
Wprowadzenie procesu ETL
ETL jest jednym z ważnych procesów wymaganych przez Business Intelligence. Business Intelligence opiera się na danych przechowywanych w hurtowniach danych, z których generowanych jest wiele analiz i raportów, co pomaga w budowaniu bardziej skutecznych strategii i prowadzi do taktycznych i operacyjnych spostrzeżeń i podejmowania decyzji.
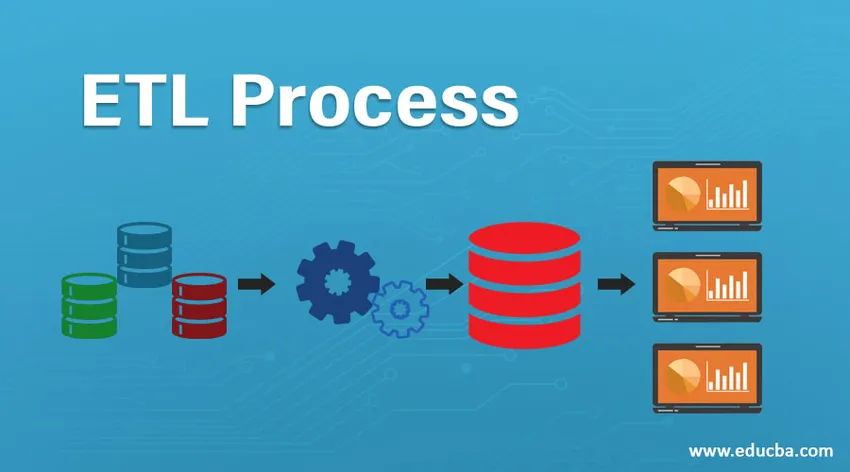
ETL odnosi się do procesu wyodrębniania, przekształcania i ładowania. Jest to rodzaj kroku integracji danych, w którym dane pochodzące z różnych źródeł są pobierane i wysyłane do hurtowni danych. Dane są pobierane z różnych zasobów, a następnie przekształcane w celu przekształcenia ich w określony format zgodnie z wymaganiami biznesowymi. Różne narzędzia pomagające w wykonywaniu tych zadań to:
- IBM DataStage
- Abinitio
- Informatica
- Żywy obraz
- Talend
Proces ETL
Jak to działa?
Proces ETL jest 3-etapowym procesem, który rozpoczyna się od wyodrębnienia danych z różnych źródeł danych, a następnie surowe dane przechodzą różne transformacje, dzięki czemu nadają się do przechowywania w hurtowni danych i ładowania ich do hurtowni danych w wymaganym formacie i przygotowania do analiza.
Krok 1: Wyodrębnij
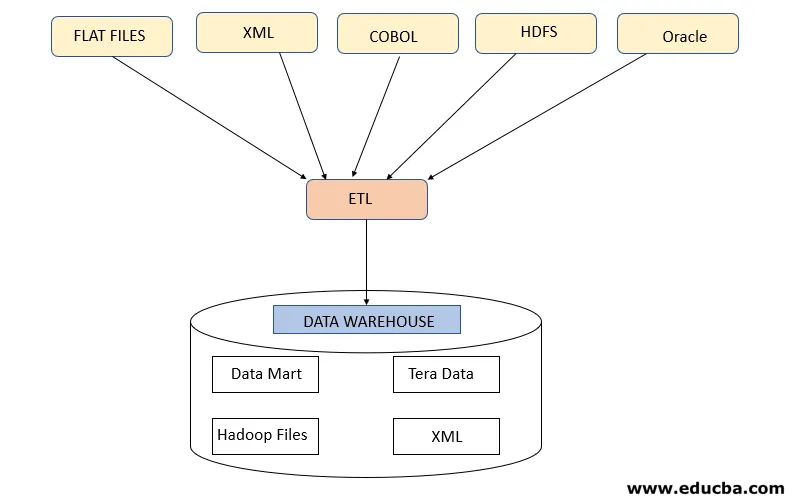
Ten krok odnosi się do pobrania wymaganych danych z różnych źródeł, które są obecne w różnych formatach, takich jak XML, pliki Hadoop, pliki płaskie, JSON itp. Wyodrębnione dane są przechowywane w obszarze przejściowym, w którym wykonywane są dalsze transformacje. Dlatego dane są dokładnie sprawdzane przed przeniesieniem ich do hurtowni danych, w przeciwnym razie przywrócenie zmian w hurtowniach stanie się wyzwaniem.
Wymagana jest odpowiednia mapa danych między źródłem a celem przed wydobyciem danych, ponieważ proces ETL musi współdziałać z różnymi systemami, takimi jak Oracle, sprzęt, komputer mainframe, systemy czasu rzeczywistego, takie jak ATM, Hadoop itp. Podczas pobierania danych z tych systemów .
Uwaga - Należy jednak zadbać o to, aby systemy te pozostały nienaruszone podczas ekstrakcji.
Strategie ekstrakcji danych
- Pełna ekstrakcja: Następuje to, gdy do hurtowni danych ładowane są całe dane ze źródeł, które pokazują, że albo hurtownia danych jest zapełniana po raz pierwszy, albo nie opracowano żadnej strategii ekstrakcji danych.
- Częściowa ekstrakcja (z powiadomieniem o aktualizacji): Strategia ta znana jest również jako delta, w której wyodrębniane są tylko zmieniane dane i aktualizacja hurtowni danych
- Częściowa ekstrakcja (bez powiadomienia o aktualizacji): Strategia ta odnosi się do wydobywania określonych wymaganych danych ze źródeł zgodnie z obciążeniem w hurtowniach danych zamiast ekstrakcji całych danych.
Krok 2: Przekształć
Ten krok jest najważniejszym krokiem ETL. W tym kroku wykonuje się wiele transformacji, aby przygotować dane do załadowania w hurtowniach danych, stosując poniższe transformacje:
A. Podstawowe transformacje: transformacje te są stosowane w każdym scenariuszu, ponieważ są one podstawową potrzebą podczas ładowania danych wyodrębnionych z różnych źródeł w hurtowniach danych
- Czyszczenie lub wzbogacanie danych: Odnosi się do czyszczenia niepożądanych danych z obszaru przemieszczania, aby nieprawidłowe dane nie były ładowane z hurtowni danych.
- Filtrowanie: Tutaj odfiltrowujemy wymagane dane z dużej ilości danych obecnych zgodnie z wymaganiami biznesowymi. Na przykład do generowania raportów sprzedaży potrzebne są tylko rekordy sprzedaży dla tego konkretnego roku.
- Konsolidacja: Wyodrębnione dane są konsolidowane w wymaganym formacie przed załadowaniem ich do hurtowni danych. 4.
- Standaryzacje: Pola danych są przekształcane, aby uzyskać ten sam wymagany format, np. Pole danych musi być określone jako MM / DD / RRRR.
B. Zaawansowane transformacje: Te typy transformacji są specyficzne dla wymagań biznesowych.
- Łączenie: w tej operacji dane z 2 lub więcej źródeł są łączone t generują dane tylko z pożądanymi kolumnami z wierszami, które są ze sobą powiązane
- Sprawdzanie poprawności progu danych: Wartości obecne w różnych polach są sprawdzane, jeśli są poprawne lub nie, takie jak numer konta bankowego o wartości null w przypadku danych banku.
- Użyj odnośników do scalenia danych: Różne płaskie pliki lub inne pliki są używane do wyodrębnienia określonych informacji poprzez wykonanie operacji wyszukiwania na tym.
- Korzystanie z dowolnej złożonej walidacji danych: Wiele złożonych walidacji stosuje się w celu wyodrębnienia prawidłowych danych tylko z systemów źródłowych.
- Wartości obliczone i pochodne: W celu przekształcenia danych w niektóre wymagane informacje stosuje się różne obliczenia
- Duplikacja: zduplikowane dane pochodzące z systemów źródłowych są analizowane i usuwane przed załadowaniem ich do hurtowni danych.
- Restrukturyzacja kluczy: W przypadku przechwytywania wolno zmieniających się danych należy wygenerować różne klucze zastępcze w celu uporządkowania danych w wymaganym formacie.
Uwaga - MPP-Massive Parallel Processing jest czasem używane do wykonywania niektórych podstawowych operacji, takich jak filtrowanie lub czyszczenie danych w obszarze przemieszczania w celu szybszego przetworzenia dużej ilości danych.
Krok 3: Załaduj
Ten krok dotyczy ładowania przekształconych danych do hurtowni danych, skąd można je wykorzystać do wygenerowania wielu decyzji analitycznych, a także do raportowania.
1. Ładowanie początkowe: ten rodzaj ładowania występuje podczas ładowania danych w hurtowniach danych po raz pierwszy.
2. Obciążenie przyrostowe: jest to rodzaj obciążenia, które jest wykonywane w celu okresowej aktualizacji hurtowni danych o zmiany zachodzące w źródłowych danych systemowych.
3. Pełne odświeżanie: Ten rodzaj ładowania odnosi się do sytuacji, gdy pełne dane z tabeli zostaną usunięte i załadowane świeżymi danymi.
Hurtownia danych zezwala na funkcje OLAP lub OLTP.
Wady procesu ETL
- Zwiększanie ilości danych - narzędzie ETL pobiera dane z różnych źródeł i przekazuje je do hurtowni danych. Dlatego wraz ze wzrostem ilości danych praca z narzędziem ETL i hurtowniami danych staje się uciążliwa.
- Dostosowanie - dotyczy szybkich i skutecznych rozwiązań lub odpowiedzi na dane generowane przez systemy źródłowe. Ale użycie narzędzia ETL spowalnia ten proces.
- Drogie - Używanie hurtowni danych do przechowywania coraz większej ilości danych generowanych okresowo to wysoki koszt, który organizacja musi ponieść.
Wniosek - proces ETL
Narzędzie ETL składa się z procesów wyodrębniania, przekształcania i ładowania, w których pomaga generować informacje z danych zebranych z różnych systemów źródłowych. Dane z systemu źródłowego mogą mieć dowolne formaty i mogą być ładowane w dowolnych formatach do hurtowni danych, dlatego narzędzie ETL musi obsługiwać łączność ze wszystkimi typami tych formatów.
Polecane artykuły
To jest przewodnik po procesie ETL. Tutaj omawiamy wprowadzenie, jak to działa ?, narzędzia ETL i jego wady. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Informatica ETL Tools
- Narzędzia testowe ETL
- Co to jest ETL?
- Co to jest testowanie ETL?