

Wprowadzenie do poleceń gałęzi
Polecenie Hive to narzędzie infrastruktury hurtowni danych, które znajduje się na szczycie Hadoop w celu podsumowania Big Data. Przetwarza uporządkowane dane. Ułatwia wyszukiwanie i analizowanie danych. Polecenie Hive jest również nazywane „schematem podczas odczytu”. Hive nie weryfikuje danych po ich załadowaniu, weryfikacja następuje tylko po wysłaniu zapytania. Ta właściwość Hive sprawia, że jest szybki do początkowego ładowania. To jak kopiowanie lub po prostu przenoszenie pliku bez nakładania ograniczeń lub kontroli. Ula po raz pierwszy opracował Facebook. Fundacja Apache Software Foundation podjęła ją później i dalej ją rozwijała.
Oto elementy polecenia Hive:
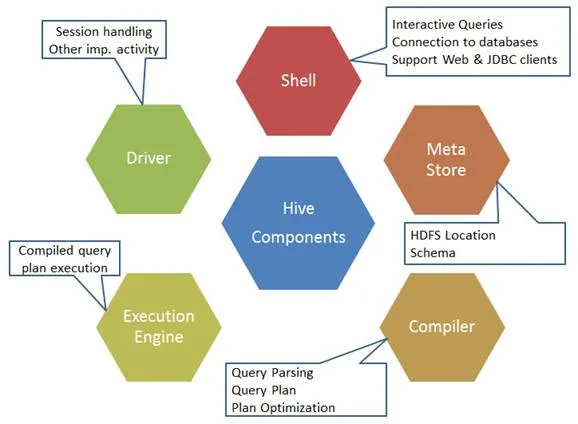
Ryc. 1. Elementy ula
https://www.developer.com/
Oto funkcje komendy Hive wymienione poniżej:
- Sklepy Hive to nieprzetworzony i przetworzony zestaw danych w Hadoop.
- Jest przeznaczony do przetwarzania transakcji OnLine (OLTP). OLTP to systemy, które umożliwiają przesyłanie dużych ilości danych w bardzo krótkim czasie, bez polegania na pojedynczym serwerze.
- Jest szybki, skalowalny i niezawodny.
- Podany tutaj język zapytań typu SQL nazywa się HiveQL lub HQL. Ułatwia to zadania ETL i inne analizy.
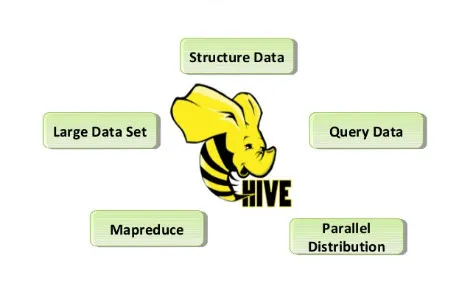
Ryc. 2. Właściwości ula
Źródła zdjęć: - Google
Istnieje również kilka ograniczeń polecenia Hive, które są wymienione poniżej:
- Hive nie obsługuje podkwerend.
- Hive z pewnością obsługuje nadpisywanie, ale niestety nie obsługuje usuwania i aktualizacji.
- Hive nie jest przeznaczony dla OLTP, ale jest do niego używany.
Aby wejść do interaktywnej powłoki ula:
$ HIVE_HOME / bin / hive
Podstawowe komendy gałęzi
-
Stwórz
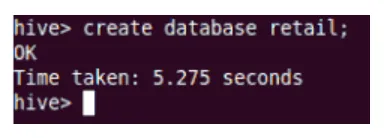
Spowoduje to utworzenie nowej bazy danych w gałęzi.
-
Upuszczać
Upuszczenie usunie tabelę z gałęzi
-
Zmieniać
Polecenie Alter pomoże zmienić nazwę tabeli lub kolumn tabeli.
Na przykład:
ula> ZMIEŃ TABELĘ pracownik ZMIEŃ NAZWĘ NA pracownik1;
-
Pokazać
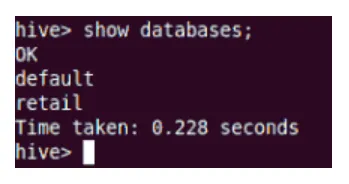
Polecenie pokaż spowoduje wyświetlenie wszystkich baz danych znajdujących się w gałęzi.
-
Opisać
Polecenie opisywania pomoże ci uzyskać informacje o schemacie tabeli.
Pośrednie komendy gałęzi
Hive dzieli tabelę na różne pokrewne partycje na podstawie kolumn. Korzystanie z tych partycji ułatwia wyszukiwanie danych. Te partycje są dalej dzielone na segmenty, aby efektywnie uruchamiać zapytania na danych.
Innymi słowy, segmenty dystrybuują dane do zestawu klastrów, obliczając kod skrótu klucza wymienionego w zapytaniu.
-
Dodawanie partycji
Dodawanie partycji można wykonać, zmieniając tabelę. Załóżmy, że masz tabelę „EMP” z polami takimi jak Id, Imię, Wynagrodzenie, Dział, Oznaczenie i yoj.
ula> pracownik ALTER TABLE
> DODAJ PARTYCJĘ (rok = „2012”)
lokalizacja „/ 2012 / part2012”;
-
Zmiana nazwy partycji
ul> STRONA STANOWISKA ALTER TABELI (rok = „1203”)
ZMIEN NA PARTYCJĘ (Yoj = „1203”);
-
Upuść partycję
ul> ZMIEŃ TABELĘ pracownik UPADEK
> PARTITION (rok = „1203”);
-
Operatorzy relacyjni
Operatory relacyjne składają się z pewnego zestawu operatorów, który pomaga w pobieraniu odpowiednich informacji.
Na przykład: Powiedzmy, że tabela „EMP” wygląda następująco:
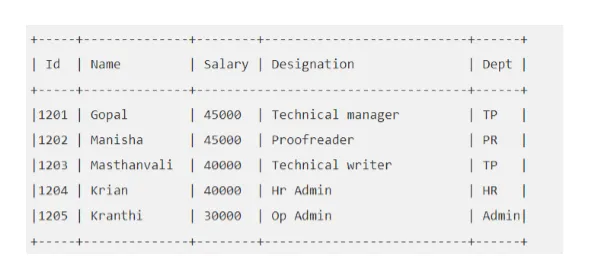
Wykonajmy zapytanie Hive, które przyniesie nam pracownika, którego wynagrodzenie jest wyższe niż 30000.
ul> WYBIERZ * Z EMP GDZIE Wynagrodzenie> = 40000;
-
Operatory arytmetyczne
Są to operatory, które pomagają w wykonywaniu operacji arytmetycznych na operandach, a te z kolei zawsze zwracają typy liczb.
Na przykład: Aby dodać dwa numery, takie jak 22 i 33
ul> WYBIERZ 22 + 33 DODAJ OD temp;
-
Operator logiczny
Operatorzy ci mają wykonywać operacje logiczne, które w zamian zawsze zwracają wartość Prawda / Fałsz.
ul> WYBIERZ * Z EMP GDZIE Wynagrodzenie> 40000 && Dept = TP;
Zaawansowane komendy gałęzi
-
Widok
Pojęcie widoku w gałęzi jest podobne jak w SQL. Widok można utworzyć podczas wykonywania instrukcji SELECT.
Przykład:
ula> UTWÓRZ WIDOK EMP_30000 AS
WYBIERZ * Z EMP
GDZIE wynagrodzenie> 30000;
-
Ładowanie danych do tabeli
Hive> Załaduj lokalną ścieżkę danych „/home/hduser/Desktop/AllStates.csv” do stanów tabeli;
Tutaj „Stany” to już utworzona tabela w gałęzi.
https://www.tutorialspoint.com/hive/
Hive ma kilka wbudowanych funkcji, które pomagają w lepszym uzyskaniu wyniku.
Jak okrągły, podłogowy, BIGINT itp.
-
Przystąp
Klauzula Join może pomóc w połączeniu dwóch tabel opartych na tej samej nazwie kolumny.
Przykład:
ula> WYBIERZ c.ID, c.NAME, c.AGE, o.AMOUNT
OD KLIENTÓW c DOŁĄCZ DO ZAMÓWIEŃ o
ON (c.ID = o.CUSTOMER_ID);
Wszystkie rodzaje złączeń są obsługiwane przez Hive: lewe łączenie zewnętrzne, prawe łączenie zewnętrzne, pełne łączenie zewnętrzne.
Wskazówki i porady dotyczące używania poleceń gałęzi
Hive sprawia, że przetwarzanie danych jest tak łatwe, proste i rozszerzalne, że użytkownik nie zwraca uwagi na optymalizację zapytań Hive. Ale zwracanie uwagi na kilka rzeczy podczas pisania zapytania Hive z pewnością przyniesie wielki sukces w zarządzaniu obciążeniem i oszczędności. Poniżej znajduje się kilka wskazówek na ten temat:
- Partycje i segmenty: Hive to narzędzie do dużych zbiorów danych, które może wyszukiwać duże zbiory danych. Jednak pisanie zapytania bez zrozumienia domeny może przynieść świetne partycje w gałęzi.
Jeśli użytkownik jest świadomy zestawu danych, odpowiednie i najczęściej używane kolumny można zgrupować w tej samej partycji. Pomoże to w szybszym i nieefektywnym uruchomieniu zapytania.
Ostatecznie nie. operacji mapowania i operacji we / wy również zostanie zmniejszonych.
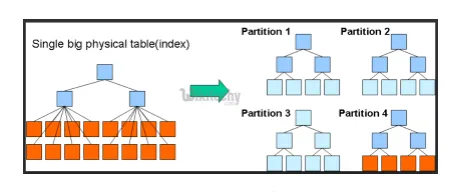
Ryc. 3. Partycjonowanie
Źródła obrazów: obraz Google
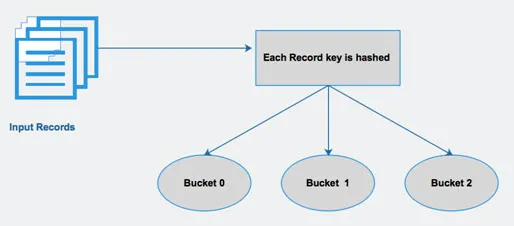
Ryc. 4 Wiadro
Źródła obrazów: - Obraz Google
- Równoległe wykonywanie: Hive uruchamia zapytanie w wielu etapach. W niektórych przypadkach etapy te mogą zależeć od innych etapów, dlatego nie można rozpocząć, po zakończeniu poprzedniego etapu. Niezależne zadania można jednak uruchamiać równolegle, aby zaoszczędzić ogólny czas działania. Aby włączyć równoległe uruchamianie w gałęzi:
ustaw hive.exec.parallel = true;
W ten sposób zwiększy to wykorzystanie klastra.
- Blokuj próbkowanie: Próbkowanie danych z tabeli pozwoli na wyszukiwanie zapytań dotyczących danych.
Mimo braku danych chcemy raczej losowo próbkować zestaw danych. Próbkowanie blokowe ma różną mocną składnię, która pomaga w próbkowaniu danych na różne sposoby.
Próbkowanie można wykorzystać do znalezienia ok. informacje z zestawu danych, takie jak średnia odległość między miejscem początkowym a docelowym.
Zapytanie o 1% dużych zbiorów danych da prawie idealną odpowiedź. Eksploracja staje się łatwiejsza i skuteczniejsza.
Wniosek - polecenia gałęzi
Hive to abstrakcja wyższego poziomu na HDFS, która zapewnia elastyczny język zapytań. Pomaga w łatwiejszym wyszukiwaniu i przetwarzaniu danych.
Hive można łączyć z innymi elementami Big Data, aby w pełni wykorzystać jego funkcjonalność.
Polecane artykuły
To był przewodnik po poleceniach gałęzi. Omówiliśmy tutaj zarówno podstawowe, jak i zaawansowane polecenia Hive oraz niektóre natychmiastowe polecenia Hive. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Hive Pytania podczas wywiadu
- Hive VS Hue - Top 6 przydatnych porównań
- Polecenia Tableau
- Polecenia Adobe Photoshop
- Używanie funkcji ORDER BY w gałęzi
- Pobierz i zainstaluj Hive krok po kroku