
Różnica między ulem a HBase
Apache Hive i HBase to technologie Big Data oparte na Hadoop. Oboje używali do zapytania danych. Hive i HBase działają na platformie Hadoop i różnią się funkcjonalnością. Hive to dialekt SQL oparty na redukcji map, podczas gdy HBase obsługuje tylko MapReduce. HBase przechowuje dane w postaci par klucz / wartość lub pary rodzin kolumn, podczas gdy Hive nie przechowuje danych.
Różnice między Hive a HBase (infografiki)
Poniżej znajduje się 8 najważniejszych różnic między Hive a HBase
Kluczowe różnice między Hive a HBase
- Hbase jest zgodny z ACID, podczas gdy Hive nie.
- Hive obsługuje kryteria partycjonowania i filtrowania na podstawie formatu daty, podczas gdy HBase obsługuje automatyczne partycjonowanie.
- Hive nie obsługuje instrukcji aktualizacji, a HBase je obsługuje.
- Hbase jest szybszy w porównaniu do Hive w pobieraniu danych.
- Hive służy do przetwarzania danych strukturalnych, podczas gdy HBase, ponieważ nie zawiera schematu, może przetwarzać dowolny rodzaj danych.
- Hbase jest wysoce (poziomo) skalowalny w porównaniu do Hive.
- Hive analizuje dane na HDFS przy pomocy zapytań SQL, a następnie konwertują je na mapę i redukują zadania, podczas gdy w Hbase, ponieważ jest to transmisja w czasie rzeczywistym, bezpośrednio wykonuje operacje na bazie danych, dzieląc na tabele i rodziny kolumn.
- po przejściu do zapytania o gałąź danych używa powłoki znanej jako powłoka Hive do wydawania poleceń, natomiast HBase, ponieważ jest to baza danych, użyjemy polecenia do przetworzenia danych w HBase.
- Aby przejść do powłoki Hive, użyjemy komendy hive. Po podaniu tego będzie wyglądać jak ul>. W HBase podajemy po prostu jako Użyj HBase.
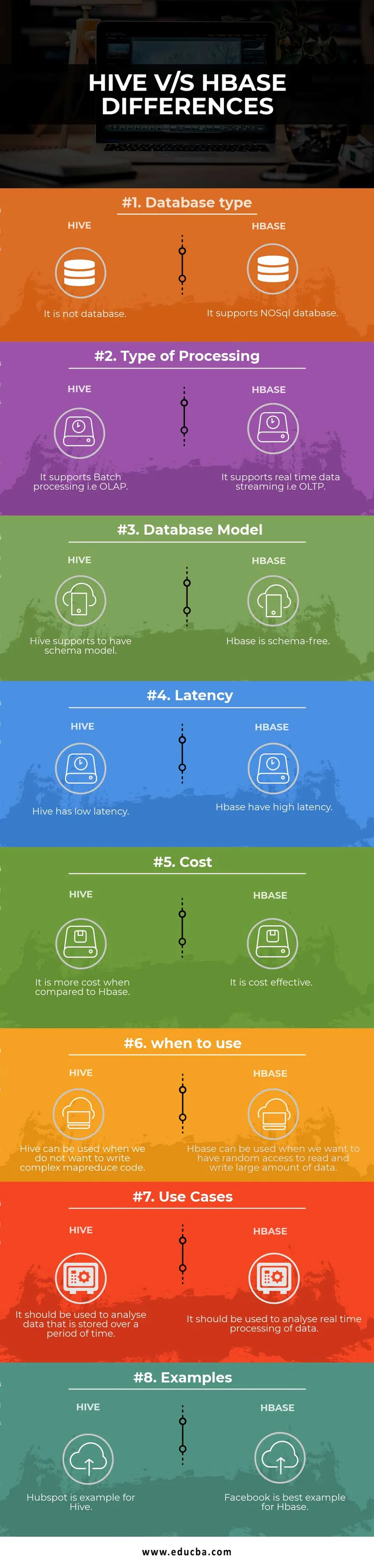
Tabela porównawcza Hive vs. HBase
| Podstawa do porównania | Ul | Hbase |
| Typ bazy danych | To nie jest baza danych | Obsługuje bazę danych NoSQL |
| Rodzaj przetwarzania | Obsługuje przetwarzanie wsadowe, tj. OLAP | Obsługuje przesyłanie danych w czasie rzeczywistym, tj. OLTP |
| Model bazy danych | Hive obsługuje model schematu | Hbase nie zawiera schematu |
| Czas oczekiwania | Ula ma małe opóźnienia | Baza Hbase ma duże opóźnienia |
| Koszt | Jest droższy w porównaniu do HBase | Jest to opłacalne |
| kiedy użyć | Hive może być używany, gdy nie chcemy pisać złożonego kodu MapReduce | Z HBase można korzystać, gdy chcemy mieć losowy dostęp do odczytu i zapisu dużej ilości danych |
| Przypadków użycia | Należy go wykorzystać do analizy danych przechowywanych przez pewien okres czasu | Należy go wykorzystać do analizy przetwarzania danych w czasie rzeczywistym. |
| Przykłady | Hubspot jest przykładem dla gałęzi | Facebook jest najlepszym przykładem dla Hbase |
Różnice w kodowaniu między Hive a HBase
Omówmy teraz podstawowe różnice między Hive a HBase w kodowaniu.
| Podstawa do porównania | Ul | Hbase |
| Aby utworzyć bazę danych | UTWÓRZ BAZY DANYCH (JEŚLI NIE ISTNIEJE) NAZWA BAZY DANYCH; | Ponieważ Hbase jest bazą danych, nie musimy tworzyć konkretnej bazy danych |
| Aby upuścić bazę danych | DROP BAZA DANYCH (JEŚLI ISTNIEJE) NAZWA BAZY DANYCH (OGRANICZENIE LUB KASKADA); | NA |
| Aby utworzyć tabelę | UTWÓRZ (TYMCZASOWY LUB ZEWNĘTRZNY) TABELĘ (JEŚLI NIE ISTNIEJE) NAZWA TABELI ((nazwa-kolumny typ_ danych (komentarz komentarz-kolumny), ….)) (komentarz tabela-komentarz) (FORMAT wiersza FORMAT) (Przechowywany jako format pliku) | STWÓRZ '', '' |
| Aby zmienić stół | ALTER TABLE name RENAME to new-name
ALTER TABLE name DROP (COLUMN) nazwa-kolumny ALTER TABLE name DODAJ KOLUMNY (col-spec (, col-spec ..)) ZMIEŃ TABELĘ nazwa ZMIEŃ kolumna nazwa nowa nazwa nowy typ ALTER TABLE name REPLACE COLUMNS (col-spec (, col-spec ..)) | ALTER „NAZWA TABELI”, NAZWA => „NAZWA KOLUMNY”, WERSJE => |
| Wyłączanie tabeli | NA | wyłącz „TABLE-NAME” ->, aby wyłączyć określoną nazwę tabeli
disable_all 'r *' ->, aby wyłączyć wszystkie tabele, które pasują do wyrażenia regularnego |
| Włączanie tabeli | NA | włącz „TABLE-NAME” |
| Upuścić stół | DROP TABLE, JEŚLI ISTNIEJE nazwa-tabeli | Jeśli chcemy upuścić tabelę, najpierw musimy ją wyłączyć
wyłącz „table-name” upuść „table-name” Podobnie możemy użyć disable_all i drop_all, aby usunąć tabele pasujące do określonego wyrażenia regularnego. |
| Aby wyświetlić listę baz danych | pokaż bazy danych; | NA |
| Aby wyświetlić tabele w bazie danych | pokaż tabele; | lista |
| Aby opisać schemat tabeli | opisać nazwę tabeli; | opisać „table-name” |
Integracja Hive vs HBase
- Zainstaluj i skonfiguruj gałąź.
- Zainstaluj i skonfiguruj HBase.
- Do integracji Hive i HBase używamy STANDAGE HANDLERS w Hive.
- Programy obsługi pamięci to kombinacja SERDE, InputFormat, OutputFormat, która akceptuje dowolny podmiot zewnętrzny jako tabelę w gałęzi.
- Ta funkcja pomaga użytkownikowi w wysyłaniu zapytań SQL, niezależnie od tego, czy tabela znajduje się w Hadoop, czy w bazie danych opartej na NOSQL, takiej jak HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Teraz przyjrzymy się jednemu przykładowi połączenia Hive z HBase przy użyciu HiveStorageHandler:
- Najpierw musimy utworzyć tabelę Hbase za pomocą polecenia.
utwórz „Student”, „personalinfo”, „dept info”
-> Informacje osobiste i informacje o składzie tworzą dwie różne rodziny kolumn w tabeli Uczniów.
- Musimy wstawić niektóre dane do tabeli ucznia, na przykład, jak wspomniano poniżej.
wstaw „student”, „sid01”, „personalinfo: name”, „Ram”
wstaw „student”, „sid01 ′, „ personalinfo: mailid ”, „ ”
wstaw „student”, „sid01”, „deptinfo: deptname”, „Java”
wstaw „Student”, „sid01 ′, „ deptinfo: joinyear ”, „ 1994 ′
-> Podobnie możemy tworzyć dane dla sid02, sid03…
- Teraz musimy utworzyć tabelę Hive wskazującą na tabelę HBase.
- Dla każdej kolumny w Hbase utworzymy jedną konkretną tabelę dla tej kolumny w Hive, w tym przypadku utworzymy 2 tabele w Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Podobnie, musimy utworzyć tabelę szczegółowych informacji o dept w ulu.
- Teraz możemy napisać zapytanie SQL w ulu, jak wspomniano poniżej.
select * from student_hbase;
W ten sposób możemy zintegrować Hive z HBase.
Wniosek - Hive vs. HBase
Jak omówiono, obie są różnymi technologiami, które zapewniają różne funkcje, w których Hive działa przy użyciu języka SQL, i można je również wywołać, ponieważ HQL i HBase używają par klucz-wartość do analizy danych. Hive i HBase działają lepiej, jeśli są połączone, ponieważ Hive ma małe opóźnienia i może przetwarzać ogromną ilość danych, ale nie może utrzymywać aktualnych danych, a HBase nie obsługuje analizy danych, ale obsługuje aktualizacje na poziomie wiersza w dużej ilości danych.
Polecany artykuł
Jest to przewodnik po Hive vs HBase, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Apache Pig vs Hoje Apache - Top 12 przydatnych różnic
- Odkryj 7 najlepszych różnic między Hadoop a HBase
- Top 12 Porównanie Apache Hive vs Apache HBase (infografiki)
- Hadoop vs Hive - Znajdź najlepsze różnice