
Wprowadzenie do potoku danych AWS
Dane rosną wykładniczo z dnia na dzień i stają się trudne do zarządzania w porównaniu do przeszłości. Potrzebujemy narzędzi i usług do wydajnego zarządzania naszymi danymi przy niższych kosztach - właśnie tam przychodzi na myśl Potok Danych AWS. Nie chodzi tylko o przechowywanie danych, ale musisz analizować, przetwarzać, przekształcać dane w pożądaną formę w tym samym miejscu, wszystko to można osiągnąć dzięki AWS Data Pipeline.
Potrzeba potoku danych
Spróbujmy zrozumieć potrzebę potoku danych na przykładzie:
Przykład 1
Mamy stronę internetową, która wyświetla obrazy i gify na podstawie wyszukiwań użytkowników lub filtrów. Naszym głównym celem jest wyświetlanie treści. Są pewne cele do osiągnięcia, które są następujące:
- Poprawa dostarczania treści: serwowanie tego, czego oczekują użytkownicy skutecznie i wystarczająco szybko.
- Wydajne zarządzanie aplikacją: przechowywanie danych użytkownika, a także dzienników witryny do późniejszych celów analitycznych.
- Ulepsz biznes: Wykorzystanie przechowywanych danych i danych analitycznych powoduje, że biznes staje się lepszy po niższych kosztach.
Przykład nr 2
Istnieją pewne wąskie gardła, którymi należy się zająć, aby osiągnąć cele:
- Ogromna ilość danych w różnych formatach i różnych miejscach, co sprawia, że przetwarzanie, przechowywanie i migracja danych jest złożonym zadaniem.
Różne komponenty do przechowywania danych dla różnych typów danych:
- Możliwe dane w czasie rzeczywistym dla zarejestrowanych użytkowników: Dynamo DB .
- Dzienniki serwera WWW dla potencjalnych użytkowników: Amazon S3 .
- Dane demograficzne i dane logowania: Amazon RDS.
- Dane czujnika i zestaw danych innych firm: Amazon S3.
Rozwiązania
- Wykonalne rozwiązanie: widzimy, że mamy do czynienia z różnego rodzaju narzędziami do konwersji danych z nieustrukturyzowanych na strukturyzowane do analizy. Tutaj musimy użyć różnych narzędzi do przechowywania danych i ponownie do konwersji, analizy i przechowywania przetworzonych danych. Nie jest to opłacalne rozwiązanie.
- Optymalne rozwiązanie: użyj potoku danych, który obsługuje przetwarzanie, wizualizację i migrację. Potok danych może być przydatny w migracji danych z różnych miejsc, analizując dane i przetwarzając je w tym samym miejscu w Twoim imieniu.
Co to jest potok danych AWS?
AWS Data Pipeline to zasadniczo usługa internetowa oferowana przez Amazon, która pomaga przekształcać, przetwarzać i analizować dane w skalowalny i niezawodny sposób, a także przechowywać przetwarzane dane w S3, DynamoDb lub lokalnej bazie danych.
- Dzięki AWS Data Pipeline możesz łatwo uzyskać dostęp do danych z różnych źródeł.
- Przetwarzaj i przetwarzaj te dane w skali.
- Wydajnie przesyłaj wyniki do innych usług, takich jak S3, tabela DynamoDb lub lokalny magazyn danych.
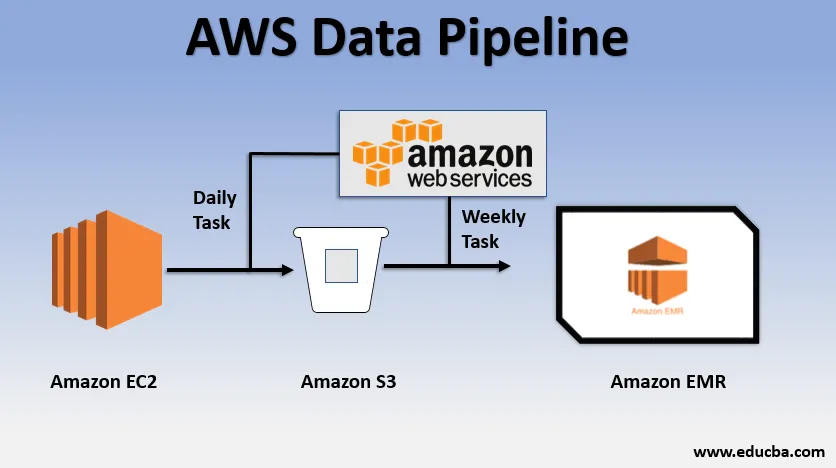
Przykład podstawowego użycia potoku danych
- Moglibyśmy mieć stronę internetową wdrożoną przez EC2, która generuje dzienniki każdego dnia.
- Proste codzienne zadanie można skopiować pliki dziennika z E2 i osiągnąć je do segmentu S3.
- Cotygodniowym zadaniem może być przetwarzanie danych i uruchamianie analizy danych w Amazon EMR w celu generowania tygodniowych raportów na podstawie wszystkich zebranych danych.
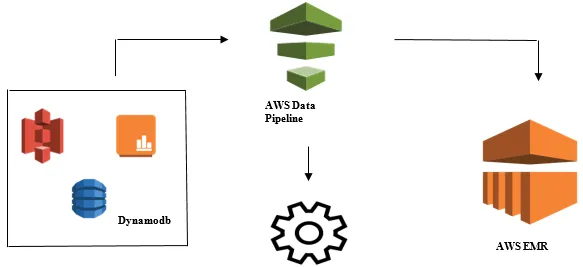
Uruchamianie analizy danych za pomocą potoku danych AWS
- Zbieranie danych z różnych źródeł danych, takich jak - S3, Dynamodb, lokalny, dane z czujników itp.
- Przeprowadzanie transformacji, przetwarzania i analiz w AWS EMR w celu generowania cotygodniowych raportów.
- Raport tygodniowy zapisywany w Redshift, S3 lub lokalnej bazie danych.
Korzyści z potoku danych AWS
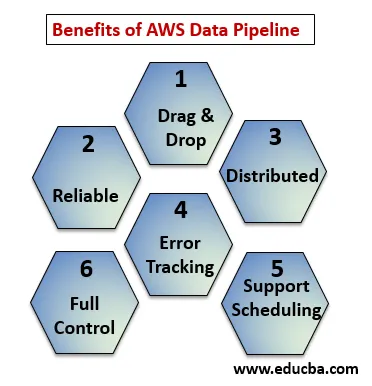
Poniżej punkty wyjaśniają zalety potoku danych AWS:
- Przeciągnij i upuść konsolę, która jest łatwa do zrozumienia i użycia.
- Rozproszona i niezawodna infrastruktura: potoki danych działają na usługach skalowalnych i są niezawodne, jeśli wystąpi błąd lub zadanie, można ustawić ponawianie próby.
- Obsługuje planowanie i śledzenie błędów: możesz zaplanować swoje zadania i śledzić je pod kątem niepowodzenia i sukcesu.
- Rozproszony: może być uruchomiony równolegle na wielu komputerach lub liniowo.
- Pełna kontrola nad zasobami obliczeniowymi, takimi jak EC2, klastry EMR.
Elementy rurociągu danych AWS
Poniżej znajdują się elementy potoku danych AWS:
1. Definicja rurociągu
Przekształć logikę biznesową w potok danych AWS.
- Węzły danych : Zawiera nazwę, lokalizację, format źródła danych, którymi może być (S3, dynamodb, lokalnie)
- Działania : przenoszenie, przekształcanie lub wykonywanie zapytań dotyczących danych.
- Zaplanuj : Zaplanuj codzienne lub cotygodniowe zajęcia.
- Warunek wstępny : warunki takie jak uruchomienie harmonogramu sprawdzają dostępność danych u źródła.
- Zasoby : Oblicz zasoby EC2, EMR.
- Działania : Aktualizuj informacje o potoku danych, wysyłaniu powiadomień, wyzwalaniu alarmu.
2. Rurociągi
Tutaj planujesz i uruchamiasz zadania w celu wykonania zdefiniowanych działań.
- Komponenty rurociągu : Komponenty rurociągu są takie same jak komponenty definicji rurociągu.
- Instancje: Podczas uruchamiania zadań AWS kompiluje wszystkie komponenty, aby utworzyć określone instancje, które można wykonać. Takie instancje zawierają wszystkie informacje o konkretnych zadaniach.
- Próby: już dyskutowaliśmy o tym, jak wiarygodny jest potok danych z mechanizmami ponownej próby. Tutaj ustawiasz, ile razy chcesz ponawiać zadanie w przypadku niepowodzenia.
3. Task Runner
Pyta lub odpytuje o zadania z potoku danych AWS, a następnie wykonuje te zadania.
Ceny rurociągów danych AWS
Poniżej punkty wyjaśniają ceny rurociągów danych AWS:
1. Darmowy poziom
Możesz rozpocząć korzystanie z AWS Data Pipeline za darmo jako część warstwy bezpłatnego użytkowania AWS. Nowi klienci rejestrujący otrzymują co miesiąc bezpłatne świadczenia przez rok:
- 3 Warunki wstępne niskiej częstotliwości działające na AWS bez żadnych opłat.
- 5 Działania na niskiej częstotliwości działające na AWS bez żadnych opłat.
2. Niska częstotliwość
Niska częstotliwość ma być uruchamiana raz dziennie lub krócej. Pipeline danych jest zgodny z tą samą strategią rozliczeniową, co inne usługi sieciowe AWS, tzn. Rozliczane za korzystanie. Jest zależny od tego, jak często Twoje zadania, działania i warunki wstępne są uruchamiane każdego dnia i gdzie działają (AWS lub lokalnie). Działania o wysokiej częstotliwości są zaplanowane na więcej niż raz dziennie.
Przykład: Możemy zaplanować działanie tak, aby uruchamiało się co godzinę i przetwarzało dzienniki witryny lub może to być co 12 godzin. Natomiast działania o niskiej częstotliwości to te, które są uruchamiane raz dziennie lub rzadziej, jeśli warunki wstępne nie są spełnione. Nieaktywne rurociągi mają stan NIEAKTYWNY, OCZEKUJĄCY i ZAKOŃCZONY.
3. Wycena potoku danych AWS pokazana z uwzględnieniem regionu
Region nr 1: Wschodni USA (N.Virginia), Zachodni USA (Oregon), Azja Pacyfik (Sydney), UE (Irlandia)
| Wysoka częstotliwość | Niska częstotliwość | |
| Działania lub warunki wstępne działające w AWS | 1, 00 USD miesięcznie | 0, 06 USD miesięcznie |
| Działania lub warunki wstępne działające lokalnie | 2, 50 USD miesięcznie | 1, 50 USD miesięcznie |
| Nieaktywne rurociągi: 1, 00 USD miesięcznie |
Region nr 2: Azja i Pacyfik (Tokio)
| Wysoka częstotliwość | Niska częstotliwość | |
| Działania lub warunki wstępne działające w AWS | 0, 9524 USD na miesiąc | 0, 5715 USD miesięcznie |
| Działania lub warunki wstępne działające lokalnie | 2, 381 USD na miesiąc | 1, 4286 USD na miesiąc |
| Nieaktywne rurociągi: 0, 9524 USD miesięcznie |
Potok, że codzienne zadanie, tj. Działanie niskiej częstotliwości w AWS, do przenoszenia danych z tabeli DynamoDB do Amazon S3, kosztowałoby 0, 60 USD miesięcznie. Jeśli dodamy EC2 w celu wygenerowania raportu na podstawie danych Amazon S3, całkowity koszt rurociągu wyniesie 1, 20 USD miesięcznie. Jeśli prowadzimy tę aktywność co 6 godzin, będzie to kosztować 2, 00 USD miesięcznie, ponieważ wtedy będzie to aktywność o wysokiej częstotliwości.
Wniosek
AWS Data Pipeline to bardzo przydatne rozwiązanie do zarządzania wykładniczo rosnącymi danymi przy niższych kosztach. Jest bardzo niezawodny, a także skalowalny w zależności od zastosowania. AWS Data Pipeline to bardzo dobry wybór do realizacji wszystkich naszych celów biznesowych, niezależnie od potrzeb biznesowych związanych z dużą ilością danych.
Polecane artykuły
Jest to przewodnik po potoku danych AWS. Tutaj omawiamy potrzeby potoku danych, czym jest potok danych AWS, jego szczegóły dotyczące komponentów i cen. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej -
- AWS EBS
- Bazy danych AWS
- Co to jest AWS EC2?
- Korzyści z wizualizacji danych
- 7 najlepszych konkurentów AWS z funkcjami
- Poznaj listę funkcji Amazon Web Services