rzeczywistym i aktualizacjach na poziomie wiersza.
Apache HBase to otwarta baza danych NoSQL, która zapewnia dostęp w czasie rzeczywistym do odczytu i zapisu do dużych zestawów danych. NoSQL to nierelacyjna baza danych. Apache HBase jest rozproszoną, zorientowaną na kolumny bazą danych, która działa na rozproszonym systemie plików Hadoop (HDFS). Tak więc HBase zapewnia Hadoop zalety NoSQL. Apache HBase zapewnia możliwość losowego dostępu do danych obecnych w HDFS. Wykorzystuje on tolerancję błędów zapewnianą przez HDFS. Użytkownik może przechowywać dane w HDFS bezpośrednio lub przez HBase.
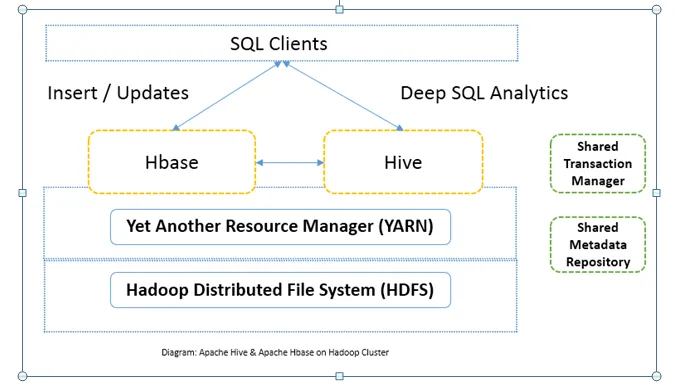
Bezpośrednie porównanie między Apache Hive a Apache HBase (infografiki)
Poniżej znajduje się 12 najważniejszych różnic między Apache Hive i Apache HBase

Kluczowe różnice - Apache Hive vs. Apache HBase
Poniżej znajdują się listy punktów, opisz kluczowe różnice między Apache Hive i Apache HBase:
- Apache HBase to baza danych, podczas gdy Apache Hive to silnik bazy danych.
- Apache Hive jest używany głównie do przetwarzania wsadowego (OLAP), podczas gdy Apache HBase jest głównie wykorzystywany do przetwarzania transakcyjnego (OLTP).
- Apache Hive wykonuje większość zapytań SQL, podczas gdy Apache HBase nie zezwala bezpośrednio na zapytania SQL.
- Apache Hive nie obsługuje operacji na poziomie rekordów, takich jak aktualizacja, wstawianie i usuwanie, podczas gdy Apache HBase obsługuje operacje na poziomie rekordów, takie jak aktualizacja, wstawianie i usuwanie.
- Apache Hive działa na MapReduce, podczas gdy Apache HBase działa na Hadoop Distributed File System (HDFS).
Apache Hive sprawdza pliki, definiując wirtualną tabelę i uruchamiając na niej zapytania HQL. Jest to proces, w którym pliki są praktycznie połączone ze strukturą przypominającą tabelę, a użytkownik może uruchomić Hive Query Language (HQL), a zapytania te są konwertowane na MapReduce Job przez Hive. Użytkownik nie musi pisać zadania MapReduce, zapytania HQL są wewnętrznie konwertowane na pliki jar i te pliki jar zostaną zaimplementowane w zestawach danych.
W Apache HBase tabele są podzielone na regiony i są obsługiwane przez serwery regionu. Dalsze regiony są pionowo dzielone według rodzin kolumn na sklepy, a sklepy są zapisywane jako pliki w HDFS.
Kiedy używać gałęzi Apache:
- Wymagania dotyczące hurtowni danych
- Zapytania analityczne
- Analiza danych, którzy znają SQL
Kiedy stosować Apache HBase:
- Szybkie i interaktywne przetwarzanie danych
- Zapytania w czasie rzeczywistym
- Szybkie wyszukiwanie
- Przetwarzanie po stronie serwera
- Losowy dostęp do odczytu / zapisu do Big Data
- Skalowalność aplikacji
Apache Hive może służyć do obliczania trendów i dzienników witryny e-commerce dla określonego czasu trwania, regionu lub strefy czasowej. Może być wykorzystywany do przetwarzania zapytań wsadowych w oparciu o dane historyczne, natomiast Apache HBase może być wykorzystywany przez Facebooka lub LinkedIn do przesyłania wiadomości i analiz w czasie rzeczywistym. Może być również używany do liczenia polubień.
Tabela porównawcza Apache Hive vs. Apache HBase
Omawiam główne artefakty i rozróżniam Apache Hive od Apache HBase.
| Apache Hive | Apache HBase | |
| Przetwarzanie danych | Apache Hive jest używany do
przetwarzanie wsadowe, tj. Online Analytical Processing (OLAP) | Apache HBase służy do przetwarzania transakcyjnego, tj. Online Transactional Processing (OLTP) |
| Szybkość przetwarzania | Apache Hive ma większe opóźnienia z powodu wykonywania zadania MapReduce w tle | Apache HBase działa na zapytania w czasie rzeczywistym i znacznie szybciej niż Apache Hive |
| Kompatybilność z Hadoop | Apache Hive działa na MapReduce | Apache HBase działa na HDFS |
| Definicja | Apache Hive jest open source i podobny do SQL używanego do zapytań analitycznych | Apache HBase jest bazą danych NoSQL typu open source używaną do tworzenia zapytań w czasie rzeczywistym |
| Udostępnione metadane | Dane utworzone w Apache Hive są automatycznie widoczne dla Apache HBase | Dane utworzone w Apache HBase są automatycznie widoczne w Apache Hive |
| Schemat | Rój Apache obsługuje schemat wstawiania danych do tabel | Apache HBase to baza danych wolna od schematów. |
| Zaktualizuj funkcję | Funkcja aktualizacji jest skomplikowana w Apache Hive | Użytkownik może bardzo łatwo zaktualizować dane w Apache HBase |
| Operacje | Operacje w Apache Hive nie działają w czasie rzeczywistym | Operacje w Apache HBase działają w czasie rzeczywistym |
| Typy danych | Apache Hive jest przeznaczony do danych strukturalnych i częściowo ustrukturyzowanych | Apache HBase jest przeznaczony do danych nieustrukturyzowanych. |
| Poziom spójności | Rój Apache obsługuje ostateczną spójność | Apache HBase obsługuje natychmiastową spójność |
| Metody podziału | Apache Hive obsługuje funkcje Sharding | Apache HBase obsługuje również funkcje Sharding |
| Przechowywanie danych | Data jest przechowywana w Hive Metastore, Partitions and Buckets w Apache Hive | Dane są przechowywane w kolumnach i wierszach tabel w Apache HBase |
Wniosek - Apache Hive vs. Apache HBase
Często Apache Hive vs. Apache HBase jest używany razem w tym samym klastrze. Oba mogą być używane razem w celu zwiększenia mocy przetwarzania. Ponieważ ul poprawia analityczne strony HDFS, a HBase poprawia transakcje w czasie rzeczywistym. Użytkownik może użyć Hive jako narzędzia ETL do wstawiania wsadowego z danymi do HBase, a następnie do wykonywania zapytań, które mogą dalej łączyć dane obecne w tabelach HBase z danymi, które są już obecne w HDFS. Dane można odczytywać i zapisywać z Apache Hive do HBase iz powrotem. Interfejs między Apache Hive i Apache HBase jest nadal w fazie dojrzewania. Jeszcze wiele więcej. Mimo to mogę powiedzieć, że zarówno Apache Hive vs. Apache HBase sprawia, że klaster Hadoop jest bardziej niezawodny i potężny.
Powiązane artykuły:
Jest to przewodnik po Apache Hive vs Apache HBase, ich znaczeniu, porównaniu między głowami, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Top 5 trendów Big Data
- 5 wyzwań analityki Big Data
- Jak złamać wywiad programisty Hadoop?
- 5 wyzwań analityki Big Data