

Omówienie architektury eksploracji danych
Eksploracja danych to sposób znajdowania i eksplorowania wzorców na poziomie podstawowym lub zaawansowanym w skomplikowanym zestawie dużych zestawów danych, który obejmuje metody umieszczone na przecięciu statystyki, uczenia maszynowego, a także systemów baz danych. Można powiedzieć, że jest to interdyscyplinarna dziedzina statystyki i nauk komputerowych, w której celem jest wydobycie informacji za pomocą inteligentnych metod i technik z określonego zestawu danych poprzez ekstrakcję, a tym samym przekształcenie danych. Brane są również pod uwagę działania związane z zarządzaniem danymi i czynnościami związanymi z przetwarzaniem danych oraz wnioskowanie. W tym artykule zagłębimy się w architekturę eksploracji danych.
Architektura Data Mining
Eksploracja danych to technika wydobywania interesującej wiedzy z zestawu ogromnych ilości danych, które następnie są przechowywane w wielu źródłach danych, takich jak systemy plików, hurtownie danych, bazy danych. Główne elementy architektury eksploracji danych obejmują -
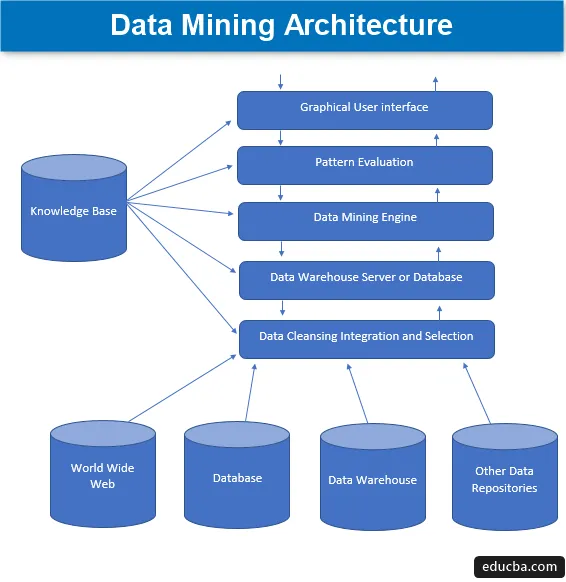
1. Źródła danych
Ogromna różnorodność obecnych dokumentów, takich jak hurtownia danych, baza danych, www lub popularnie nazywana siecią WWW, która staje się rzeczywistymi źródłami danych. W większości przypadków dane mogą nie występować w żadnym z tych złotych źródeł, a jedynie w postaci plików tekstowych, zwykłych plików lub plików sekwencji lub arkuszy kalkulacyjnych, a następnie dane muszą zostać przetworzone w bardzo podobnie jak w przypadku przetwarzania danych otrzymanych ze złotych źródeł. Większość głównych fragmentów danych jest obecnie odbierana z Internetu lub Internetu, ponieważ wszystko, co jest dziś w Internecie, to dane w jakiejś formie, które tworzą jakąś formę jednostek repozytorium informacji.
Zanim dane zostaną przetworzone z wyprzedzeniem, różne procesy, przez które przechodzą, obejmują czyszczenie, integrację i selekcję danych, zanim dane zostaną ostatecznie przesłane do bazy danych lub dowolnego serwera EDW (hurtowni danych przedsiębiorstwa). Największym wyzwaniem, które czasami wiąże się z tym zestawem danych, są różne poziomy źródeł i szeroka gama formatów danych, które tworzą komponenty danych. Dlatego dane nie mogą być bezpośrednio wykorzystywane do przetwarzania w stanie naiwnym, lecz przetwarzane, przekształcane i wytwarzane w znacznie bardziej użyteczny sposób. W ten sposób zapewniona jest również niezawodność i kompletność danych. Tak więc, pierwszy krok polega na gromadzeniu, czyszczeniu i integracji danych oraz wysyłaniu wiadomości, że tylko odpowiednie dane są przekazywane dalej. Cała ta aktywność stanowi część oddzielnego zestawu narzędzi i technik.
2. Serwer hurtowni danych lub baza danych
Serwer bazy danych to rzeczywista przestrzeń, w której dane są zawarte po ich otrzymaniu z różnej liczby źródeł danych. Serwer zawiera rzeczywisty zestaw danych, który jest gotowy do przetworzenia, a zatem serwer zarządza odzyskiwaniem danych. Cała ta działalność opiera się na żądaniu eksploracji danych osoby.
3. Silnik eksploracji danych
W przypadku eksploracji danych silnik stanowi podstawowy komponent i jest najważniejszą częścią, lub, mówiąc inaczej, siłą napędową, która obsługuje wszystkie żądania i zarządza nimi oraz jest używana do przechowywania wielu modułów. Liczba obecnych modułów obejmuje zadania wydobywcze, takie jak technika klasyfikacji, technika asocjacji, technika regresji, charakteryzacja, przewidywanie i grupowanie, analiza szeregów czasowych, naiwne Bayesa, maszyny wektorów nośnych, metody łączenia, techniki wzmocnienia i workowania, losowe lasy, drzewa decyzyjne, itp.
4. Moduły oceny wzoru
Ta technika oceny modułów jest głównie odpowiedzialna za pomiar ciekawości wszystkich wzorców, które są używane do obliczania podstawowego poziomu wartości progowej, a także służy do interakcji z silnikiem eksploracji danych w celu koordynacji w ocenie innych modułów. Podsumowując, głównym celem tego komponentu jest wyszukiwanie i wyszukiwanie wszystkich interesujących i użytecznych wzorców, które mogłyby sprawić, że dane będą porównywalnie lepszej jakości.
5. Graficzny interfejs użytkownika
Gdy dane są przesyłane z silnikami i między różnymi ocenami wzorców modułów, staje się koniecznością interakcji z różnymi obecnymi komponentami i uczynienia ich bardziej przyjaznymi dla użytkownika, tak aby możliwe było wydajne i skuteczne wykorzystanie wszystkich obecnych komponentów, a zatem powstaje potrzeba graficznego interfejsu użytkownika popularnie zwanego GUI.
Służy to do ustanowienia poczucia kontaktu między użytkownikiem a systemem eksploracji danych, pomagając w ten sposób użytkownikom uzyskać dostęp do systemu i korzystać z niego w sposób wydajny i łatwy, aby uniknąć ich złożoności powstającej w procesie. Jest to forma abstrakcji, w której użytkownicy wyświetlają tylko odpowiednie komponenty, a wszystkie złożoności i funkcjonalności odpowiedzialne za budowę systemu są ukryte ze względu na prostotę. Za każdym razem, gdy użytkownik prześle zapytanie, moduł wchodzi następnie w interakcję z ogólnym zestawem systemu eksploracji danych, aby uzyskać odpowiednie dane wyjściowe, które można łatwo pokazać użytkownikowi w znacznie bardziej zrozumiały sposób.
6. Baza wiedzy
Jest to komponent, który stanowi podstawę całego procesu eksploracji danych, ponieważ pomaga w kierowaniu wyszukiwaniem lub ocenie interesujących formowanych wzorów. Ta baza wiedzy obejmuje przekonania użytkowników, a także dane uzyskane z doświadczeń użytkowników, które z kolei są pomocne w procesie eksploracji danych. Silnik może uzyskać zestaw danych wejściowych z utworzonej bazy wiedzy, a tym samym zapewnia bardziej wydajne, dokładne i wiarygodne wyniki.
Eksploracja danych jest obecnie jedną z najważniejszych technik zarządzania danymi i przetwarzania danych, które stanowią trzon każdej organizacji. Analiza danych w dowolnej organizacji przyniesie owocne rezultaty. Każdy element techniki i architektury eksploracji danych ma swój własny sposób wykonywania obowiązków, a także skutecznego wykonywania eksploracji danych. Różne moduły są potrzebne do prawidłowego współdziałania, aby uzyskać cenny wynik i pomyślnie ukończyć złożoną procedurę eksploracji danych, zapewniając odpowiedni zestaw informacji dla firmy.
Polecane artykuły
To był przewodnik po architekturze Data Mining. Tutaj omawiamy podstawowe elementy architektury eksploracji danych. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Narzędzie wyszukiwania danych
- Zalety eksploracji danych
- Co to jest klastrowanie w eksploracji danych?
- Wywiad HTML5 Pytania i odpowiedzi
- Najczęściej stosowane techniki uczenia się w zespole
- Algorytmy modeli w eksploracji danych