
Wprowadzenie do Data Lake vs. Data Warehouse
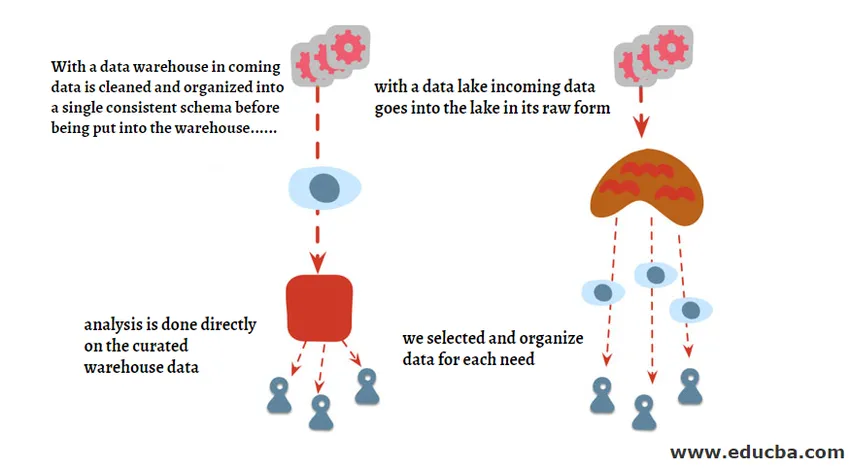
Data Lake vs Data Warehouse to terminy, które są używane zamiennie, ale między tymi warunkami występują różnice. Przedstawiliśmy poniższy schemat, aby zrozumieć różnicę wysokiego poziomu między tymi dwoma i już wkrótce zajmiemy się szczegółowo każdym z nich.
Co to jest Data Lake?
Data Lake to rodzaj repozytorium pamięci, które składa się tylko z surowych danych, które mają postać ustrukturyzowanego, częściowo ustrukturyzowanego i nieustrukturyzowanego formatu. Jezioro danych jest najczęściej używane przez Data Scientists i Machine Learning Engineers, ponieważ pomaga im odpowiedzieć na pytania, na które jeszcze nie ma odpowiedzi, lub może stworzyć pytanie, które nie jest jeszcze znane. Zawiera ogromną pulę danych o różnych typach, a gdy są zintegrowane, okazują się bardzo przydatne w zakresie modelowania predykcyjnego, które jest najczęściej wykorzystywane do budowy modeli uczenia maszynowego.
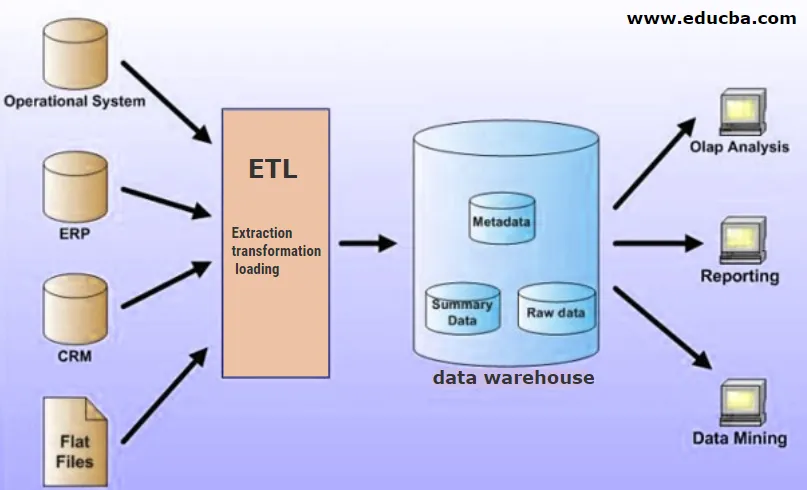
Co to jest hurtownia danych?
Hurtownia danych to scentralizowana lokalizacja do przechowywania transformowanych danych, które są przekształcane w ustrukturyzowany format przed zapisaniem ich w hurtowni danych. Hurtownia danych może zawierać dane z wielu źródeł danych, które są ładowane za pomocą procesu ETL do hurtowni, a następnie wykorzystywane do celów analizy biznesowej.
Bezpośrednie porównanie między Data Lake a hurtownią danych (infografiki)
Poniżej znajduje się 14 najważniejszych różnic między Data Lake a Data Warehouse 
Kluczowe różnice
Istnieją główne kluczowe różnice między jeziorami danych a hurtownią danych:
- Składa się z nieustrukturyzowanych i ustrukturyzowanych danych z różnych platform, takich jak czujniki, aplikacje i strony internetowe itp. Składa się głównie z danych relacyjnych z systemów RDBMS, DBMS oraz innych operacyjnych baz danych i aplikacji.
- Data Lake jest przetwarzaniem schematu przy odczycie. Hurtownia danych jest przetwarzana według schematu przy zapisie.
- Jest bardzo zwinny. Jest mniej zwinny.
- Konfiguracja jest łatwa i można ją dostosować do zmian. Ma stałą konfigurację i bardzo trudno ją zmienić.
- Jest używany głównie przez naukowców AI i specjalistów od uczenia maszynowego. Jest używany przez profesjonalistów biznesowych.
Tabela porównawcza między Data Lake a Data Warehouse:
Omówmy najważniejszą różnicę między Data Lake a Data Warehouse
| Charakterystyka | Data Lake | Hurtownia danych |
| Przechowywanie | Dane są przechowywane w surowej postaci w Data Lake, a tutaj wszystkie dane są przechowywane niezależnie od źródła danych. Są one przekształcane w inne formy tylko w razie potrzeby. | Hurtownia danych składa się z danych pochodzących z systemów transakcyjnych i innych systemów metryk. Tutaj dane nie są w surowej formie i zawsze są przekształcane i czyste. |
| Użyj i cel | Głównym celem Data Lake są naukowcy danych, programiści Big Data i inżynierowie uczenia maszynowego, którzy muszą przeprowadzić dogłębną analizę, aby stworzyć modele dla firmy, takie jak modelowanie predykcyjne. | Głównym celem hurtowni danych są użytkownicy operacyjni, ponieważ dane te mają ustrukturyzowany format i mogą zapewniać gotowe do tworzenia raportów. Dlatego są one głównie wykorzystywane do analizy biznesowej. |
| Wejścia danych | Główne dane wejściowe do Data Lake to wszelkiego rodzaju dane, takie jak dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane. Dane te znajdują się w usłudze Data Lake w ich oryginalnej formie. | Główne dane wejściowe do hurtowni danych to ustrukturyzowane dane pochodzące z systemów transakcyjnych i metrycznych, które są następnie organizowane w formie schematów. |
| Jakość danych | Zawiera surowe dane, które mogą być leczone lub nie. | Składa się z wyselekcjonowanych danych, które są scentralizowane i są gotowe do pozwania do celów analizy biznesowej i analizy. |
| Normalizacja | Tutaj dane nie są w znormalizowanej formie. | Schematy znormalizowane |
| Historia | Technologie stosowane w jeziorach danych, takie jak Hadoop, Machine Learning, są stosunkowo nowe w porównaniu do hurtowni danych. | W tym przypadku technologia używana w hurtowni danych jest starsza. |
| Oś czasu danych | Jezioro danych może zawierać wszelkiego rodzaju dane i może być używane z myślą o przeszłości, teraźniejszości i perspektywach. | Jeśli chodzi o hurtownię danych, tutaj większość czasu poświęcana jest analizie różnych źródeł danych. |
| Czas przetwarzania | Tutaj czas przetwarzania podczas analizy i uzyskiwania wyników z Data Lake jest znacznie mniejszy niż w przypadku Data Warehouse, ponieważ tutaj dane są przechowywane w postaci surowych danych, a te nie są w przekształconym formacie, w wyniku czego skracamy czas które mogą być wydawane na przekształcanie danych. Możemy po prostu zebrać dane w obecnej postaci, wykonać podstawowe czyszczenie i zacząć budować nasze modele. | W przypadku hurtowni danych czas potrzebny na przetworzenie jest dłuższy w porównaniu do jeziora danych. Powodem tego jest to, że dane w dowolnej hurtowni danych muszą zostać najpierw przekształcone, a następnie przeanalizowane. |
| Koszt przechowywania | Koszt przechowywania danych w technologii Data Lake jest stosunkowo niższy niż w przypadku hurtowni danych i jest również mniej czasochłonny. | Koszt przechowywania w technologiach hurtowni danych jest większy w porównaniu do jeziora danych. Wynika to z faktu, że potrzebuje więcej miejsca na przekształcone dane, ponieważ najpierw musi przechowywać nieprzetworzone dane, a następnie przekształcić je, aby przypisać różne pola zgodnie ze strukturą hurtowni danych. |
| Zgodność | Tutaj dane są zawsze przechowywane w surowym formacie i są przekształcane tylko wtedy, gdy jest to wymagane lub gdy jest gotowe do użycia. | Tutaj dane są przechowywane w formacie przekształconym i możemy napotkać problemy przy próbie wprowadzenia zmian. |
| Dostępność | Dane w jeziorze danych są wysoce dostępne i mogą być szybko aktualizowane. | Dane w hurtowni danych są bardziej skomplikowane i wymaga wprowadzenia większych kosztów, a dostęp do nich jest ograniczony tylko dla upoważnionych użytkowników. |
| Pozycja schematu | Schemat jest najczęściej tworzony po zapisaniu danych. To zapewnia wysoką zwinność. | Tutaj schemat jest najczęściej tworzony przed przechowywaniem danych. |
| Proces przetwarzania | Jezioro danych wykorzystuje proces ELT, tj. Wyodrębnianie, ładowanie i przekształcanie. | Hurtownia danych wykorzystuje tradycyjne podejście ETL, tj. Wyodrębnianie, przekształcanie i ładowanie. |
| Korzyści | Data Lake prowadzi do nowych wynalazków, ponieważ integracja łączy różne rodzaje danych, a także dostarcza odpowiedzi na wiele pytań bez odpowiedzi. | Większość użytkowników organizacyjnych jest zaangażowana w działania operacyjne, a hurtownia danych stanowi jedną z takich genialnych platform do tworzenia raportów i metryk oprócz przekształconych danych. |
Wniosek
W tym poście dowiedzieliśmy się o Data Lakes vs. Data Warehouse. Posunęliśmy się również do przodu i porównaliśmy oba z nich na podstawie różnych parametrów. Powinno to pomóc każdemu uczniowi uzyskać podstawową wiedzę na temat technologii, które wspierają Data Lake i Data Warehouse.
Polecane artykuły
To był przewodnik po największej różnicy między Data Lake a Data Warehouse. Omówiliśmy kluczowe różnice między Data Lake a Data Warehouse za pomocą infografiki i tabeli porównawczej. Możesz także zapoznać się z następującymi artykułami, aby dowiedzieć się więcej -
- Scrum vs Waterfall - Najważniejsze różnice
- MySQL vs MySQLi - Który jest lepszy?
- Mikroprocesor kontra mikrokontroler
- Pytania do wywiadu dotyczące modelowania danych