
Różnice między HashMap i TreeMap
HashMap jest częścią kolekcji Java. Zapewnia podstawową implementację interfejsu Java Map Interface. Dane są przechowywane w parach (klucz, wartość). Musisz znać jego klucz, aby uzyskać dostęp do wartości. HashMap jest znany jako HashMap, ponieważ wykorzystuje technikę Hashing. TreeMap służy do implementacji interfejsu mapy i NavigableMap z klasą abstrakcyjną. Mapa jest sortowana według naturalnej kolejności jej kluczy lub według komparatora podanego podczas tworzenia mapy, w zależności od tego, z jakiego konstruktora jest używany.
Podobieństwa między HashMap i TreeMap
Oprócz różnic istnieją następujące podobieństwa między mapą skrótów i mapą mapy:
- Zarówno klasy HashMap, jak i TreeMap implementują interfejsy Serializable i Cloneable.
- Zarówno HashMap, jak i TreeMap rozszerzają klasę AbstractMap.
- Zarówno klasy HashMap, jak i TreeMap działają na parach klucz-wartość.
- Zarówno HashMap, jak i TreeMap są niezsynchronizowanymi kolekcjami.
- Zarówno HashMap, jak i TreeMap nie działają w szybkich kolekcjach.
Obie implementacje są częścią struktury kolekcji i przechowują dane w parach klucz-wartość.
Program Java przedstawiający HashMap i TreeMap
Oto program Java, który pokazuje, w jaki sposób elementy są umieszczane i pobierane z mapy skrótów:
package com.edubca.map;
import java.util.*;
class HashMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
HashMap hashmap =
new HashMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = hashmap.get(arr(i));
// If first occurrence of the element
if (hashmap.get(arr(i)) == null)
hashmap.put(arr(i), 1);
// If elements already present in hash map
else
hashmap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m:hashmap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test the above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Wynik:
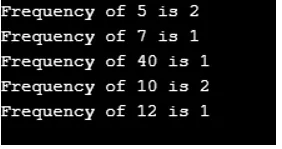
Z danych wyjściowych jasno wynika, że hashmap nie utrzymuje żadnej kolejności. Oto program Java, który pokazuje, w jaki sposób elementy są umieszczane i pobierane z mapy.
Kod:
package com.edubca.map;
import java.util.*;
class TreeMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
TreeMap treemap =
new TreeMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = treemap.get(arr(i));
// If first occurrence of element
if (treemap.get(arr(i)) == null)
treemap.put(arr(i), 1);
// If elements already present in hash map
else
treemap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m: treemap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Wynik:
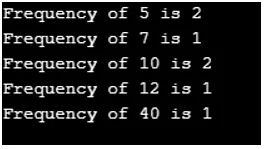
Z wyników wynika, że klucze są sortowane w naturalnej kolejności. W związku z tym mapa strony utrzymuje posortowany porządek.
Różnice między HashMap i TreeMap (infografiki)
Poniżej podano najważniejsze różnice między HashMap i TreeMap

Kluczowa różnica między HashMap a TreeMap
Oto punkty Kluczowej różnicy HashMap i TreeMap:
1. Struktura i wdrożenie
Hash Map to implementacja oparta na tabeli mieszającej. Rozszerza klasę mapy abstrakcyjnej i implementuje interfejs mapy. Mapa Hash działa na zasadzie mieszania. Implementacja mapy działa jak zbiorcza tabela skrótów, ale gdy kubełki stają się zbyt duże, są konwertowane na węzły drzewa, z których każdy ma podobną strukturę do węzłów TreeMap. TreeMap rozszerza klasę Mapy Abstrakcyjnej i implementuje interfejs Mapy Nawigowalnej. Podstawową strukturą danych dla mapy drzew jest drzewo czerwono-czarne.
2. Kolejność iteracji
Kolejność iteracji Hash Map jest niezdefiniowana, podczas gdy elementy TreeMap są uporządkowane w naturalnej kolejności lub w niestandardowej kolejności określonej za pomocą komparatora.
3. Wydajność
Ponieważ Hashmap jest implementacją opartą na haszowaniu, zapewnia stałą wydajność równą O (1) dla większości typowych operacji. Czas potrzebny do przeszukania elementu na mapie skrótu wynosi O (1). Ale jeśli w haszapie jest niewłaściwa implementacja, może to prowadzić do dodatkowego obciążenia pamięci i obniżenia wydajności. Z drugiej strony TreeMap zapewnia wydajność O (log (n)). Ponieważ mapa skrótów jest oparta na haszowaniu, wymaga ciągłego zakresu pamięci, podczas gdy mapa tremap wykorzystuje tylko ilość pamięci wymaganą do przechowywania elementów. Dlatego HashMap jest bardziej wydajny czasowo niż mapa, ale mapa jest bardziej przestrzenna niż HashMap.
4. Obsługa zerowa
HashMap zezwala na prawie jeden klucz zerowy i wiele wartości zerowych, podczas gdy w treemapie, null nie może być użyty jako klucz, chociaż dozwolone są wartości null. Jeśli null jest używany jako klucz w haszapie, wygeneruje wyjątek wskaźnika zerowego, ponieważ wewnętrznie używa metody porównywania lub porównywania do sortowania elementów.
Porównanie tabeli
Oto tabela porównawcza pokazująca różnice między mapą skrótów i mapą mapy:
| Podstawa porównania | HashMap | TreeMap |
| Składnia | Klasa publiczna HashMap rozszerza AbstractMap implementuje Map, Cloneable, Serializable | TreeMap klasy publicznej rozszerza AbstractMap implementujeNavigableMap, Cloneable, Serializable |
| Zamawianie | HashMap nie zapewnia żadnego zamówienia na elementy. | Elementy są zamawiane w kolejności naturalnej lub niestandardowej. |
| Prędkość | Szybki | Powolny |
| Null Keys and Values | Umożliwia prawie jeden klucz jako wartość zerową i wiele wartości zerowych. | Nie dopuszcza wartości null jako klucza, ale dopuszcza wiele wartości null. |
| Zużycie pamięci | HashMap zużywa więcej pamięci z powodu podstawowej tabeli skrótów. | Zużywa mniej pamięci w porównaniu do HashMap. |
| Funkcjonalność | Zapewnia tylko podstawowe funkcje | Zapewnia bogatsze funkcje. |
| Zastosowana metoda porównania | Zasadniczo używa metody equals () do porównywania kluczy. | Do porównywania kluczy używa metody Compare () lub CompareTo (). |
| Interfejs zaimplementowany | Mapa, szeregowalny i klonowalny | Nawigowalna mapa, szeregowalna i klonowalna |
| Występ | Podaje wydajność O (1). | Zapewnia wydajność O (log n) |
| Struktura danych | Używa tabeli skrótów jako struktury danych. | Wykorzystuje czerwono-czarne drzewo do przechowywania danych. |
| Elementy jednorodne i heterogeniczne | Pozwala na elementy jednorodne i niejednorodne, ponieważ nie wykonuje żadnego sortowania. | Pozwala to tylko na jednorodne elementy podczas sortowania. |
| Przypadków użycia | Używane, gdy nie potrzebujemy par klucz-wartość w posortowanej kolejności. | Używane, gdy należy sortować pary klucz-wartość mapy. |
Wniosek
Z artykułu wynika, że hashap to ogólna implementacja interfejsu Map. Zapewnia wydajność O (1), podczas gdy mapa mapy zapewnia wydajność O (log (n)). Dlatego HashMap jest zwykle szybszy niż TreeMap.
Polecane artykuły
To jest przewodnik po HashMap vs TreeMap. Tutaj omawiamy wprowadzenie do HashMap vs TreeMap, różnice między Hashmap i Treemap oraz tabelę porównawczą. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- WebLogic vs JBoss
- Lista kontra zestaw
- Git Fetch vs Git Pull
- Kafka vs Spark | Najważniejsze różnice
- Top 5 różnic między Kafką a Kinezą