

Różnica między Big Data a Apache Hadoop
Wszystko jest w Internecie. Internet ma dużo danych. Dlatego wszystko to Big Data. Czy wiesz, że 2, 5 kwintilliona bajtów są tworzone codziennie i gromadzą się w postaci Big Data? Nasze codzienne czynności, takie jak komentowanie, polubienia, posty itp. W mediach społecznościowych, takich jak Facebook, LinkedIn, Twitter i Instagram, są liczone jako Big Data. Zakłada się, że do 2020 r. Co sekundę zostanie stworzonych prawie 1, 7 megabajta danych dla każdej osoby na ziemi. Możesz sobie wyobrazić i rozważyć, ile danych jest generowanych, zakładając, że każda osoba na ziemi. Dziś jesteśmy połączeni i dzielimy się naszym życiem online. Większość z nas jest połączona z Internetem. Żyjemy w inteligentnym domu i używamy inteligentnych pojazdów, a wszyscy są podłączeni do naszych smartfonów. Czy kiedykolwiek wyobrażasz sobie, jak te urządzenia stają się inteligentne? Chciałbym dać bardzo prostą odpowiedź, ponieważ jest to spowodowane analizą bardzo dużej ilości danych, tj. Big Data. W ciągu pięciu lat na świecie będzie ponad 50 miliardów inteligentnych urządzeń, wszystkie opracowane w celu gromadzenia, analizowania i udostępniania danych, aby uczynić nasze życie wygodniejszym.
Poniżej przedstawiono wprowadzenie Big Data vs. Apache Hadoop
Przedstawiamy termin Big Data
Co to jest Big Data? Jaki rozmiar danych jest uważany za duży i będzie określany jako Big Data? Mamy wiele względnych założeń dotyczących terminu Big Data. Możliwe, że ilość danych mówi, że 50 terabajtów można uznać za duże zbiory danych dla Start-upów, ale może nie być to Big Data dla firm takich jak Google i Facebook. To dlatego, że mają infrastrukturę do przechowywania i przetwarzania takiej ilości danych. Chciałbym zdefiniować termin Big Data jako:
- Big Data to ilość danych przekraczająca możliwości technologii w zakresie efektywnego przechowywania, zarządzania i przetwarzania.
- Big Data to dane, których skala, różnorodność i złożoność wymagają nowej architektury, technik, algorytmów i analiz do zarządzania nimi oraz wydobywania z nich wartości i ukrytej wiedzy.
- Duże zbiory danych to zasoby informacyjne o dużej objętości, dużej prędkości i różnorodności, które wymagają opłacalnych, innowacyjnych form przetwarzania informacji, które umożliwiają lepszy wgląd, podejmowanie decyzji i automatyzację procesów.
- Big Data odnosi się do technologii i inicjatyw, które dotyczą danych, które są zbyt różnorodne, szybko się zmieniają lub są masywne, aby konwencjonalne technologie, umiejętności i infrastruktura mogły skutecznie rozwiązać. Inaczej mówiąc, objętość, prędkość lub różnorodność danych jest zbyt duża.
3 V z Big Data
- Objętość: Objętość odnosi się do ilości / ilości, przy której tworzone są dane, tak jak Co godzinę transakcje klientów Wal-Mart dostarczają firmie około 2, 5 petabajtów danych.
- Velocity: Velocity odnosi się do prędkości, z jaką poruszają się dane, tak jak użytkownicy Facebooka wysyłają średnio 31, 25 miliona wiadomości i oglądają 2, 77 miliona filmów co minutę każdego dnia przez Internet.
- Różnorodność: Różnorodność odnosi się do różnych formatów danych tworzonych, takich jak dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane. Podobnie jak wysyłanie wiadomości e-mail z załącznikiem w Gmailu to nieustrukturyzowane dane, a publikowanie komentarzy z niektórymi linkami zewnętrznymi jest również określane jako dane nieustrukturyzowane. Udostępnianie zdjęć, klipów audio i klipów wideo to nieuporządkowana forma danych.
Przechowywanie i przetwarzanie tak dużej ilości, prędkości i różnorodności danych to duży problem. Musimy wymyślić inną technologię niż RDBMS dla Big Data. Jest tak, ponieważ RDBMS jest w stanie przechowywać i przetwarzać tylko dane ustrukturyzowane. Więc tutaj Apache Hadoop przychodzi na ratunek.
Przedstawiamy Term Apache Hadoop
Apache Hadoop to platforma oprogramowania typu open source do przechowywania danych i uruchamiania aplikacji na klastrach sprzętu. Apache Hadoop to platforma programowa, która pozwala na rozproszone przetwarzanie dużych zbiorów danych w klastrach komputerów przy użyciu prostych modeli programowania. Został zaprojektowany do skalowania z pojedynczych serwerów na tysiące komputerów, z których każdy oferuje lokalne obliczenia i pamięć. Apache Hadoop to platforma do przechowywania i przetwarzania Big Data. Apache Hadoop jest w stanie przechowywać i przetwarzać wszystkie formaty danych, takie jak dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane. Apache Hadoop to sprzęt typu open source, a towary towarowe przyniosły rewolucję w branży IT. Jest łatwo dostępny dla każdego poziomu firm. Nie muszą więcej inwestować, aby skonfigurować klaster Hadoop i inną infrastrukturę. Zobaczmy więc szczegółowo użyteczną różnicę między Big Data a Apache Hadoop w tym poście.
Framework Apache Hadoop
Framework Apache Hadoop jest podzielony na dwie części:
- Hadoop Distributed File System (HDFS): Ta warstwa jest odpowiedzialna za przechowywanie danych.
- MapReduce: ta warstwa odpowiada za przetwarzanie danych w klastrze Hadoop.
Hadoop Framework jest podzielony na architekturę master i slave. Warstwa HDado (Hadoop Distributed File System) Węzeł jest składnikiem głównym, podczas gdy węzeł danych jest składnikiem podrzędnym, podczas gdy w warstwie MapReduce moduł śledzenia zadań jest składnikiem głównym, a moduł śledzenia zadań jest składnikiem podrzędnym. Poniżej znajduje się schemat frameworka Apache Hadoop.
Dlaczego Apache Hadoop jest ważny?
- Możliwość szybkiego przechowywania i przetwarzania ogromnych ilości dowolnego rodzaju danych
- Moc obliczeniowa: rozproszony model obliczeniowy Hadoop szybko przetwarza duże zbiory danych. Im więcej węzłów obliczeniowych używasz, tym więcej masz mocy obliczeniowej.
- Odporność na awarie: Przetwarzanie danych i aplikacji jest chronione przed awarią sprzętu. W przypadku awarii węzła zadania są automatycznie przekierowywane do innych węzłów, aby upewnić się, że przetwarzanie rozproszone nie zawiedzie. Wiele kopii wszystkich danych jest przechowywanych automatycznie.
- Elastyczność: możesz przechowywać tyle danych, ile chcesz i później zdecydować, jak je wykorzystać. Obejmuje to nieustrukturyzowane dane, takie jak tekst, obrazy i filmy.
- Niski koszt: platforma open source jest bezpłatna i wykorzystuje sprzęt do przechowywania dużych ilości danych.
- Skalowalność: Możesz łatwo rozbudować swój system, aby obsługiwał więcej danych, po prostu dodając węzły. Wymagana jest niewielka administracja
Bezpośrednie porównanie między Big Data a Apache Hadoop (infografiki)
Poniżej znajduje się 4 najlepsze porównanie między Big Data a Apache Hadoop
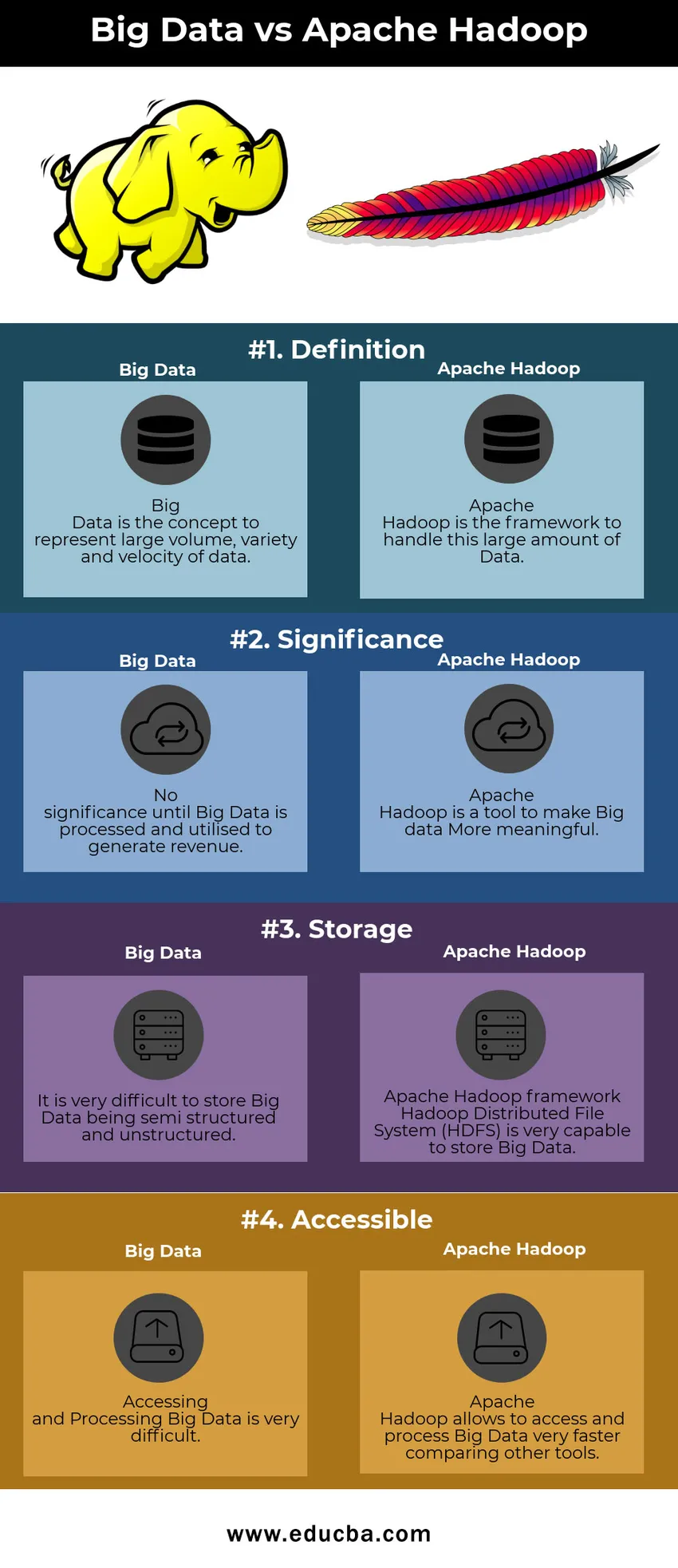
Tabela porównawcza Big Data vs. Apache Hadoop
Omawiam główne artefakty i odróżniam Big Data od Apache Hadoop
| Big Data | Apache Hadoop | |
| Definicja | Big Data to koncepcja dużej ilości, różnorodności i prędkości danych | Apache Hadoop to platforma do obsługi tak dużej ilości danych |
| Znaczenie | Nie ma znaczenia, dopóki Big Data nie zostanie przetworzone i wykorzystane do generowania przychodów | Apache Hadoop to narzędzie, dzięki któremu duże zbiory danych będą bardziej znaczące |
| Przechowywanie | Bardzo trudno jest przechowywać Big Data jako częściowo ustrukturyzowany i nieustrukturyzowany | Framework Apache Hadoop Hadoop Distributed File System (HDFS) jest bardzo zdolny do przechowywania Big Data |
| Dostępny | Dostęp i przetwarzanie dużych zbiorów danych jest bardzo trudne | Apache Hadoop pozwala na dostęp i przetwarzanie danych Big Data bardzo szybko w porównaniu z innymi narzędziami |
Wniosek - Big Data vs. Apache Hadoop
Nie można porównywać Big Data i Apache Hadoop. Jest tak, ponieważ Big Data stanowi problem, podczas gdy Apache Hadoop jest rozwiązaniem. Ponieważ ilość danych rośnie wykładniczo we wszystkich sektorach, bardzo trudno jest przechowywać i przetwarzać dane z jednego systemu. Aby więc przetwarzać tak dużą ilość danych, potrzebujemy rozproszonego przetwarzania i przechowywania danych. Dlatego Apache Hadoop oferuje rozwiązanie do przechowywania i przetwarzania bardzo dużej ilości danych. Na koniec stwierdzę, że Big Data to duża ilość złożonych danych, podczas gdy Apache Hadoop to mechanizm do przechowywania i przetwarzania dużych zbiorów danych w bardzo wydajny i płynny sposób.
Polecany artykuł
Jest to przewodnik po Big Data vs Apache Hadoop, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. ten artykuł zawiera wszystkie przydatne różnice między Big Data a Apache Hadoop. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Big Data vs Data Science - czym się różnią?
- Top 5 trendów Big Data, które firmy będą musiały opanować
- Hadoop vs Apache Spark - ciekawe rzeczy, które musisz wiedzieć
- Apache Hadoop vs Apache Spark | 10 najlepszych porównań, które musisz znać!