

Wprowadzenie do poleceń Pig
Apache Pig narzędzie / platforma używana do analizy dużych zbiorów danych i wykonywania długich serii operacji na danych. Świnia jest używana z Hadoop. Wszystkie skrypty świni wewnętrznie są konwertowane na zadania zmniejszania mapy, a następnie wykonywane. Może obsługiwać dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane. Sklepy ze świniami, ich wynik w HDFS. W tym artykule poznajemy więcej rodzajów poleceń świni.
Oto niektóre cechy Pig:
- Samooptymalizacja: Pig może zoptymalizować zadania wykonawcze, użytkownik ma swobodę skupienia się na semantyce.
- Łatwość programowania: Pig zapewnia język / dialekt wysokiego poziomu znany jako Pig Latin, który jest łatwy do napisania. Pig Latin udostępnia wielu operatorów, których programiści mogą używać do przetwarzania danych. Programista ma również swobodę pisania własnych funkcji.
- Rozszerzalność: Pig ułatwia tworzenie funkcji niestandardowych, zwanych UDF (funkcje zdefiniowane przez użytkownika), które sprawiają, że programiści są w stanie szybko i łatwo spełnić wszelkie wymagania przetwarzania. Skrypt świni działa na powłoce znanej jako chrząknięcie.
Dlaczego polecenia świni?
Programiści, którzy nie są dobrzy w Javie, zwykle mają problemy z pisaniem programów w Hadoop, tj. Pisaniem zadań zmniejszania mapy. Dla nich Pig Latin, który jest podobny do języka SQL, jest dobrodziejstwem. Podejście oparte na wielu zapytaniach zmniejsza długość kodu.
Ogólnie rzecz biorąc, jego zwięzły i skuteczny sposób programowania. Polecenia Pig mogą wywoływać kod w wielu językach, takich jak JRuby, Jython i Java.
Architektura poleceń świni
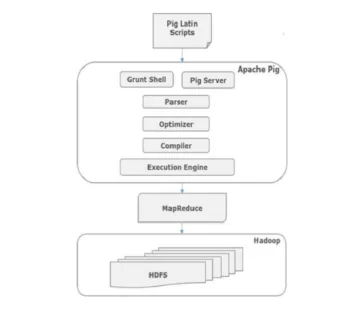
Wszystkie skrypty napisane w Pig-Latin w powłoce gruntowej przechodzą do analizatora składni w celu sprawdzenia składni i zachodzą również inne kontrole. Dane wyjściowe analizatora składni to DAG. Ta DAG jest następnie przekazywana do Optymalizatora, który następnie wykonuje logiczną optymalizację, taką jak projekcja i przesuwa w dół. Następnie kompilator jest zgodny z logicznym planem zadań MapReduce. Na koniec zadania MapReduce są przesyłane do Hadoop w posortowanej kolejności. Zadania te są wykonywane i dają pożądane wyniki.
Model danych Pig-Latin jest w pełni zagnieżdżony i pozwala na tworzenie złożonych typów danych, takich jak mapa i krotka.
Każda pojedyncza wartość języka Pig Latin (niezależnie od typu danych) jest znana jako Atom.
Podstawowe polecenia świni
Rzućmy okiem na niektóre z podstawowych poleceń Pig, które są podane poniżej: -
1. Fs: wyświetli wszystkie pliki w HDFS
grunt> fs –ls
2. Wyczyść: Spowoduje to wyczyszczenie interaktywnej powłoki Grunt.
chrząknięcie> wyczyść
3. Historia:
To polecenie pokazuje dotychczasowe polecenia.
chrząkać> historia
4. Odczytywanie danych: Zakładając, że dane znajdują się w HDFS i musimy odczytać dane do Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
UŻYWANIE PigStorage (', ')
as (id: int, imię: chararray, nazwisko: chararray, telefon: chararray,
miasto: chararray);
PigStorage () to funkcja ładująca i przechowująca dane jako ustrukturyzowane pliki tekstowe.
5. Przechowywanie danych: Operator sklepu służy do przechowywania przetworzonych / załadowanych danych.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Tutaj „/ pig_Output /” to katalog, w którym należy zapisać relację.
6. Zrzut operatora: To polecenie służy do wyświetlania wyników na ekranie. Zwykle pomaga w debugowaniu.
chrząkać> Zrzucić college_students;
7. Opisz operatora: Pomaga programiście zobaczyć schemat relacji.
chrząkać> opisać college_students;
8. Wyjaśnij: To polecenie pomaga przejrzeć plany wykonania logiczne, fizyczne i zmniejszające mapę.
chrząknięcie> wyjaśnij studentom college'u;
9. Zilustruj operator: Daje to krok po kroku wykonywanie instrukcji w poleceniach Pig.
chrząknięcie> ilustrują studentów uczelni;
Pośrednie polecenia świni
1. Grupa: To polecenie Świni działa w kierunku grupowania danych za pomocą tego samego klucza.
grunt> group_data = GROUP college_students według imienia;
2. KOGROUP: Działa podobnie do operatora grupy. Główną różnicą między operatorem grupy i grupy jest to, że operator grupy jest zwykle używany z jedną relacją, podczas gdy grupa jest używana z więcej niż jedną relacją.
3. Połącz: Służy do łączenia dwóch lub więcej relacji.
Przykład: Aby wykonać samozłączenie, powiedzmy, że relacja „klient” jest ładowana z poleceń HDFS tp pig w dwóch relacjach klient1 i klient2.
chrząknięcie> klienci3 = DOŁĄCZ klienci1 BY id, klienci2 BY id;
Dołączenie może być samo-przyłączeniem, złączeniem wewnętrznym, złączeniem zewnętrznym.
4. Krzyż: To polecenie świni oblicza iloczyn krzyżowy dwóch lub więcej relacji.
grunt> cross_data = CROSS klienci, zamówienia;
5. Unia: Łączy dwa relacje. Warunkiem scalenia jest to, że kolumny i domeny relacji muszą być identyczne.
chrząknięcie> student = UNION student1, student2;
Zaawansowane polecenia świni
Rzućmy okiem na niektóre z zaawansowanych poleceń Pig, które są podane poniżej:
1. Filtr: Pomaga to w odfiltrowaniu krotek poza relacją, w oparciu o określone warunki.
filter_data = FILTR college_students WG miasta == 'Chennai';
2. Wyraźny: Pomaga w usuwaniu zbędnych krotek z relacji.
grunt> wyraźna_dana = DISTINCT college_students;
To filtrowanie spowoduje utworzenie nowej nazwy relacji „odrębna_data”
3. Foreach: Pomaga w generowaniu transformacji danych na podstawie danych kolumnowych.
grunt> foreach_data = FOREACH student_details GENERUJ identyfikator, wiek, miasto;
Spowoduje to pobranie wartości identyfikatora, wieku i miasta każdego ucznia z relacji student_details, a zatem zapisze go w innej relacji o nazwie foreach_data.
4. Sortuj według: To polecenie wyświetla wynik w posortowanej kolejności na podstawie jednego lub więcej pól.
grunt> order_by_data = ZAMÓW college_students Według wieku DESC;
To posortuje relację „college_students” w porządku malejącym według wieku.
5. Limit: To polecenie jest ograniczone nie. krotek z relacji.
grunt> limit_data = LIMIT student_details 4;
Porady i wskazówki
Poniżej znajdują się różne wskazówki i triki poleceń Pig: -
1. Włącz kompresję na wejściu i wyjściu:
ustaw input.compression.enabled true;
ustaw output.compression.enabled true;
Wyżej wymienione wiersze kodu muszą znajdować się na początku skryptu, aby umożliwić Pig Commands odczytanie skompresowanych plików lub wygenerowanie skompresowanych plików jako danych wyjściowych.
2. Dołącz do wielu relacji:
Aby wykonać lewe łączenie powiedzmy trzy relacje (input1, input2, input3), należy wybrać SQL. Jest tak, ponieważ łączenie zewnętrzne nie jest obsługiwane przez Pig na więcej niż dwóch stołach.
Zamiast tego wykonaj czynności w lewo, aby dołączyć w dwóch krokach:
data1 = JOIN input1 BY key LEFT, input2 BY key;
data2 = DOŁĄCZ dane1 BY input1 :: klawisz LEWY, input3 BY klawisz;
Oznacza to dwa zadania zmniejszające mapę.
Aby efektywniej wykonać powyższe zadanie, można wybrać „Grupę roboczą”. Grupa dyskusyjna może dołączyć do wielu relacji. Grupa dyskusyjna domyślnie łączy się zewnętrznie.
Wniosek
Świnia jest językiem proceduralnym, powszechnie stosowanym przez naukowców zajmujących się przetwarzaniem danych i szybkim prototypowaniem. To świetne narzędzie ETL i do przetwarzania dużych danych. Skrypty świni mogą być wywoływane przez inne języki i odwrotnie. Stąd polecenia Pig można wykorzystywać do budowania większych i złożonych aplikacji.
Polecane artykuły
To był przewodnik po poleceniach Pig. Omówiliśmy tutaj zarówno podstawowe, jak i zaawansowane polecenia Pig oraz niektóre bezpośrednie polecenia Pig. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Polecenia Adobe Photoshop
- Polecenia Tableau
- Ściągawka SQL (polecenia, darmowe porady i triki)
- VBA Polecenia wykańczające
- Różne operacje związane z krotkami