

Wprowadzenie do dołączenia w Spark SQL
Jak wiemy, sprzężenia w SQL są używane do łączenia danych lub wierszy z dwóch lub więcej tabel w oparciu o wspólne pole między nimi. W tym temacie dowiemy się o Dołącz w Spark SQL Dołącz w Spark SQL.
W Spark SQL, ramka danych lub zestaw danych to struktura tabelaryczna w pamięci, mająca wiersze i kolumny rozmieszczone w wielu węzłach. Podobnie jak normalne tabele SQL, możemy również wykonywać operacje łączenia na ramce danych lub zestawie danych obecnych w Spark SQL na podstawie wspólnego pola między nimi.
Istnieją różne rodzaje operacji łączenia dostępne w języku SQL. W zależności od przypadku zastosowania biznesowego wybieramy operację Dołącz. W poniższej sekcji przedstawimy przykład każdego rodzaju złączenia.
Rodzaje łączenia w Spark SQL
Poniżej przedstawiono różne typy połączeń dostępne w Spark SQL:
- DOŁĄCZ DO WEWNĘTRZNEGO
- KRZYŻ DOŁĄCZ
- DOŁĄCZ DO LEWEGO ZEWNĘTRZNEGO
- DOŁĄCZ DO PRAWEJ ZEWNĘTRZNEJ
- DOŁĄCZ DO ZEWNĘTRZNEGO
- POŁĄCZ LEWĄ SEMI
- LEWY ANTY DOŁĄCZ
Przykład tworzenia danych
Wykorzystamy następujące dane, aby zademonstrować różne rodzaje złączeń:
Zestaw danych książki:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
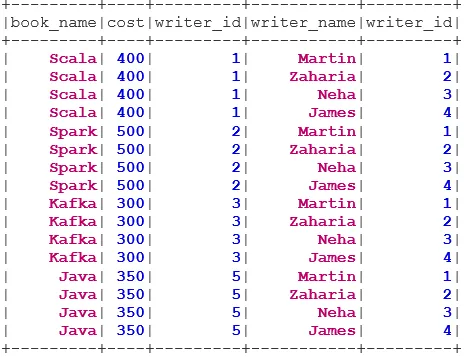
bookDS.show()

Zestaw danych pisarza:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Rodzaje połączeń
Poniżej wymieniono 7 różnych rodzajów połączeń:
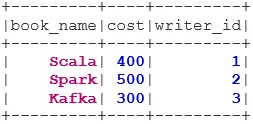
1. DOŁĄCZ DO WEWNĘTRZNEGO
WEJŚCIE WEWNĘTRZNE zwraca zestaw danych, który ma wiersze, które mają pasujące wartości w obu zestawach danych, tj. Wartość wspólnego pola będzie taka sama.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. POŁĄCZENIE KRZYŻOWE
CROSS JOIN zwraca zestaw danych, który jest liczbą wierszy w pierwszym zestawie danych pomnożoną przez liczbę wierszy w drugim zestawie danych. Taki rodzaj wyniku nazywa się produktem kartezjańskim.
Warunek: do korzystania z połączenia krzyżowego parametr spark.sql.crossJoin.enabled musi mieć wartość true. W przeciwnym razie wyjątek zostanie zgłoszony.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. DOŁĄCZ DO LEWEGO ZEWNĘTRZNEGO
POŁĄCZENIE W LEWO ZEWNĘTRZNE zwraca zestaw danych zawierający wszystkie wiersze z lewego zestawu danych i dopasowane wiersze z prawego zestawu danych.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. DOŁĄCZ DO PRAWEJ ZEWNĘTRZNEJ
DOŁĄCZ DO PRAWEJ ZEWNĘTRZNEJ zwraca zestaw danych, który zawiera wszystkie wiersze z prawego zestawu danych, i dopasowane wiersze z lewego zestawu danych.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. PEŁNE DOŁĄCZENIE ZEWNĘTRZNE
FULL OUTER JOIN zwraca zestaw danych, który ma wszystkie wiersze, gdy występuje dopasowanie w lewym lub prawym zestawie danych.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LEWE POŁĄCZENIE SEMI
LEFT SEMI JOIN zwraca zestaw danych, który ma wszystkie wiersze z lewego zestawu danych, odpowiadające prawemu zestawowi danych. W przeciwieństwie do LEFT OUTER JOIN, zwrócony zestaw danych w LEFT SEMI JOIN zawiera tylko kolumny z lewego zestawu danych.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LEWE ANTY DOŁĄCZ
ANTI SEMI JOIN zwraca zestaw danych, który zawiera wszystkie wiersze z lewego zestawu danych, które nie mają zgodnego zestawu w prawym zestawie danych. Zawiera także tylko kolumny z lewego zestawu danych.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Wniosek - Dołącz w Spark SQL
Łączenie danych jest jedną z najczęstszych i najważniejszych operacji służących realizacji naszego biznesowego przypadku użycia. Spark SQL obsługuje wszystkie podstawowe typy złączeń. Dołączając, musimy również wziąć pod uwagę wydajność, ponieważ mogą one wymagać dużych transferów sieciowych, a nawet tworzyć zestawy danych przekraczające nasze możliwości. W celu poprawy wydajności Spark używa optymalizatora SQL do ponownego zamawiania lub wypychania filtrów. Spark ogranicza także niebezpieczne połączenie i. e KRZYŻ DOŁĄCZ. Aby użyć łączenia krzyżowego, spark.sql.crossJoin.enabled musi być jawnie ustawiony na true.
Polecane artykuły
Jest to przewodnik dołączania do Spark SQL. W tym przykładzie omawiamy różne typy połączeń dostępne w Spark SQL z przykładem. Możesz także spojrzeć na następujący artykuł.
- Rodzaje złączeń w SQL
- Tabela w SQL
- Zapytanie wstawiania SQL
- Transakcje w SQL
- Filtry PHP | Jak sprawdzić poprawność danych wprowadzanych przez użytkownika za pomocą różnych filtrów?