

Co to jest Big Data i Hadoop?
Dane rosną wykładniczo każdego dnia i przy tak rosnących danych pojawia się potrzeba ich wykorzystania. Tak jak w dawnych czasach mieliśmy dyskietki do przechowywania danych, transfer danych był również powolny, ale obecnie są one niewystarczające, a pamięć w chmurze jest używana, ponieważ mamy terabajty danych. W dzisiejszym świecie media społecznościowe mają największy udział we wzroście danych. Składa się z zachowania ludzi, sposobu myślenia i kilku innych aspektów. Mówi się, że w każdej minucie na YouTube przesyłanych jest 300 godzin filmów, ponad 20 milionów zdjęć na Facebooku i wiele innych. Co więcej, nie ma odpowiedniej struktury przesyłanych danych, co stanowi największe wyzwanie dla przetwarzania tych danych.
Ponieważ z dużą prędkością generowane są ogromne dane, tradycyjne systemy RDBMS nie były w stanie poradzić sobie z tak szybkim wzrostem. Ponadto nie są one również w stanie obsługiwać nieustrukturyzowanych danych. Bardzo trudno było poradzić sobie z tak ogromną ilością heterogenicznych danych szybko rosnących i przetwarzać je z dużą prędkością przetwarzania. Tak więc pojawiła się potrzeba takiego systemu, który byłby w stanie efektywnie obsługiwać duży zestaw danych. Stąd, aby rozwiązać scenariusz, powstał Hadoop. HDFS jest komponentem Hadoop, który rozwiązał problem przechowywania dużego zbioru danych za pomocą pamięci rozproszonej, podczas gdy YARN jest komponentem, który rozwiązał problem przetwarzania drastycznie skracając czas przetwarzania.
Hadoop to platforma oprogramowania typu open source do przechowywania i przetwarzania dużych zbiorów danych przy użyciu rozproszonego dużego klastra towarowego sprzętu. Został opracowany przez Douga Cuttinga i Michaela J. Cafarella i licencjonowany na podstawie Apache. Został napisany w Javie i został opracowany na podstawie papieru napisanego przez Google w systemie MapReduce i stosuje koncepcje programowania funkcjonalnego. Jest niezawodny, ekonomiczny, elastyczny i skalowalny.
Podstawowe składniki Hadoop
Podstawowe składniki Hadoop są następujące
-
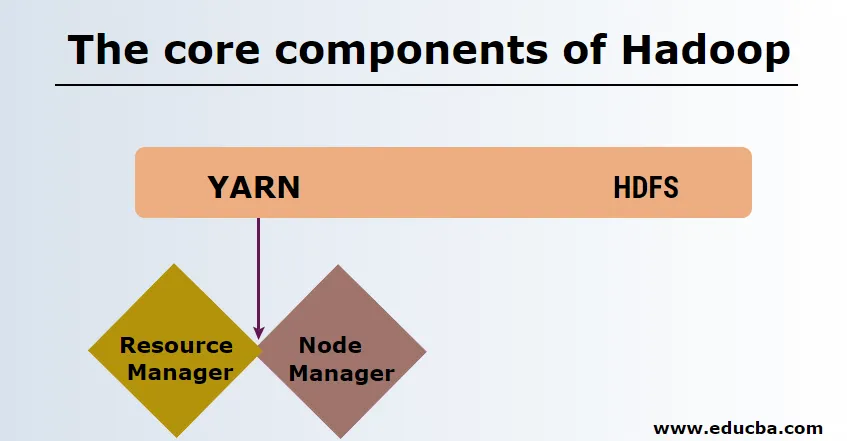
HDFS
HDFS lub rozproszony system plików Hadoop mają Namenode i węzeł danych. Namenode jest węzłem głównym, w którym działa główny demon, zarządza węzłami danych i śledzi wszystkie operacje. Kody danych to urządzenia podrzędne, w których dane są faktycznie przechowywane.
-
PRZĘDZA
YARN składa się z dwóch głównych elementów:
1. ResourceManager: Działa w węźle głównym i zarządza wszystkimi zasobami oraz planuje wszystkie aplikacje. Ma program do planowania i zarządzania aplikacjami.
2. NodeManager: Działa na każdym węźle podrzędnym i jest odpowiedzialny za zarządzanie kontenerami i monitorowanie wykorzystania zasobów.
Kilka składników Hadoop
Istnieje kilka składników Hadoop, takich jak świnia, ul, sqoop, flume, mahout, oozie, zookeeper, HBase itp.
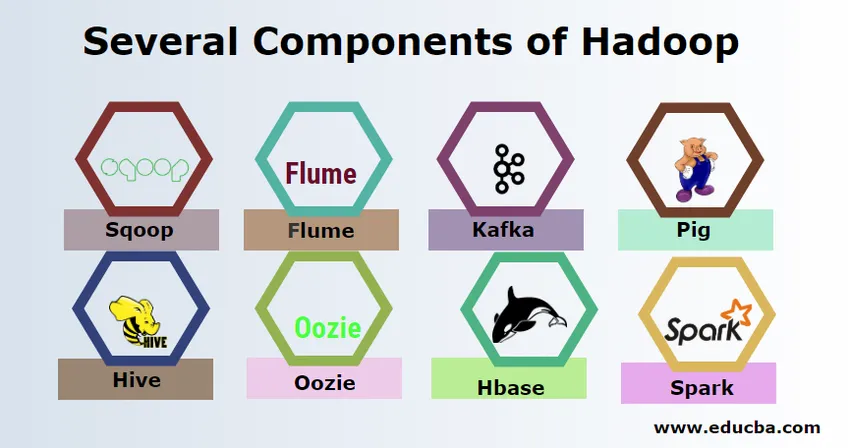
- Sqoop - służy do importowania i eksportowania danych z RDBMS do Hadoop i odwrotnie.
- Flume - służy do pobierania danych w czasie rzeczywistym do Hadoop.
- Kafka - Jest to system przesyłania wiadomości używany do kierowania danych w czasie rzeczywistym do Hadoop.
- Pig - służy jako język skryptowy do przetwarzania danych.
- Hive - jest to platforma hurtowni danych zbudowana na HDFS, aby użytkownicy znający SQL mogli wykonywać zapytania w celu uzyskania danych. Te zapytania nazywane są HiveQL.
- Oozie - służy do planowania przepływu pracy zadań do uruchomienia w określonych zdarzeniach lub czasie.
- Hbase - jest to baza danych bez SQL udostępniana jako część Apache Hadoop.
- Spark - służy do wykonywania przetwarzania w pamięci, które jest znacznie szybsze niż redukcja mapy Hadoop.
Dostawcy Hadoop
Istnieje wiele firm oferujących dystrybucje Hadoop. Poniżej znajduje się kilka najlepszych dostawców Hadoop:
- Cloudera
- Hortonworks
- MapR
Istnieje kilka warunków wstępnych do nauki Hadoop. Konieczne jest wcześniejsze doświadczenie w języku Java i języku skryptowym. Chociaż Hadoop ma już swoje własne języki programowania wysokiego poziomu, takie jak świnia i gałęzia, które generują kod zaplecza do dalszego przetwarzania, nadal można stworzyć własny program do zmniejszania map w dowolnym języku programowania, takim jak Ruby, Python, Perl, a nawet programowanie C.
Bigdata i Hadoop są bardzo poszukiwane na dzisiejszym rynku. To wzrośnie jeszcze bardziej w najbliższych dniach. Wiele organizacji przeniosło się już do Hadoop, a ci, którzy tego nie zrobią, wkrótce się przeprowadzą. Istnieje aktualny raport stwierdzający, że duże korporacje zaczęły inwestować w analizę dużych zbiorów danych. Prognozy marketingu dużych zbiorów danych są zawsze w trendzie wzrostowym i wcale nie są krótkotrwałe. Oprócz tych wszystkich miejsc pracy w Hadoop i Big Data zawsze oferuje się wysokie wynagrodzenie w porównaniu do innych technologii.
Najlepsze firmy Big Data i Hadoop
Poniżej znajduje się kilka najlepszych firm zatrudniających najwięcej zasobów Hadoop.
- Wieśniak
- Amazonka
- Royal Bank of Scotland
- Brytyjskie linie lotnicze
- Expedia
- Walmart
Wiele firm korzysta z aplikacji Big Data. To są:
-
Nokia
Do aplikacji używa komponentów Cloudera i Hadoop, takich jak HDFS, HBase, Sqoop, Scribe. Wykorzystał dane użytkownika skutecznie, aby zrozumieć i poprawić wrażenia użytkownika. Wykorzystuje przetwarzanie danych i złożone analizy do budowy mapy z przewidywalnym ruchem i modelami warstwowymi.
-
SAS
Współpracował z Hadoop, aby pomóc naukowcom danych uzyskać lepszy wgląd w środowisko, które zapewnia wizualne i interaktywne wrażenia, pomagając w ten sposób odkrywać nowe trendy. Programy analityczne wydobywają znaczące informacje z danych, a technologia w pamięci pomaga w szybszym dostępie do danych.
Istnieje również wiele innych firm korzystających z platform big data do różnych analiz. Są to analizy danych lotniczych czarnej skrzynki w przemyśle lotniczym, różne analizy rynku akcji itp.
Zalety Haddop
Poniżej kilka zalet Hadoop
- Skalowalny - w przeciwieństwie do tradycyjnego RDBMS, jest to wysoce skalowalna platforma, ponieważ może przechowywać duże zestawy danych w rozproszonych klastrach na sprzęcie towarowym działającym równolegle.
- Opłacalność - koszt był zbyt wysoki, aby RDBMS mógł przechowywać dane, które zostały zwolnione w Hadoop.
- Szybki i elastyczny - umożliwia szybki dostęp do danych w rozproszonym systemie plików. Oferuje także uzyskiwanie informacji biznesowych z częściowo ustrukturyzowanych i nieustrukturyzowanych danych.
- Odporny na awarie - Za każdym razem, gdy jakiekolwiek dane są wysyłane do węzła, te same dane są replikowane do innych węzłów, do których można uzyskać dostęp w przypadku awarii pierwszego węzła.
Wniosek - co to jest Big Data i Hadoop
Dane stale rosną i dlatego zawsze będzie potrzeba dużych zbiorów danych i Hadoop, aby nadać im sens. Z tego powodu specjaliści posiadający umiejętności Hadoop zawsze znajdą w najbliższych dniach duże możliwości i mogą być istotnym atutem dla organizacji rozwijającej działalność i karierę.
Polecane artykuły
To był przewodnik po tym, co to jest Big Data i Hadoop. Tutaj omówiliśmy podstawowe pojęcia i komponenty Big Data i Hadoop. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Przykłady analizy dużych zbiorów danych
- Zastosowania Hadoop
- Przewodnik po wizualizacji danych
- Co to jest analityka Big Data?