
Struktury danych i algorytmy C ++
Struktury i algorytmy danych C ++ - oznacza układanie lub organizowanie elementów w określony sposób. Kiedy mówimy, że musimy układać elementy, elementy te mogą być organizowane w różnych formach. Na przykład skarpetki można ułożyć na różne sposoby. Możesz po prostu trzymać go w szafce. Lub możesz go starannie złożyć. Najlepszym sposobem jest złożenie i ułożenie ich pod względem kolorów. Aby wyszukać konkretną parę skarpet, trzecia aranżacja jest idealna.
W podobny sposób organizacji skarpet Dane można również organizować na różne sposoby lub w różne formy. Te różne sposoby organizowania danych nazywane są strukturą danych. Zobaczmy formalną definicję struktury danych oraz podstawy struktur i algorytmów.
Struktury danych i algorytmy C ++:
Logiczny lub matematyczny model konkretnej organizacji danych.
LUB
Jest to szczególny sposób organizowania danych w komputerze, aby można było z nich korzystać.
Podobnie jak skarpetki; inna organizacja struktur danych listy i algorytmów dostępnych w C ++ to -
- Szyk
- Połączona lista
- Stos
- Kolejka
- Drzewo
- Wykres
- Tabela mieszania
- Sterta
- Dokumentacja
- Stoły
Te struktury danych i algorytmy C ++ są bardzo ważne podczas programowania. Dobry programista zawsze kładzie nacisk na strukturę danych, a nie na kod. Każdy język programowania działa na różnych strukturach danych i algorytmach w C ++. Struktury danych dostępne w C ++ są następujące.
- Szyk
- Połączona lista
- Stos
- Kolejka
- Drzewo
- Wykres
- Tabela mieszania
- Sterta
Omówmy to jeden po drugim:
# 1 Tablica
Tablica to najprostszy typ struktur danych i algorytmów C ++. Tablica jest zdefiniowana jako sekwencyjny zbiór poprawek o wielkości elementów danych tego samego typu. Np. A0 = 12, a1 = 21, a2 = 14, a3 = 15… Możemy reprezentować tablicę jednowymiarową, jak pokazano na rysunku:
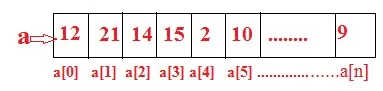
Gdzie
0, 1, 2, 3… ..n nazywa się indeksem dolnym lub indeksem
a (1), a (2), … a (n) nazywa się zmienną indeksu dolnego
Może być 1-wymiarowy, 2-wymiarowy, 3-wymiarowy i tak dalej na wielu wymiarach.
W pamięci tablic przechowuje w ciągłych lokalizacjach pamięci.
Najniższy adres odpowiada pierwszemu elementowi
Najwyższy adres odpowiada ostatniemu elementowi
Możemy zadeklarować tablicę 1-D (1-wymiarową) w C ++ w następujący sposób
dataType arrayName (arraySize);
Np. Int num (5);
Inicjowanie tablicy w C ++
num = (23, 10, 12, 3, 6);
Możemy połączyć deklarację i inicjalizację w jedną instrukcję w następujący sposób.
int num = (23, 10, 12, 3, 6);
Gdy chcemy dynamicznie przydzielić rozmiar tablicy, powinniśmy nowego operatora w następujący sposób
int * a = nowy int (rozmiar);
Wadą tablicy jest to, że wstawianie i usuwanie elementów jest powolne, jak w uporządkowanej tablicy i jej przechowywaniu o stałym rozmiarze.
# 2 Połączona lista
Lista odnosi się do liniowej kolekcji przedmiotów. Połączona lista to seria połączonych węzłów (element danych), jak pokazano na rysunku 3. Węzeł nagłówka wskazuje na pierwszy węzeł listy, a ostatni węzeł wskazuje na NULL oznaczony przez Æ. Ponieważ każdy węzeł zawiera co najmniej.
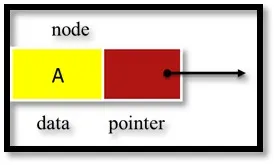
- Kawałek danych (dowolny typ)
- Wskaźnik do następnego węzła na liście
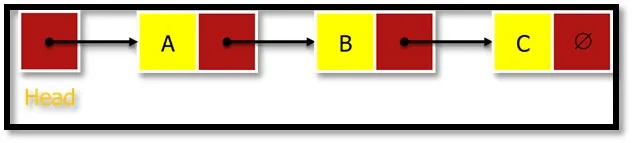
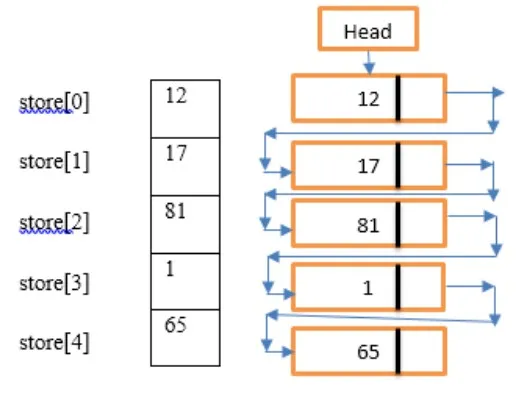
Lista połączona jest reprezentowana w pamięci za pomocą dwóch tablic. Jedna tablica przechowuje informacje zwane informacjami, które są danymi, które mają być przechowywane, a inne przechowuje pole wskaźnika następnego o nazwie LINK, które jest adresem następnego węzła.
Przewaga połączonej listy nad tablicą:
Zarówno tablica, jak i połączona lista są reprezentacjami listy elementów w pamięci. Ważną różnicą jest sposób, w jaki elementy są ze sobą połączone. Głównym ograniczeniem tablicy jest wstawianie elementów do tablicy, a usuwanie elementów z uporządkowanej tablicy jest trudne, ponieważ pozostałe elementy muszą być przenoszone. Wstawianie i usuwanie elementów z połączonej listy jest bardzo proste.
Naucz się projektować i dostosowywać programy dla różnych platform. Koduj, testuj, debuguj i wdrażaj aplikacje. Rozwijaj umiejętności, aby zapewnić płynne działanie aplikacji.
Rodzaje połączonych list to:
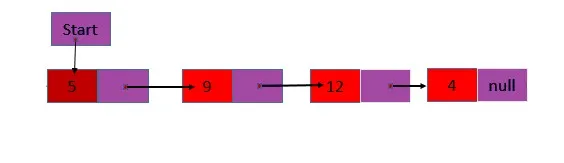
1. Pojedynczo połączona lista : zawiera tylko jedno połączone pole, w którym znajduje się adres następnego węzła na liście oraz w złożonej informacji, w której przechowywane są informacje.
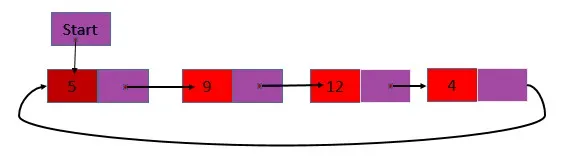
2. Pojedyncza okrągła lista połączona jest tylko pojedynczą listą, ale ostatni węzeł listy zawiera adres pierwszego węzła zamiast wartości null. To jest zawartość nagłówka, a następne pole ostatniego węzła są takie same.
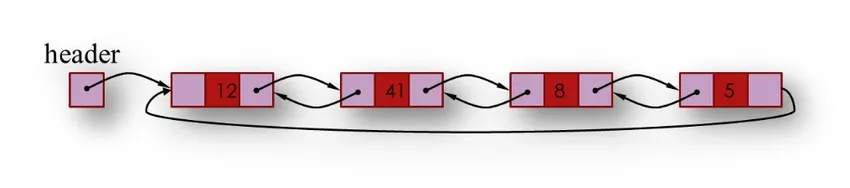
3. Podwójnie połączona lista zawiera dwa połączone pola poprzedni i następny. Poprzednio połączone pole, które zawiera adres poprzedniego węzła na liście, a następne pole połączone zawiera adres następnego węzła na liście, a w złożonej informacji przechowywane są informacje, które mają być magazynem.

4. Podwójnie połączona lista jest podwójnie połączoną listą, ale następne pole ostatniego węzła zawiera adres pierwszego węzła zamiast null.
Polecane kursy
- Kurs na VB.NET
- Szkolenie z zakresu programowania danych
- Internetowy kurs ISTQB
- Szkolenie Kali Linux
Implementacja listy połączonej w C ++ obejmuje utworzenie węzła, usunięcie węzła z listy, wstawienie nowo utworzonego węzła do listy i przeszukanie węzła za pomocą określonego klucza.
Kod do utworzenia węzła podano w następujący sposób:

Wstawienie węzła do listy obejmuje trzy przypadki
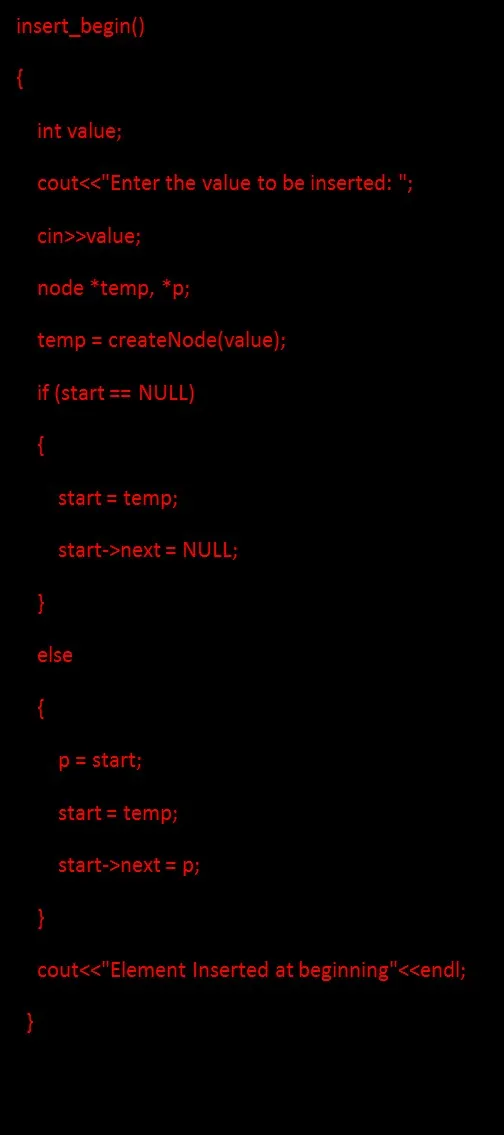
1. Wstawienie węzła na początku oznacza wstawienie nowo utworzonego węzła jako węzła początkowego. Aby wstawić węzeł na początku, najpierw utwórz nowy węzeł i ustaw nowy węzeł na stary początek, a następnie zaktualizuj początek na nowy węzeł, jak pokazano na poniższym rysunku:
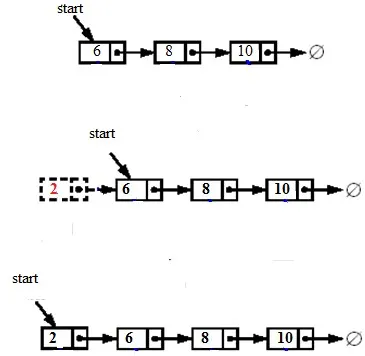
Kod wstawiania węzła na początku:
2. Wstawienie węzła na ogonie oznacza wstawienie nowo utworzonego węzła jako ostatniego węzła. Aby wstawić węzeł jako węzeł ogona, należy utworzyć nowy węzeł i sprawić, by stary ostatni węzeł wskazywał na nowy węzeł, a następnie zaktualizować ogon, aby wskazywał na nowy węzeł.
3. Wstawienie węzła w danej pozycji wymaga utworzenia nowego węzła tymczasowego, a następnie trzeba znaleźć pozycję wstawienia nowo utworzonego węzła.
Kod do wstawienia węzła w danej pozycji:

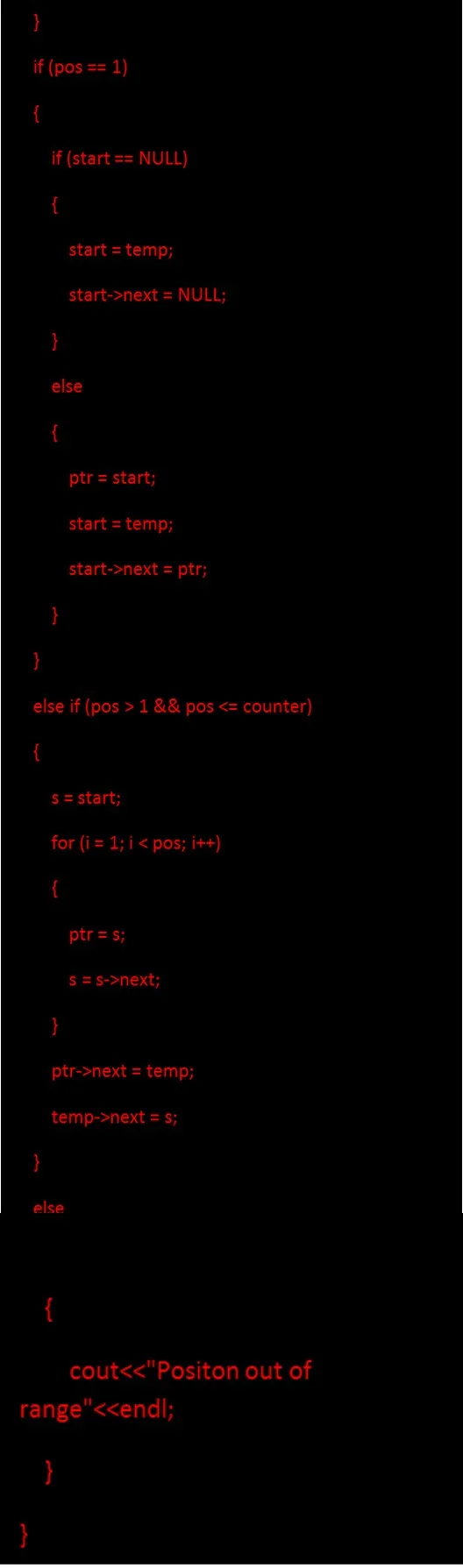
Usunięcie węzła z listy obejmuje usunięcie węzła z istniejącej listy. Usunięcie węzła z listy łączy jest proste niż wstawienie węzła do listy. W kodzie C ++ do usunięcia węzła podano w następujący sposób:

Przejście węzła z określonym kluczem (wartością) z listy spowoduje przeszukanie węzła z listy, którego informacje będą pasować do klucza danego węzła. Poniższy kod C ++ przejdzie przez listę. struktury danych i algorytmy C ++


Stos nr 3
Stos to lista elementów, w których element można wstawiać lub usuwać tylko na jednym końcu, nazywany górną częścią stosu. Rozważ przykład wieży Hanoi. Tutaj, gdy musimy włożyć płytę, musimy włożyć ją tylko od góry i podobnie wyjmowanie płyty odbywa się tylko od góry.
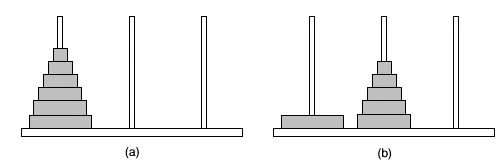
Stos wykorzystuje zasadę LIFO, co oznacza, że działa w kolejności „ostatni na pierwszym”. To ostatni element dodany do stosu to pierwszy element usuwany. Istnieją więc cztery podstawowe operacje, które można wykonać na stosie:
- Isempty: Ta operacja sprawdza, czy stos jest pusty.
- Push : ta operacja dodaje nowy element do stosu.
- Pop: Ta operacja usuwa element ze stosu dodanego ostatnio.
- Góra: Ta operacja zwraca element, który został ostatnio dodany do stosu.
Poniższy rysunek jest przykładem stosu, w którym wkładanie do stosu i usuwanie ze stosu elementu odbywa się od góry stosu i nigdzie indziej.
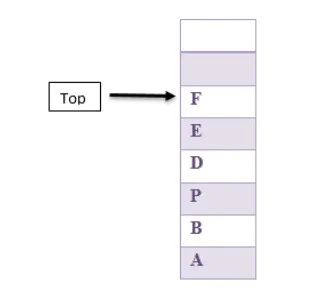
Przepełnienie stosu
Stan wynikający z próby pchnięcia elementu na pełny stos.
Przepełnienie stosu
Warunek wynikający z próby zniszczenia pustego stosu.
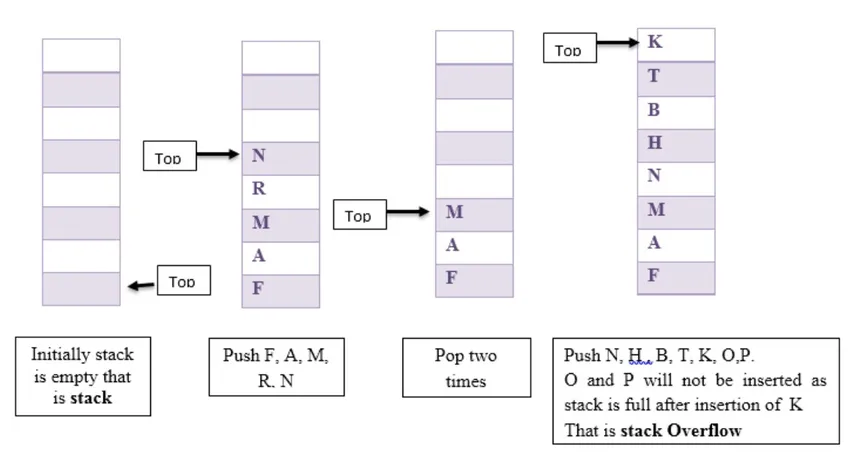
Tutaj pokazaliśmy kilka operacji push i pop na stosie. Załóżmy, że początkowo stos jest pusty, a następnie dodaliśmy F, A, M, R, N. Następnie pop dwa razy i wciśnij N, H, B, T, K, O, P.
Implementacja stosu:
Może być zaimplementowany przy użyciu zarówno tablicy, jak i połączonej listy.
Poniższy kod przedstawia sposób implementacji stosu w C ++ przy użyciu Class. Tutaj zdefiniowano jedną klasę o nazwie stos, w której utworzono tablicę o nazwie drążek o dynamicznym rozmiarze i dwóch głównych funkcjach push i pop.
Przepełnienie stosu: gdy góra> = rozmiar-1
Niedopełnienie stosu: gdy górny <0

Powiązane artykuły:-
Oto kilka artykułów związanych ze strukturami danych i algorytmami C ++, które pomogą Ci uzyskać bardziej szczegółowe informacje na temat algorytmów C ++ oraz struktur danych i algorytmów, dlatego prosimy o skorzystanie z linku podanego poniżej. jeśli podoba Ci się struktura danych artykułu i algorytmy C ++, daj nam swój cenny komentarz.
- Ściągawka dla języka programowania C ++
- Linux vs Ubuntu
- Pytania do wywiadu C ++, które musisz znać
- Struktury danych i algorytmy Pytania do wywiadu Najbardziej użyteczne
- Najlepszy artykuł dotyczący algorytmów i kryptografii (przykłady)
- 8 Niesamowitych pytań i odpowiedzi na wywiad z algorytmem
- Niesamowity przewodnik po Kali Linux vs Ubuntu
- C ++ Vector vs Array: Jakie są najlepsze funkcje