

Co to jest Naiwny algorytm Bayesa?
Naiwny algorytm Bayesa to technika, która pomaga konstruować klasyfikatory. Klasyfikatory to modele, które klasyfikują wystąpienia problemów i nadają im etykiety klas reprezentowane jako wektory predyktorów lub wartości cech. Opiera się na twierdzeniu Bayesa. Nazywa się to naiwnym Bayesem, ponieważ zakłada, że wartość cechy jest niezależna od drugiej cechy, tj. Zmiana wartości cechy nie wpłynie na wartość innej cechy. Jest również nazywany idiotą Bayes z tego samego powodu. Ten algorytm działa skutecznie w przypadku dużych zestawów danych, dlatego najlepiej nadaje się do prognozowania w czasie rzeczywistym.
Pomaga obliczyć prawdopodobieństwo tylne P (c | x) z wykorzystaniem wcześniejszego prawdopodobieństwa klasy P (c), wcześniejszego prawdopodobieństwa predyktora P (x) i prawdopodobieństwa predyktora danej klasy, zwanego również prawdopodobieństwem P (x | c ).
Wzór lub równanie do obliczenia prawdopodobieństwa a posteriori to:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Jak działa Naiwny algorytm Bayesa?
Pozwól nam zrozumieć działanie Naiwnego algorytmu Bayesa na przykładzie. Zakładamy zestaw danych treningowych pogody i zmienną docelową „Idziemy na zakupy”. Teraz sklasyfikujemy, czy dziewczyna pójdzie na zakupy na podstawie warunków pogodowych.
Podany zestaw danych to:
| Pogoda | Iść na zakupy |
| Słoneczny | Nie |
| Deszczowy | tak |
| Pochmurny | tak |
| Słoneczny | tak |
| Pochmurny | tak |
| Deszczowy | Nie |
| Słoneczny | tak |
| Słoneczny | tak |
| Deszczowy | Nie |
| Deszczowy | tak |
| Pochmurny | tak |
| Deszczowy | Nie |
| Pochmurny | tak |
| Słoneczny | Nie |
Zostaną wykonane następujące kroki:
Krok 1: Utwórz tabele częstotliwości przy użyciu zestawów danych.
| Pogoda | tak | Nie |
| Słoneczny | 3) | 2) |
| Pochmurny | 4 | 0 |
| Deszczowy | 2) | 3) |
| Całkowity | 9 | 5 |
Krok 2: Zrób tabelę prawdopodobieństwa, obliczając prawdopodobieństwo każdego stanu pogodowego i robiąc zakupy.
| Pogoda | tak | Nie | Prawdopodobieństwo |
| Słoneczny | 3) | 2) | 5/14 = 0, 36 |
| Pochmurny | 4 | 0 | 4/14 = 0, 29 |
| Deszczowy | 2) | 3) | 5/14 = 0, 36 |
| Całkowity | 9 | 5 | |
| Prawdopodobieństwo | 9/14 = 0, 64 | 5/14 = 0, 36 |
Krok 3: Teraz musimy obliczyć prawdopodobieństwo tylne za pomocą równania Naive Bayesa dla każdej klasy.
Przykład problemu: dziewczyna będzie chodzić na zakupy, jeśli będzie pochmurno. Czy to stwierdzenie jest prawidłowe?
Rozwiązanie:
- P (Tak | Pochmurno) = (P (Pochmurno | Tak) * P (Tak)) / P (Pochmurno)
- P (Zachmurzenie | Tak) = 4/9 = 0, 44
- P (Tak) = 9/14 = 0, 64
- P (pochmurno) = 4/14 = 0, 39
Teraz umieść wszystkie obliczone wartości w powyższym wzorze
- P (Tak | Zachmurzenie) = (0, 44 * 0, 64) / 0, 39
- P (Tak | Zachmurzenie) = 0, 722
Klasa o najwyższym prawdopodobieństwie byłaby wynikiem prognozy. Stosując to samo podejście, można przewidzieć prawdopodobieństwo różnych klas.
W jakim celu stosuje się Naiwny algorytm Bayesa?
1. Prognozowanie w czasie rzeczywistym: Naiwny algorytm Bayesa jest szybki i zawsze gotowy do nauki, dlatego najlepiej nadaje się do prognozowania w czasie rzeczywistym.
2. Przewidywanie wielu klas: prawdopodobieństwo wystąpienia wielu klas dowolnej zmiennej docelowej można przewidzieć za pomocą algorytmu Naive Bayesa.
3. System rekomendacji: Naiwny klasyfikator Bayesa przy pomocy Collaborative Filtering tworzy system rekomendacji. System wykorzystuje techniki eksploracji danych i uczenia maszynowego do filtrowania informacji, które nie były wcześniej widoczne, a następnie przewidywania, czy użytkownik doceni dany zasób, czy nie.
4. Klasyfikacja tekstu / Analiza sentymentów / Filtrowanie spamu: Ze względu na lepszą wydajność w przypadku problemów wieloklasowych i zasadę niezależności algorytm Naive Bayes działa lepiej lub ma wyższy wskaźnik skuteczności w klasyfikacji tekstu, dlatego jest stosowany w analizie sentymentów i Filtrowanie spamu
Zalety naiwnego algorytmu Bayesa
- Łatwy do wdrożenia.
- Szybki
- Jeśli założenie o niezależności się utrzymuje, działa ono wydajniej niż inne algorytmy.
- Wymaga mniej danych treningowych.
- Jest wysoce skalowalny.
- Może dokonywać prognoz probabilistycznych.
- Może obsługiwać zarówno dane ciągłe, jak i dyskretne.
- Niewrażliwy na nieistotne cechy.
- Może łatwo pracować z brakującymi wartościami.
- Łatwa aktualizacja po przybyciu nowych danych.
- Najlepiej nadaje się do problemów z klasyfikacją tekstu.
Wady algorytmu Naive Bayesa
- Mocne założenie, że funkcje są niezależne, co nie jest prawdą w rzeczywistych zastosowaniach.
- Niedobór danych
- Szanse na utratę dokładności.
- Częstotliwość zerowa, tj. Jeśli kategoria dowolnej zmiennej kategorialnej nie jest widoczna w zbiorze danych treningowych, wówczas model przypisuje zerowe prawdopodobieństwo tej kategorii, a następnie nie można dokonać prognozy.
Jak zbudować podstawowy model przy użyciu Naiwnego algorytmu Bayesa
Istnieją trzy rodzaje modeli Naive Bayesa, tj. Gaussa, Wielomian i Bernoulli. Porozmawiajmy krótko o każdym z nich.
1. Gaussowski: Gaussowski Naiwny algorytm Bayesa zakłada, że ciągłe wartości odpowiadające każdej funkcji są rozkładane zgodnie z rozkładem Gaussa zwanym również rozkładem normalnym.
Zakłada się, że prawdopodobieństwo lub wcześniejsze prawdopodobieństwo predyktora danej klasy jest gaussowskie, dlatego prawdopodobieństwo warunkowe można obliczyć jako:
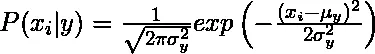
2. Wielomian: Częstotliwości występowania niektórych zdarzeń reprezentowanych przez wektory cech są generowane przy użyciu rozkładu wielomianowego. Ten model jest szeroko stosowany do klasyfikacji dokumentów.
3. Bernoulli: W tym modelu dane wejściowe są opisane przez cechy, które są niezależnymi zmiennymi binarnymi lub wartościami logicznymi. Jest to również szeroko stosowane w klasyfikacji dokumentów, takich jak Multinomial Naive Bayes.
Możesz użyć dowolnego z powyższych modeli zgodnie z wymaganiami, aby obsłużyć i sklasyfikować zestaw danych.
Możesz zbudować model Gaussa za pomocą Pythona, rozumiejąc przykład podany poniżej:
Kod:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Wynik:
((3, 4))
Wniosek
W tym artykule szczegółowo poznaliśmy pojęcia naiwnego algorytmu Bayesa. Najczęściej stosuje się go w klasyfikacji tekstowej. Jest łatwy do wdrożenia i szybki do wykonania. Jego główną wadą jest to, że wymaga, aby funkcje były niezależne, co nie jest prawdą w rzeczywistych zastosowaniach.
Polecane artykuły
To był przewodnik po Naive Bayes Algorithm. Tutaj omówiliśmy Podstawową koncepcję, działanie, zalety i wady algorytmu Naive Bayesa. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Algorytm wspomagający
- Algorytm w programowaniu
- Wprowadzenie do algorytmu