
Różnice między Cloud Computing a Hadoop
Chmura obliczeniowa
W dzisiejszych czasach przetwarzanie w chmurze oznacza przechowywanie, dostęp do danych, programów, aplikacji i plików przez Internet lokali, a nie lokalnie zainstalowanych na dysku twardym. Przetwarzanie w chmurze zapewnia usługę obliczeniową na żądanie za pomocą sieci komunikacyjnej na zasadzie odpłatności, w tym aplikacji lub kompletnych centrów danych na scentralizowanym serwerze, który jest dostępny z dowolnego miejsca na świecie za pomocą Internetu. Przetwarzanie w chmurze oferuje różne rodzaje usług, takie jak infrastruktura jako usługa (IaaS), platforma jako usługa (PaaS) i oprogramowanie jako usługa (SaaS).
Przetwarzanie w chmurze wyeliminowało obawy firm instalujących oprogramowanie i usługi we własnym środowisku firmowym, które jest bardzo drogie.
Najlepsze firmy świadczące usługi publiczne, prywatne, mobilne i hybrydowe w chmurze obliczeniowej
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- Cegła suszona na słońcu
- VMware
- IBM Cloud
- Rackspace
- czerwony kapelusz
- Siły sprzedaży
- Oracle Cloud
- SOK ROŚLINNY
- Verizon Cloud
- Navisite
- Dropbox
- Egnyte
Hadoop
Hadoop został opracowany przez Apache Software Foundation jako ekosystem open source, wykorzystujący platformę programowania opartą na Javie do obsługi, przetwarzania i przechowywania dużych zbiorów danych w rozproszonym środowisku opartym na systemie plików HDFS. Hadoop obsługuje manipulację dużymi danymi, przechowując i analizując ustrukturyzowane i nieustrukturyzowane dane w klastrach i węzłach danych z różnych komputerów przy użyciu prostych modeli programowania zasadniczo związanych z rodzajem programowania SQL.
Hadoop to kabel do obsługi danych o ogromnej objętości, różnej różnorodności, dużej prędkości i prawdziwości z ogromną mocą przetwarzania.
Hadoop nie jest biblioteką do przetwarzania dużych zbiorów danych, ale ma kolekcję bibliotek do obsługi danych i pokrewnych technologii analizy danych.
Hadoop jest szeroko stosowany w ciągu ostatnich 10 lat, gdy duże zbiory danych ewoluowały, a media społecznościowe codziennie generują bity danych PETA, które mogą być wykorzystywane do analiz predykcyjnych, eksploracji danych i uczenia maszynowego.
Organizacja Apache opisuje niektóre elementy ekosystemu Hadoop
- Ambari
- HDFS, Hadoop MapReduce,
- Ul,
- HCatalog,
- HBase,
- ZooKeeper,
- Oozie,
- Świnia,
- Sqoop
Bezpośrednie porównanie między Cloud Computing a Hadoop (infografiki)
Poniżej znajduje się porównanie Top 6 między Cloud Computing a Hadoop 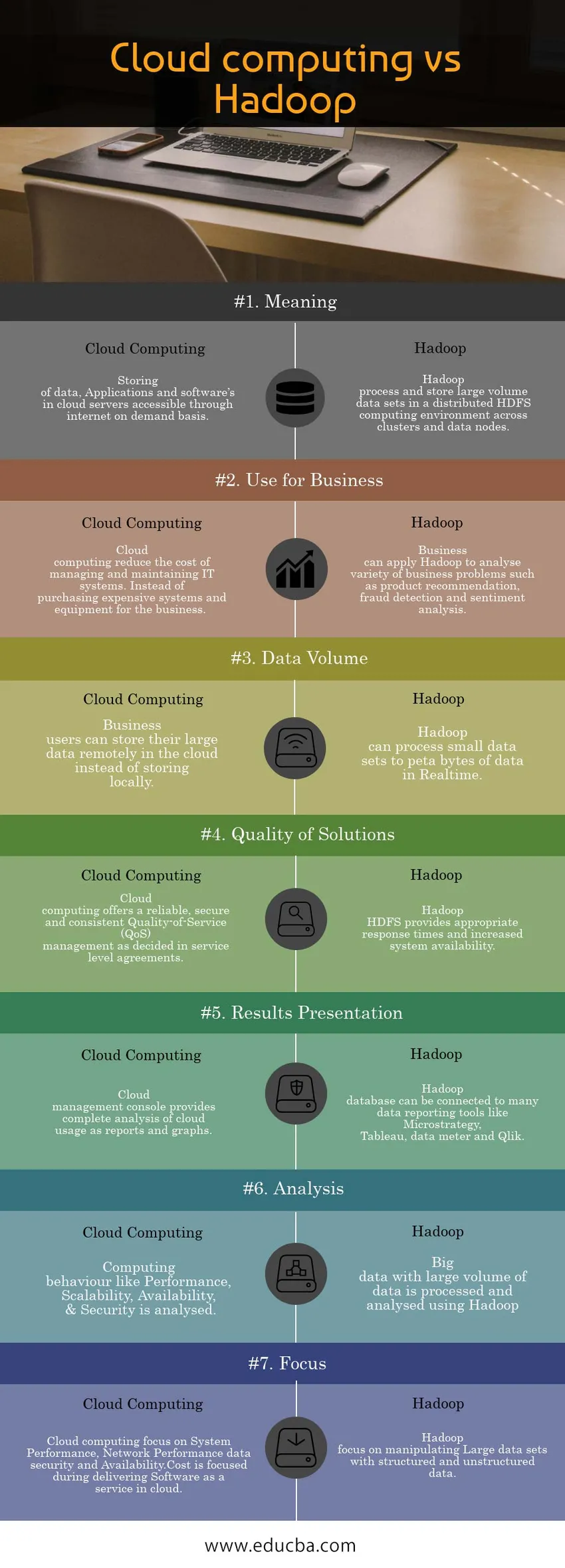
Kluczowe różnice między Cloud Computing a Hadoop
Poniżej znajdują się listy punktów, opisujące kluczowe różnice między Cloud Computing a Hadoop
- Przetwarzanie w chmurze, w którym oprogramowanie i aplikacje zainstalowane w chmurze są dostępne przez Internet, ale Hadoop to platforma oparta na Javie służąca do manipulowania danymi w chmurze lub lokalnie. Hadoop można zainstalować na serwerach w chmurze, aby zarządzać dużymi danymi, natomiast sama chmura nie może zarządzać danymi bez Hadoop w nim.
- Pakiety Hadoop składają się z funkcji systemu rozproszonej bazy danych wewnątrz systemu plików, który obsługuje nieustrukturyzowane dane i przechowuje dużą ilość danych o wysokiej szybkości przetwarzania w zależności od szybkości procesora. Cloud Computing to rozproszone usługi obliczeniowe, w których infrastruktury IT są dostępne w oparciu o szybkość sieci.
- Hadoop to projekty oprogramowania typu open source zaprojektowane do manipulowania danymi, ale przetwarzanie w chmurze to usługi na żądanie oferowane do zarządzania danymi i ich aplikacjami wspierającymi.
- Hadoop ma różne komponenty, które można dodawać tylko w celu obsługi dużych zbiorów danych, ale w modelu przetwarzania w chmurze zarządza się wszystkimi Hadoop oraz jego komponentami i aplikacjami obsługującymi ekosystem Hadoop.
- Hadoop to platforma Java, którą można zainstalować w centrach danych w chmurze lub lokalnie, ale przetwarzanie w chmurze jest opracowane jak komputer w chmurze, na którym zainstalowane są wszystkie Hadoop i Java.
- Dostęp do aplikacji w chmurze jest szybki dzięki szybkiej sieci prywatnej, ale prędkość przesyłu danych w Hadoop zależy od szybkości procesora i procesora systemowego zainstalowanego w Hadoop.
- Usługi przetwarzania w chmurze oferują usługi cofania danych dla metadanych aplikacji i danych w czasie rzeczywistym, gdy mówimy o identyfikatorze Hadoop Hadoop jest zainstalowany w chmurze, wówczas usługi przetwarzania w chmurze zajmą się powrotem danych podstawowych jako obsługą klienta i opłaci za bezpieczeństwo.
- Wdrożenie usług przetwarzania w chmurze jest łatwe, ponieważ nie wymaga dużej wiedzy na temat instalacji, a także dostawcy usług w chmurze mają wysoko wykwalifikowaną siłę roboczą do utrzymania i zapewnienia wsparcia w zakresie usług o niskim budżecie, dzięki czemu ROI będzie większy dla organizacji.
Podczas gdy korzystanie z Hadoop lub instalowanie Hadoop zainstalowanego w chmurze obliczeniowej lub w domu, umiejętności Hadoop i Big Data są obowiązkowe, a usługi nauki danych Hadoop zapewniają wgląd w dane biznesowe, dane analityczne itp., Które zwrócą większe dochody organizacji. - W chmurze różni użytkownicy mogą zdalnie korzystać z różnych aplikacji lub usług w chmurze w dowolnym momencie i czasie.
Podobnie Hadoop ma funkcję wielozadaniowości, w której jest w stanie przetwarzać równolegle duże zestawy danych przy użyciu metody zwanej równoległym przetwarzaniem danych. - Funkcje bezpieczeństwa przetwarzania w chmurze zapewnią funkcję tworzenia kopii zapasowych po awarii w przypadku, gdy serwery przetwarzania w chmurze są zdalnie zarządzane z wysokim poziomem bezpieczeństwa i ochrony, te same funkcje oznaczają w Hadoop, gdzie ma funkcję odporności na uszkodzenia, w której dane są przetwarzane w jednym węźle, a dane są replikowane w innej notatce w klastrze. Kiedy więc wystąpi awaria w jednym węźle, kopia danych jest dostępna w innym węźle.
Tabela porównawcza między Cloud Computing a Hadoop
Poniżej znajdują się listy punktów, opisz różnice między Cloud Computing a Hadoop
| PODSTAWA DO PORÓWNANIA | Chmura obliczeniowa | Hadoop |
| Znaczenie | Przechowywanie danych, aplikacji i oprogramowania znajduje się na serwerach w chmurze dostępnych za pośrednictwem Internetu na żądanie. | Hadoop przetwarza i przechowuje duże zbiory danych w rozproszonym środowisku obliczeniowym HDFS w klastrach i węzłach danych. |
| Użyj dla biznesu | Przetwarzanie w chmurze zmniejsza koszty zarządzania i utrzymania systemów informatycznych. Zamiast kupować drogie systemy i sprzęt dla firmy. | Firma może zastosować Hadoop do analizy różnych problemów biznesowych, takich jak rekomendacja produktu, wykrywanie oszustw i analiza nastrojów. |
| Objętość danych | Użytkownicy biznesowi mogą przechowywać swoje duże dane zdalnie w chmurze zamiast przechowywać lokalnie. | Hadoop może przetwarzać małe zestawy danych do petabajtów danych w czasie rzeczywistym. |
| Jakość rozwiązań | Przetwarzanie w chmurze oferuje niezawodne, bezpieczne i spójne zarządzanie jakością usług (QoS) zgodnie z umowami o gwarantowanym poziomie usług. | Hadoop HDFS zapewnia odpowiedni czas reakcji i większą dostępność systemu. |
| Prezentacja wyników | Konsola zarządzania chmurą zapewnia pełną analizę wykorzystania chmury jako raportów i wykresów. | Baza danych Hadoop może być podłączona do wielu narzędzi do raportowania danych, takich jak Microstrategy, Tableau, licznik danych i Qlik. |
| Analiza | Analizowane są zachowania komputerowe, takie jak wydajność, skalowalność, dostępność i bezpieczeństwo. | Duże dane z dużą ilością danych są przetwarzane i analizowane za pomocą Hadoop. |
| Skupiać | Przetwarzanie w chmurze koncentruje się na wydajności systemu, bezpieczeństwie danych wydajności sieci i dostępności.
Koszt koncentruje się na dostarczaniu oprogramowania jako usługi w chmurze. | Hadoop koncentruje się na manipulowaniu dużymi zestawami danych za pomocą danych ustrukturyzowanych i nieustrukturyzowanych. |
Wniosek - przetwarzanie w chmurze vs Hadoop
Po krótkim badaniu, aby poznać różnicę między chmurą obliczeniową a Hadoop, czy też Hadoop różni się od chmury obliczeniowej?
Doszedłem do wniosku, że zarówno przetwarzanie w chmurze, jak i Hadoop są prostsze od siebie, gdzie przetwarzanie w chmurze jest jak pudełko z Dollarami, a Hadoop jest jak każdy dolar w pudełku.
Przetwarzanie w chmurze to pamięć masowa z różnymi systemami operacyjnymi, aplikacjami, platformami, zainstalowanymi zestawami programistycznymi utrzymywanymi na platformie chmurowej dostępnej przez Internet, do której można uzyskać zdalny dostęp na żądanie zgodnie z wymaganiami organizacji.
Podczas gdy Hadoop to oprogramowanie opracowane przez fundację Apache przy użyciu frameworka Java do obsługi danych. Hadoop można zainstalować w dowolnej usłudze wdrażania w chmurze, takiej jak AWS, Microsoft lub Google.
Hadoop nie może świadczyć usług w zakresie zarządzania aplikacjami, pamięcią masową i oprogramowaniem
Ale przetwarzanie w chmurze zarządza Hadoop i powiązanymi z nim komponentami, takimi jak systemy źródłowe, docelowa baza danych i środowiska wykonawcze itp.
Przetwarzanie w chmurze jest jak komputer z zainstalowanym i utrzymywanym wirtualnie innym oprogramowaniem, ale Hadoop to pakiet oprogramowania, który można zainstalować na komputerze lub komputerze wirtualnie utrzymywanym w chmurze.
Polecany artykuł
Jest to przewodnik po różnicach między chmurą obliczeniową a Hadoop, ich znaczeniu, porównaniem bezpośrednim, kluczowymi różnicami, tabelą porównawczą i wnioskami. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Najbardziej niesamowite różnice między Azure Paas a Iaas
- Poznaj 5 najbardziej przydatnych różnic między chmurą obliczeniową a analizą danych
- 10 najlepszych przydatnych porównań między chmurą obliczeniową a wirtualizacją
- Hadoop vs Elasticsearch - Który jest bardziej przydatny
- Odkryj 6 najlepszych różnic między Apache Hadoop a Apache Storm