
Wprowadzenie do eliminacji wstecznej
Gdy człowiek i maszyna pchają się ku ewolucji cyfrowej, maszyny o różnych technikach liczą na to, że nie tylko zostaną wyszkoleni, ale także inteligentnie wyszkoleni, aby wyjść z lepszym rozpoznawaniem rzeczywistych obiektów. Taka technika wprowadzona wcześniej pod nazwą „Backward Elimination”, która miała na celu sprzyjać niezbędnym funkcjom, jednocześnie eliminując funkcje nugatory, aby umożliwić lepszą optymalizację w maszynie. Cała biegłość w rozpoznawaniu obiektów przez maszynę jest proporcjonalna do cech, które bierze pod uwagę.
Funkcje, które nie mają odniesienia do przewidywanej mocy wyjściowej, muszą zostać rozładowane z maszyny i zakończone przez eliminację wsteczną. Dobra precyzja i złożoność czasowa rozpoznawania dowolnego rzeczywistego obiektu słownego przez maszynę zależą od jego uczenia się. Eliminacja wstecz odgrywa więc sztywną rolę przy wyborze funkcji. Oblicza, że szybkość zależności cech od zmiennej zależnej znajduje znaczenie jej przynależności w modelu. Aby to akredytować, sprawdza obliczoną stawkę ze standardowym poziomem istotności (powiedzmy 0, 06) i podejmuje decyzję o wyborze funkcji.
Dlaczego pociągamy za sobą eliminację wsteczną ?
Nieistotne i zbędne cechy napędzają złożoność logiki maszyny. Niepotrzebnie pochłania czas i zasoby modelu. Tak więc wyżej wspomniana technika odgrywa kompetentną rolę w tworzeniu modelu prostego. Algorytm kultywuje najlepszą wersję modelu, optymalizując jego wydajność i zmniejszając wyznaczone zasoby.
Objaśnia najmniej godne uwagi cechy modelu, które powodują hałas przy podejmowaniu decyzji o linii regresji. Nieistotne cechy obiektu mogą prowadzić do błędnej klasyfikacji i przewidywania. Nieistotne cechy bytu mogą stanowić nierównowagę w modelu w stosunku do innych istotnych cech innych przedmiotów. Eliminacja wsteczna sprzyja dopasowaniu modelu do najlepszego przypadku. Dlatego zaleca się stosowanie eliminacji wstecznej w modelu.
Jak zastosować eliminację wsteczną?
Eliminacja wsteczna rozpoczyna się od wszystkich zmiennych cech, testując ją zmienną zależną zgodnie z wybranym dopasowaniem kryterium modelu. Zaczyna eliminować te zmienne, które pogarszają dopasowaną linię regresji. Powtarzanie tego usuwania, dopóki model nie osiągnie dobrego dopasowania. Poniżej znajdują się kroki do ćwiczenia eliminacji wstecznej:
Krok 1: Wybierz odpowiedni poziom istotności, który ma znajdować się w modelu maszyny. (Weź S = 0, 06)
Krok 2: Podaj wszystkie dostępne zmienne niezależne do modelu w odniesieniu do zmiennej zależnej i komputeruj nachylenie i przechwyć, aby narysować linię regresji lub linii dopasowania.
Krok 3: Przejdź przez wszystkie zmienne niezależne, które mają najwyższą wartość (Take I), jeden po drugim i przejdź do następującego toastu:
a) Jeśli I> S, wykonaj 4. krok.
b) W przeciwnym razie model zostanie przerwany.
Krok 4: Usuń wybraną zmienną i zwiększ ruch przejścia.
Krok 5: Ponownie wykształć model, a następnie oblicz nachylenie i ponownie przejmij linię dopasowania za pomocą zmiennych resztkowych.
Wyżej wymienione etapy podsumowano w odrzuceniu tych cech, których wskaźnik istotności jest wyższy niż wybrana wartość istotności (0, 06), aby uniknąć nadmiernej klasyfikacji i nadmiernego wykorzystania zasobów, które zaobserwowano jako dużą złożoność.
Zalety i wady eliminacji wstecznej
Oto niektóre zalety i wady eliminacji wstecznej podane poniżej:
1. Meritum
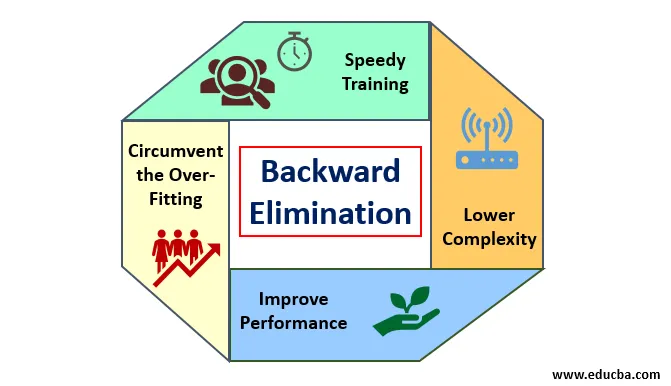
Korzyści z eliminacji wstecznej są następujące:
- Szybkie szkolenie: Maszyna jest trenowana z zestawem dostępnych cech wzoru, który jest wykonywany w bardzo krótkim czasie, jeśli z modelu zostaną usunięte niepotrzebne funkcje. Szybkie szkolenie zestawu danych pojawia się tylko wtedy, gdy model ma do czynienia z istotnymi cechami i wyklucza wszystkie zmienne szumowe. Rysuje prostą złożoność treningu. Ale model nie powinien ulegać niedopasowaniu, co występuje z powodu braku cech lub nieodpowiednich próbek. Przykładowa cecha powinna być obfita w modelu dla najlepszej klasyfikacji. Czas potrzebny na wytrenowanie modelu powinien być krótszy przy zachowaniu dokładności klasyfikacji i pozostawiony bez zmiennej niedopuszczalnej.
- Niższa złożoność: Złożoność modelu jest wysoka, jeśli model uwzględnia zakres cech, w tym szum i cechy niepowiązane. Model zajmuje dużo miejsca i czasu na przetworzenie takiego zakresu funkcji. Może to zwiększyć szybkość dokładności rozpoznawania wzoru, ale szybkość może również zawierać szum. Aby pozbyć się tak dużej złożoności modelu, algorytm eliminacji wstecznej odgrywa niezbędną rolę, eliminując niepożądane cechy z modelu. Upraszcza logikę przetwarzania modelu. Tylko kilka istotnych cech jest wystarczających do narysowania dobrego dopasowania, które zapewnia wystarczającą dokładność.
- Poprawa wydajności: wydajność modelu zależy od wielu aspektów. Model podlega optymalizacji poprzez eliminację wsteczną. Optymalizacja modelu to optymalizacja zestawu danych wykorzystywanego do szkolenia modelu. Wydajność modelu jest wprost proporcjonalna do jego szybkości optymalizacji, która zależy od częstotliwości istotnych danych. Proces eliminacji wstecznej nie ma na celu rozpoczęcia zmiany z jakiegokolwiek predykatora niskiej częstotliwości. Ale zaczyna się zmiana na podstawie danych o wysokiej częstotliwości, ponieważ głównie złożoność modelu zależy od tej części.
- Obejście nadmiernego dopasowania: sytuacja nadmiernego dopasowania występuje, gdy model ma zbyt wiele zestawów danych i przeprowadzana jest klasyfikacja lub prognoza, w której niektóre predyktory mają szum innych klas. W tym dopasowaniu model miał dawać nieoczekiwanie wysoką dokładność. W przypadku nadmiernego dopasowania model może nie sklasyfikować zmiennej z powodu zamieszania powstałego w logice z powodu zbyt wielu warunków. Technika eliminacji wstecznej ogranicza zewnętrzną cechę w celu uniknięcia sytuacji nadmiernego dopasowania.
2. Wady
Wady eliminacji wstecznej są następujące:
- W metodzie eliminacji wstecznej nie można dowiedzieć się, który predykator jest odpowiedzialny za odrzucenie innego predykatora z powodu jego nieistotności. Na przykład, jeśli predykator X ma pewne znaczenie, które było wystarczająco dobre, aby znajdować się w modelu po dodaniu predykatora Y. Ale znaczenie X staje się przestarzałe, gdy do modelu wchodzi inny predykator Z. Zatem algorytm eliminacji wstecznej nie wykazuje żadnej zależności między dwoma predyktorami, które występują w „technice selekcji do przodu”.
- Po usunięciu dowolnej cechy z modelu za pomocą algorytmu eliminacji wstecznej nie można ponownie wybrać tej cechy. Krótko mówiąc, eliminacja wsteczna nie ma elastycznego podejścia do dodawania lub usuwania funkcji / predyktorów.
- Normy wyboru wartości istotności (0, 06) w modelu są nieelastyczne. Eliminacja wsteczna nie ma elastycznej procedury, która nie tylko wybiera, ale także zmienia nieznaczną wartość zgodnie z wymaganiami, aby uzyskać najlepsze dopasowanie w ramach odpowiedniego zestawu danych.
Wniosek
Technika eliminacji wstecznej realizowana w celu poprawy wydajności modelu i zoptymalizowania jego złożoności. Jest on żywo stosowany w wielu regresjach, w których model zajmuje się obszernym zestawem danych. Jest to łatwe i proste podejście w porównaniu do wybierania do przodu i weryfikacji krzyżowej, w których wystąpiło przeciążenie optymalizacji. Technika eliminacji wstecznej inicjuje eliminację cech o wyższej wartości istotności. Jego podstawowym celem jest zmniejszenie złożoności modelu i zakazanie nadmiernego dopasowania.
Polecane artykuły
Jest to przewodnik po eliminacji wstecznej. Tutaj omawiamy, jak zastosować eliminację wsteczną wraz z zaletami i wadami. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej-
- Uczenie maszynowe hiperparametrów
- Grupowanie w uczenie maszynowe
- Maszyna wirtualna Java
- Uczenie maszynowe bez nadzoru