

Jak zainstalować Kafka?
Kafka jest rozproszoną platformą streamingową. Pomaga w publikowaniu i subskrybowaniu strumieni rekordów. Kafka jest zwykle używany do budowania potoków przesyłania strumieniowego danych w czasie rzeczywistym, które niezawodnie uzyskują dane między różnymi systemami i aplikacjami. Może także pomóc w budowaniu aplikacji do przesyłania strumieniowego w czasie rzeczywistym, które pomagają w przekształcaniu lub wprowadzaniu zmian w strumieniach danych. Kafka umożliwia przechowywanie strumieni rekordów w różnych kategoriach zwanych tematami. Każdy rekord składa się z klucza, wartości i znacznika czasu. Zawiera cztery główne komponenty, takie jak API producenta, API konsumenta, API strumieni i API złącza. Wykorzystuje protokół TCP, który zapewnia dobrą komunikację między klientami i serwerami o wysokiej wydajności. Aby zainstalować Kafkę, wykonaj następujące czynności.
Zainstaluj Kafka w systemie operacyjnym Windows
Aby zainstalować Kafkę w systemie Windows, wykonaj następujące czynności:
Krok 1. Pobierz Zookeeper z następującego linku: HTTP: //zookeeper.apache.org/releases.html
Gdy to zrobisz, pobierz Kafkę z linku: http://kafka.apache.org/downloads.html
Pobierz również środowisko JRE zgodnie z systemem operacyjnym i architekturą procesora z poniższego łącza: http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
Krok 2. Konfiguracja JDK
Rozpocznij instalację środowiska JRE, a następnie kliknij pole wyboru „Zmień folder docelowy”. Teraz kliknij Zainstaluj.
Po zakończeniu zmień katalog na dowolną ścieżkę bez spacji w nazwie folderu.
Krok 3. Po wykonaniu tej czynności otwórz zmienne środowiskowe z Panelu sterowania -> System -> Zaawansowane ustawienia systemu -> Zmienne środowiskowe.
Krok 4. Kliknij opcję Nowa zmienna użytkownika na karcie Zmienna użytkownika, a następnie wpisz JAVA_HOME w nazwie zmiennej. Wpisz swoją ścieżkę JRE w sekcji Wartość zmiennej. Powinno być jak poniżej:
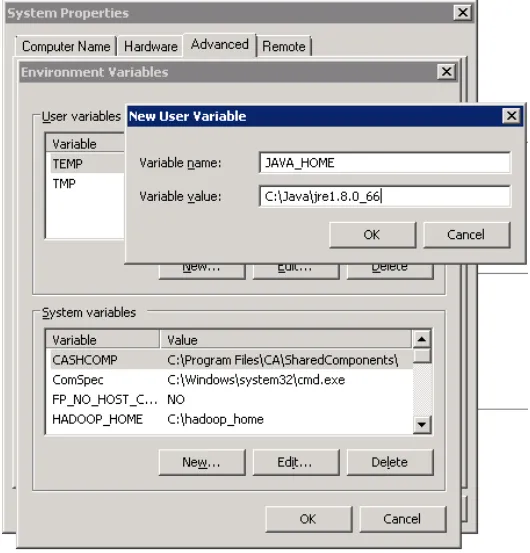
Krok 5. Teraz kliknij OK.
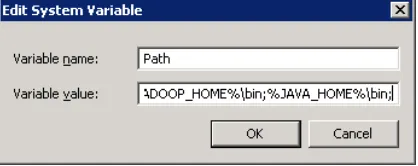
Krok 6. Wyszukaj zmienną ścieżki w sekcji „Zmienna systemowa” w otwartym oknie dialogowym „Zmienna środowiskowa”.
Krok 7. Edytuj ścieżkę i wpisz „;% JAVA_HOME% \ bin” na końcu już tam napisanego tekstu, tak jak na poniższym obrazku:
Krok 8. Aby sprawdzić, czy Java jest poprawnie zainstalowana, przejdź do wiersza polecenia i wpisz „java - wersja”. Zainstalowana wersja Java zostanie wyświetlona na ekranie.

Jeśli zobaczysz powyższe szczegóły w wierszu polecenia, oznacza to, że jesteś dobry od strony Java.
Po zainstalowaniu Javy możesz teraz przejść do konfiguracji Zookeeper.
Wykonaj poniższe kroki, aby zainstalować Zookeeper w systemie:
- Otwórz katalog, w którym znajduje się katalog konfiguracji Zookeeper. Może to być C: \ zookeeper-3.4.7 \ conf.
- Teraz zmień nazwę pliku „zoo_sample.cfg” na „cfg”
- Otwórz ten plik o zmienionej nazwie w Notatniku.
- Znajdź i edytuj: dataDir = / tmp / zookeeper to \ zookeeper-3.4.7 \ data
- Podobnie jak dodaliśmy zmienną środowiskową dla Javy, dodaj zmienną środowiskową dla Zookeeper.
- Ustaw ścieżkę zmiennych systemowych jako: dataDir = / tmp / zookeeper na: \ zookeeper-3.4.7 \ data
- Zmodyfikuj zmienną systemową o nazwie „Ścieżka” i dodaj; % ZOOKEEPER_HOME% \ bin;
- Domyślny port dla Zookeeper to 2181, który można zmienić na dowolny inny port, przechodząc do pliku zoo.cfg.
- Uruchom Zookeeper, otwierając nowy cmd i wpisz „zkserver”. Zobaczysz poniższe szczegóły.
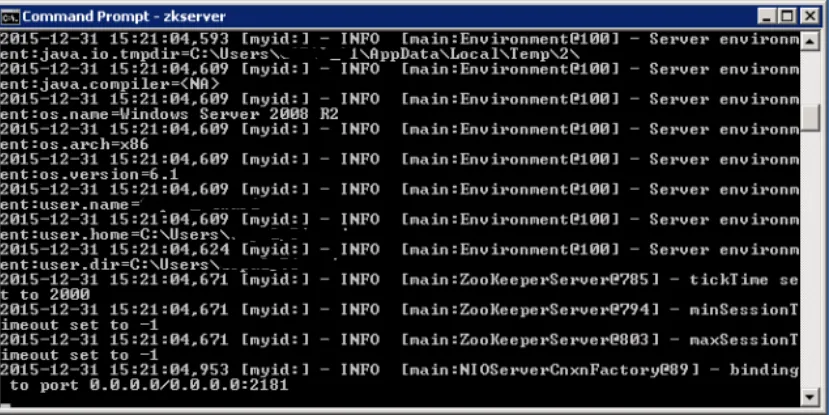
Gdy zobaczysz ten ekran, upewnij się, że Zookeeper został zainstalowany poprawnie.
Konfigurowanie Kafki
Kiedy już uruchomisz Javę i Zookeepera w swoim systemie, możesz zacząć konfigurować Kafkę.
- Przejdź do katalogu konfiguracji Kafka.
- Edytuj plik „server.properties”.
- Po wykonaniu tej czynności możesz znaleźć i edytować wiersz, w którym widzisz: dirs = / tmp / kafka-logs do „log.dir = C: \ kafka_2.11-0.9.0.0 \ kafka-logs
- Jeśli Twój Zookeeper działa na innym komputerze, możesz zmienić tę ścieżkę na „zookeeper.connect: 2181” na niestandardowy adres IP i identyfikator portu.
- Domyślnym portem dla Kafki jest port 9092, a do połączenia z Zookeeper jest to port 2181.
Uruchamianie serwera Kafka
Po zakończeniu wstępnej konfiguracji możesz łatwo uruchomić serwer Kafka
Przed uruchomieniem serwera Kafka należy upewnić się, że instancja Zookeeper jest uruchomiona.
1. Przejdź do katalogu instalacyjnego Kafka: C: /kafka_2.11-0.9.0.0
2. Otwórz wiersz polecenia i naciśnij Shift + prawy przycisk myszy i wybierz opcję „Otwórz okno poleceń tutaj”.
3. Teraz wpisz. \ Bin \ windows \ kafka-server-start.bat. \ Config \ server.properties i naciśnij klawisz Enter.
Po uruchomieniu tego i wszystko w porządku, ekran powinien wyglądać następująco:
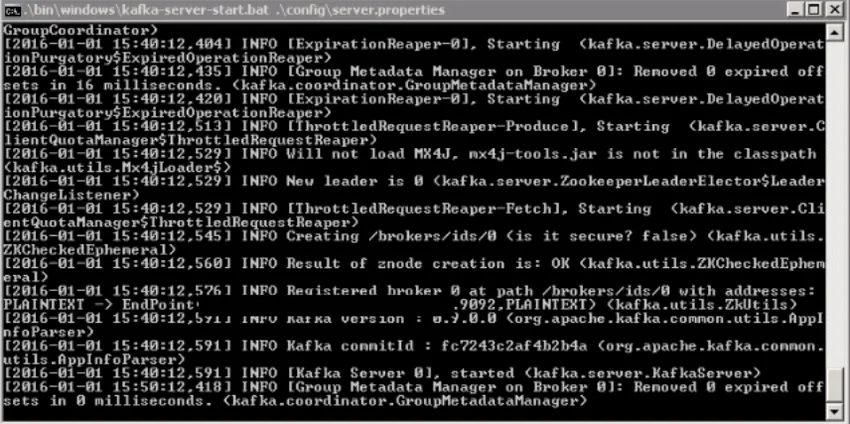
4. Teraz Twój serwer Kafka jest uruchomiony. Możesz tworzyć własne tematy do przechowywania różnych wiadomości. Po wykonaniu tej czynności możesz tworzyć i pobierać dane z kodu Java lub Scala lub bezpośrednio uruchamiać z wiersza polecenia.
Zainstaluj Kafkę w systemie Linux
Wykonaj poniższe kroki, aby zainstalować Kafkę w systemie Linux:
Krok 1. Pobierz i wyodrębnij pliki binarne Kafka i przechowuj je w katalogach.
Krok 2. Wyodrębnij archiwum, które pobierasz za pomocą polecenia tar.
Krok 3. Aby skonfigurować Kafkę, przejdź do server.properties. Otwórz ten plik za pomocą polecenia nano i dodaj następujące na dole pliku.
nano ~/Kafka/config/server.properties
delete.topic.enable = true
Krok 4. Po wykonaniu tej czynności użytkownik będzie musiał utworzyć pliki jednostek systemowych dla usług Kafka. Pomaga to w wykonywaniu typowych czynności serwisowych, takich jak uruchamianie, zatrzymywanie i restartowanie Kafki w spójny sposób z innymi usługami Linux. Zookeeper to usługa, z której korzysta Kafka w celu zarządzania swoim klastrem i konfiguracjami.
Krok 5. Aby utworzyć plik jednostki dla Zookeepera, wykonaj następujące czynności:
sudo nano /etc/systemd/system/zookeeper.service
Krok 6. Po utworzeniu tego pliku zookeepera wklej poniżej:
(Unit) Requires=network.target remote-fs.target
After=network.target remotefs.target
(Service) Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
(Install) WantedBy=multi-user.target
Ta sekcja (Jednostka) tutaj określa, że Zookeeper wymaga sieci i systemu plików, aby być gotowym przed uruchomieniem.
Sekcja (Usługa) informuje system, że pliki zookeeper-server-start.sh i zookeeper-server-stop.sh są dostępne do uruchamiania i zatrzymywania usług.
Krok 7. Teraz użytkownik powinien utworzyć plik systemowy dla Kafki, jak poniżej:sudo nano /etc/system/system/Kafka.service
Krok 8. W tym pliku wklej poniżej:
(Unit) Requires=zookeeper.service
After=zookeeper.service
(Service) Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh
/home/kafka/kafka/config/server.properties >
/home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.shRestart=on-abnormal
(Install) WantedBy=multi-user.target
Tutaj (Jednostka) określa, że plik jednostki jest zależny od zookeeper.service. Zapewnia to uruchomienie dozorcy przed uruchomieniem Kafki.
Krok 9. Teraz musisz włączyć Kafkę i zrestartować serwer. Uruchom: sudo systemctl włącz Kafkę
Krok 10. Testowanie instalacji:
Możesz przetestować swoją instalację Kafka, tworząc temat, a następnie publikując go konsumentom.
Utwórz temat : ~ / Kafka / bin / Kafka-topics.sh –create –zookeeper localhost: 2181 –replication-factor 1 –partitions 1 –topic Tutorial
Opublikuj ten użytkownik może tworzyć producentów i konsumentów, a następnie publikować dowolne dane na określone tematy.
Polecane artykuły
To był przewodnik po instalacji Kafki. Tutaj omawialiśmy różne kroki, aby zainstalować Kafkę w systemie Windows i Linux. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Krok, aby zainstalować Javę 8
- Jak zainstalować C
- Przewodnik po instalacji Ruby
- Aplikacje Kafka
- JRE vs JVM | 8 najważniejszych różnic z (Infografika)