

Wprowadzenie do instalacji ula
W instalacji Hive przed instalacją należy spełnić pewne warunki wstępne.
Wszystkie komponenty Hadoop, takie jak Hive, Hbase, Pig itp., Obsługują środowisko Linux. Dlatego zaleca się posiadanie systemu operacyjnego Linux na swoim urządzeniu. Jeśli tak nie jest i chcesz ćwiczyć na gałęzi, mając okna w swoim systemie. Co możesz zrobić, to zainstalować maszynę CDH w systemie i używać jej jako platformy do eksploracji Hadoop. Będzie to wymagało minimum 4 GB pamięci RAM w twoim systemie lub Możesz mieć urządzenie CDH w pendrivie i korzystać z niego.
W każdym razie zawsze możesz znaleźć rozwiązanie swojego pytania, które może wcześniej niż później.
Wymagania wstępne do zainstalowania gałęzi
Istnieją pewne warunki wstępne, aby zainstalować gałąź na dowolnym komputerze:
- Instalacja Java
- Instalacja Hadoop
Krok 1
- Sprawdź, czy Java jest zainstalowana.
- Otwórz terminal i wpisz polecenie.
Wersja Java
- Jeśli java jest zainstalowana w systemie, wyświetli się wersja lub błąd. W moim przypadku Java jest już zainstalowana, a poniżej znajduje się wynik działania polecenia.

- W przypadku, gdy Java nie jest zainstalowana w twoim systemie. Możesz odwiedzić poniższy link, pobrać java i zainstalować go.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Instalacja Java
- Wyodrębnij pobrane.
- Przenieś go do „/ usr / local /”.
- Skonfiguruj zmienne PATH i JAVA_HOME.
Krok 2
- Sprawdź, czy Hadoop jest zainstalowany.
- Otwórz terminal i wpisz polecenie.
Wersja Hadoop
- Jeśli Hadoop jest już zainstalowany, to polecenie wyświetli wersję lub błąd.
- W moim przypadku Hadoop już zainstalował, dlatego poniższe wyjście.
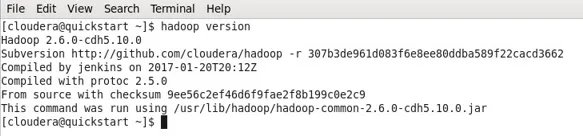
- Teraz możesz zaobserwować, że pracuję z maszyną CDH5.
- Jeśli Hadoop nie jest zainstalowany, pobierz Hadoop z fundacji oprogramowania Apache.
Instalacja Hadoop
1. Skonfiguruj Hadoop
2. Skonfiguruj Hadoop
Pliki wymagane do edycji w celu skonfigurowania Hadoop to:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Skonfiguruj Namenode za pomocą polecenia:
Hdfs namenode -format
4. Uruchom dfs za pomocą następującego polecenia:
start -dfs.sh
5. Rozpocznij przędzę za pomocą polecenia:
Start -yarn.sh
Jak zainstalować Hive?
Poniżej punkty pomaga zainstalować ula:
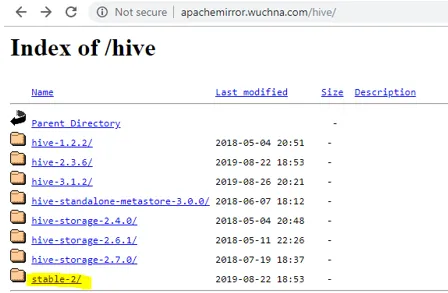
- Pierwszą rzeczą, którą musimy zrobić, jest pobranie wersji ula, którą można wykonać, klikając poniższy link: http://apachemirror.wuchna.com/hive/
- Powyższy link da link, z którego musisz wybrać stable-2 zaznaczone poniżej na żółto:
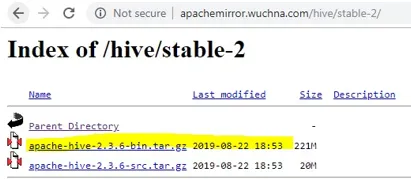
- Po otwarciu stable-2 wybierz plik bin (podświetlony na żółto na zrzucie ekranu) i kliknij prawym przyciskiem myszy i „skopiuj adres linku”.
Kroki, aby zainstalować Hive
Poniżej znajdują się kroki, aby zainstalować ula:
Krok 1: Pobierz plik tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Krok 2: Wyodrębnij plik.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Krok 3: Przenieś pliki apache do katalogu / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Krok 4: Skonfiguruj środowisko Hive, dołączając następujące wiersze do pliku ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Krok 5: Uruchom plik bashrc.
$ source ~/.bashrc
Krok 6: Konfiguracja gałęzi - Edytuj plik hive-env.sh, aby dodać:
export HADOOP_HOME=/usr/local/Hadoop
Krok 7: Edytuj za pomocą poniższych poleceń:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Teraz, aby sprawdzić, czy gałąź jest zainstalowana, czy nie, użyj komendy hive-version.
- Tutaj wersja gałęzi wchodzi do powłoki gałęzi, co oznacza, że ul jest zainstalowany. Jednak w moim przypadku jest to starsza wersja, stąd ostrzeżenie.

Wniosek - instalacja ula
Hive otwiera duże zbiory danych dla wielu osób ze względu na łatwość i charakter podobny do SQL, takiego jak język zapytań i interfejsy. Hive jest zbudowany na rdzeniu Hadoop, ponieważ do wykonania używa Mapreduce. Znacznie łatwe do odzyskania danych i przetwarzania Big Data.
Polecane artykuły
To jest przewodnik po instalacji ula. Tutaj omawiamy niektóre wymagania wstępne dotyczące instalowania gałęzi na dowolnej maszynie oraz sposób instalowania gałęzi w krokach dla lepszego zrozumienia. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej-
- Co to jest ul?
- Polecenia gałęzi
- Jak zainstalować Hive
- Co to jest świnia?