

Wprowadzenie do eksploracji danych
Jest to metoda eksploracji danych stosowana do umieszczania elementów danych w podobnych grupach. Klaster to procedura dzielenia obiektów danych na podklasy. Jakość klastrowania zależy od zastosowanej metody. Klastrowanie jest również nazywane segmentacją danych, ponieważ duże grupy danych są podzielone według ich podobieństwa.
Co to jest klastrowanie w eksploracji danych?
Grupowanie to grupowanie określonych obiektów na podstawie ich cech i podobieństw. Jeśli chodzi o eksplorację danych, ta metodologia dzieli dane, które najlepiej pasują do pożądanej analizy, za pomocą specjalnego algorytmu łączenia. Ta analiza pozwala, aby obiekt nie był częścią ani ściśle częścią klastra, co nazywa się twardym partycjonowaniem tego typu. Jednak gładkie partycje sugerują, że każdy obiekt w tym samym stopniu należy do klastra. Można tworzyć bardziej szczegółowe podziały, takie jak obiekty wielu klastrów, pojedynczy klaster można zmusić do uczestnictwa, a nawet hierarchiczne drzewa można konstruować w relacjach grupowych. Ten system plików można wprowadzić na różne sposoby w zależności od różnych modeli. Te odrębne algorytmy mają zastosowanie do każdego modelu, rozróżniając ich właściwości, a także ich wyniki. Dobry algorytm grupowania jest w stanie zidentyfikować klaster niezależnie od jego kształtu. Istnieją 3 podstawowe etapy algorytmu grupowania, które pokazano poniżej
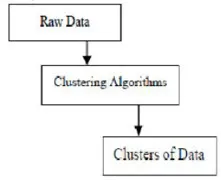
Algorytmy grupowania w eksploracji danych
W zależności od ostatnio opisanych modeli klastrów można użyć wielu klastrów do podzielenia informacji na zestaw danych. Należy powiedzieć, że każda metoda ma swoje zalety i wady. Wybór algorytmu zależy od właściwości i charakteru zestawu danych.
Metody grupowania dla eksploracji danych można pokazać jak poniżej
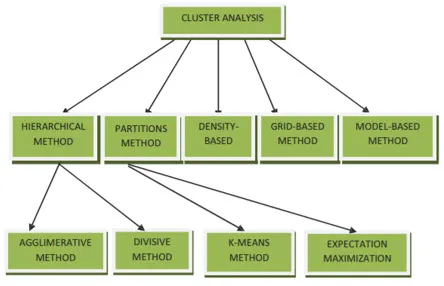
- Metoda oparta na partycjonowaniu
- Metoda oparta na gęstości
- Metoda oparta na centroidach
- Metoda hierarchiczna
- Metoda oparta na siatce
- Metoda oparta na modelu
1. Metoda oparta na partycjonowaniu
Algorytm podziału dzieli dane na wiele podzbiorów.
Załóżmy, że algorytm partycjonowania buduje partycję danych, ponieważ k i n oznacza, że obiekty są obecne w bazie danych. Dlatego każda partycja będzie reprezentowana jako k ≤ n.
To daje wyobrażenie, że klasyfikacja danych jest w k grupach, co można pokazać poniżej
Rysunek 1 pokazuje oryginalne punkty w grupowaniu

Rysunek 2 pokazuje grupowanie partycji po zastosowaniu algorytmu
Oznacza to, że każda grupa ma co najmniej jeden obiekt, a każdy obiekt musi należeć do dokładnie jednej grupy.
2. Metoda oparta na gęstości
Algorytmy te wytwarzają klastry w określonej lokalizacji w oparciu o dużą gęstość uczestników zestawu danych. Agreguje pewne pojęcie zakresu dla członków grupy w klastrach do poziomu standardu gęstości. Takie procesy mogą działać mniej w wykrywaniu obszarów powierzchni grupy.
3. Metoda oparta na centroidach
Prawie do każdego klastra odwołuje się wektor wartości w tego typu technice grupowania os. W porównaniu z innymi klastrami, każdy obiekt jest częścią klastra o minimalnej różnicy wartości. Liczba klastrów powinna być predefiniowana, a to jest największy problem algorytmowy tego typu. Metodologia ta jest najbliższa tematowi identyfikacji i jest szeroko stosowana w przypadku problemów związanych z optymalizacją.
4. Metoda hierarchiczna
Metoda utworzy hierarchiczny rozkład danego zestawu obiektów danych. Na podstawie tego, jak powstaje rozkład hierarchiczny, możemy klasyfikować metody hierarchiczne. Ta metoda jest podana w następujący sposób
- Podejście aglomeracyjne
- Podejście dzielące
Podejście aglomeracyjne znane jest również pod nazwą Podejście guzikowe. Tutaj zaczynamy od każdego obiektu, który stanowi oddzielną grupę. Nadal łączy obiekty lub grupy blisko siebie
Podejście dzielące jest również znane jako podejście odgórne. Zaczynamy od wszystkich obiektów w tej samej grupie. Ta metoda jest sztywna, tzn. Nigdy nie można jej cofnąć po zakończeniu fuzji lub podziału
5. Metoda oparta na siatce
Metody oparte na siatce działają w przestrzeni obiektów zamiast dzielić dane na siatkę. Siatka jest podzielona na podstawie cech danych. Dzięki tej metodzie dane nieliczbowe są łatwe do zarządzania. Kolejność danych nie wpływa na partycjonowanie siatki. Ważną zaletą modelu opartego na siatce jest szybsze wykonanie.
Zalety hierarchicznego grupowania są następujące
- Ma zastosowanie do każdego typu atrybutu.
- Zapewnia elastyczność związaną z poziomem szczegółowości.
6. Metoda oparta na modelu
Ta metoda wykorzystuje hipotetyczny model oparty na rozkładzie prawdopodobieństwa. Poprzez grupowanie funkcji gęstości metoda ta lokalizuje klastry. Odzwierciedla rozkład przestrzenny punktów danych.
Zastosowanie klastrowania w Data Mining
Klastrowanie może pomóc w wielu dziedzinach, takich jak biologia, rośliny i zwierzęta sklasyfikowane według ich właściwości, a także w marketingu, klastrowanie pomoże zidentyfikować klientów określonego rekordu klienta o podobnym zachowaniu. W wielu aplikacjach, takich jak badania rynku, rozpoznawanie wzorców, przetwarzanie danych i obrazów, analiza klastrowa jest wykorzystywana w dużych ilościach. Klastrowanie może również pomóc reklamodawcom w bazie klientów znaleźć różne grupy. Ich grupy klientów można definiować za pomocą wzorców zakupu. W biologii stosuje się go do określania taksonomii roślin i zwierząt, do kategoryzacji genów o podobnej funkcjonalności i do wglądu w struktury właściwe dla populacji. W bazie danych obserwacji Ziemi klastrowanie ułatwia również znajdowanie obszarów o podobnym zastosowaniu na lądzie. Pomaga zidentyfikować grupy domów i mieszkań według rodzaju, wartości i przeznaczenia domów. Grupowanie dokumentów w Internecie jest również pomocne w odkrywaniu informacji. Analiza skupień jest narzędziem do uzyskiwania wglądu w rozkład danych w celu obserwacji cech każdego skupienia jako funkcji eksploracji danych.
Wniosek
Klastrowanie jest ważne w eksploracji danych i ich analizie. W tym artykule widzieliśmy, jak można grupować, stosując różne algorytmy klastrowania, a także ich zastosowanie w prawdziwym życiu.
Polecany artykuł
To był przewodnik po klastrowaniu w Data Mining. Tutaj omówiliśmy pojęcia, definicję, funkcje, zastosowanie klastrowania w Data Mining. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Co to jest przetwarzanie danych?
- Jak zostać analitykiem danych?
- Co to jest SQL Injection?
- Definicja czym jest SQL Server?
- Omówienie architektury eksploracji danych
- Grupowanie w uczenie maszynowe
- Hierarchiczny algorytm grupowania
- Hierarchiczne grupowanie | Grupowanie aglomeracyjne i dzielące